 I love drawing up lists and rankings of players (who doesn’t?) and giving myself a big “confirmation bias” pat on the back when I see players on the list which I like while casually either ignoring as a mistake of the method or updating my bias for the players on the list which I don’t particularly rate highly. However, the very exercise of drawing up lists and rankings can be misleading for the probabilistically-illiterate because it seems to imply set-in-stone certainty about who the best player is, who the second best is, etc.; and this rigid numbering masks the underlying concepts of probability. And yet, drawing up player lists is key for the recruitment workflows of clubs, be it in drafts or transfer windows, or even just to set up a schedule for their scouts. You definitely don’t have to see the rankings as set in stone, but I can imagine clubs would definitely want to have things like 15-men shortlists with 2 or 3 ‘favourite choices’. In this entry I’m going to show you a couple of lists I drew up and how we can go about our list-making with confidence with vectorised representations of players. I drew up lists for this entry using the player passing motif ideas from previous entries. The passing motif methodology produces a vectorised representation of players, which basically means that each player is represented by a vector of numbers. In the passing motif methodology I’ve used so far, the vector representing each player has 45 entries or numbers. The key conceptual bit is that when you have this type of vectorised representation, you can imagine each player as being in a “space” of some sort. To imagine it, suppose that instead of 45 you simply had 3 numbers representing each player, something like age, height and weight. If this was the case, you could imagine each player as being represented by a dot in a 3-dimensional space much like your living room. Some players would be closer to others, some would be farther away. Perhaps all the senior, tall and heavy centre-backs are located around your TV, while the shorter and lighter second strikers are hovering around your dining room table. This is just how I conceptualise the result of the 45-dimensional passing motif methodology. It makes it more abstract to picture, but just as in the 3-dimensional case, there are distances, certain dots closer to each other or concentrated around certain areas, etc. The list I drew up basically took all the players who had at least 18 appearances in last year’s Premier League, and gave them “points” according to how many key passes they made AND how many key passes the players around them made. The closer to a player you are, the more “points” his amount of key passes awards you; the farther away the less. I tried this out in a few ways but that’s the basic idea. The idea is that if you happened to make few key passes in the season but all the players whose motif vector is close to yours made a lot, you should still have a high score. If the information contained in the motif vectorisation is at all useful to recognise players with creative potential, then the best scored players should in a way be the best creative passers in a more profound way than simply looking at the Key Passes Table. The question is precisely, how do we know the vectorisation’s layout of players has anything to do with their “key passing ability” (i.e., players with high ability cluster around certain areas of this “space” and are in general closer to each other)? Let’s look at the list before we begin to answer this question so everybody gets a bit excited before it dawns on them that I’m actually rambling on about some technical stuff.
I love drawing up lists and rankings of players (who doesn’t?) and giving myself a big “confirmation bias” pat on the back when I see players on the list which I like while casually either ignoring as a mistake of the method or updating my bias for the players on the list which I don’t particularly rate highly. However, the very exercise of drawing up lists and rankings can be misleading for the probabilistically-illiterate because it seems to imply set-in-stone certainty about who the best player is, who the second best is, etc.; and this rigid numbering masks the underlying concepts of probability. And yet, drawing up player lists is key for the recruitment workflows of clubs, be it in drafts or transfer windows, or even just to set up a schedule for their scouts. You definitely don’t have to see the rankings as set in stone, but I can imagine clubs would definitely want to have things like 15-men shortlists with 2 or 3 ‘favourite choices’. In this entry I’m going to show you a couple of lists I drew up and how we can go about our list-making with confidence with vectorised representations of players. I drew up lists for this entry using the player passing motif ideas from previous entries. The passing motif methodology produces a vectorised representation of players, which basically means that each player is represented by a vector of numbers. In the passing motif methodology I’ve used so far, the vector representing each player has 45 entries or numbers. The key conceptual bit is that when you have this type of vectorised representation, you can imagine each player as being in a “space” of some sort. To imagine it, suppose that instead of 45 you simply had 3 numbers representing each player, something like age, height and weight. If this was the case, you could imagine each player as being represented by a dot in a 3-dimensional space much like your living room. Some players would be closer to others, some would be farther away. Perhaps all the senior, tall and heavy centre-backs are located around your TV, while the shorter and lighter second strikers are hovering around your dining room table. This is just how I conceptualise the result of the 45-dimensional passing motif methodology. It makes it more abstract to picture, but just as in the 3-dimensional case, there are distances, certain dots closer to each other or concentrated around certain areas, etc. The list I drew up basically took all the players who had at least 18 appearances in last year’s Premier League, and gave them “points” according to how many key passes they made AND how many key passes the players around them made. The closer to a player you are, the more “points” his amount of key passes awards you; the farther away the less. I tried this out in a few ways but that’s the basic idea. The idea is that if you happened to make few key passes in the season but all the players whose motif vector is close to yours made a lot, you should still have a high score. If the information contained in the motif vectorisation is at all useful to recognise players with creative potential, then the best scored players should in a way be the best creative passers in a more profound way than simply looking at the Key Passes Table. The question is precisely, how do we know the vectorisation’s layout of players has anything to do with their “key passing ability” (i.e., players with high ability cluster around certain areas of this “space” and are in general closer to each other)? Let’s look at the list before we begin to answer this question so everybody gets a bit excited before it dawns on them that I’m actually rambling on about some technical stuff. 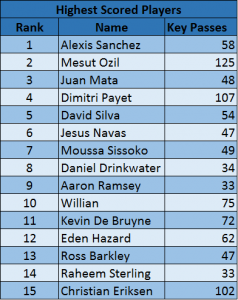 Remark: Notice how this list isn’t strictly correlated with key passes. Drinkwater is better ranked than Eriksen even though the latter had many more key passes. This means that if the list is sound (big if), its picking up on information that wasn’t immediately and explicitly available in the key passes tables. My confirmation bias seems to like that list quite a lot, there are a lot of good names up there. Most readers probably follow the Premier League closely and know that those are all good attacking creative players, arguably the best in the league. Now imagine that instead of the Premier League, we drew up an equivalent list using data from leagues where we didn’t already know the players, and had confidence that just as in the case of the Premier League, we were definitely getting out a list of most of the best players. Should be useful huh? There are also some notable absentees. Coutinho comes to mind as a player which is widely agreed to be amongst the best in the league who isn’t on the list. Why should we trust a list that claims to rank the top 15 creative players in the league but leaves out Coutinho? As I said before, I think of the vectorised representation as encoding the information regarding players’ key passing ability if players who tend to have a higher number of key passes are more or less clustered together as opposed to randomly located mixed with all the other players. If this is a general trend, then we know that there is a relationship between a player’s key passing ability and his location in the 45-dimensional space we are imagining. Even if a player happened to not have many key passes in a season (this can happen just as strikers have goal droughts or perhaps because a player’s teammates don’t make good runs), we should still pick up on this “ability”. What we would need then to justify our faith in the list is some sort of indicator which specified just how “clustered together” players with higher number of key passes are. There are many ways to approach this problem in mathematics. For those readers who have mathematical backgrounds we could try to fit a model and asses the goodness of fit, or apply some sort of multi-dimensional Kolmogorov-Smirnov technique comparing the actual distribution of vectors and key passes with one where the key passes where distributed randomly. However, all these tests are a bit technical and hard to apply in high dimensions, and all in all we really want an indicator more than a model of “Expected Key Passes”. Here’s a simpler validating technique: For each player, take his K (in mi list K=10) closest neighbours and compute the standard deviation of their key passes. Once we’ve done this for every player, we can compute the mean of the standard deviation of key passes in each of these K-player “neighbourhoods” (let’s call it the ‘mean of neighbourhoods’ variation number=MNV’). If in each neighbourhood the players have a relatively similar number of key passes, then the MNV should be comparatively low. The important question is: what do we compare it to in order to know if its low or not? I feel that there are two important numbers to compare this number to. The first would be simulating many (many) scenarios where the key passes are randomly permutated amongst the players and comparing the real MNV number to the average of these simulated cases. The second number would be the minimum MNV of any of the simulated scenarios. If the MNV of our actual vectorised representation is “low” in comparison to these simulated scenarios, then we know that the players’ layout in this imaginary 45-dimensional space clusters the key passers of the ball closer together than random distributions; which in turn would mean that the logic applied to obtain the list has a robust underlying reasoning because a player’s location in the 45-dimensional space should have something to do with his “key passing ability” (I fear I may have lost half the readers by this point…). Here are some results:
Remark: Notice how this list isn’t strictly correlated with key passes. Drinkwater is better ranked than Eriksen even though the latter had many more key passes. This means that if the list is sound (big if), its picking up on information that wasn’t immediately and explicitly available in the key passes tables. My confirmation bias seems to like that list quite a lot, there are a lot of good names up there. Most readers probably follow the Premier League closely and know that those are all good attacking creative players, arguably the best in the league. Now imagine that instead of the Premier League, we drew up an equivalent list using data from leagues where we didn’t already know the players, and had confidence that just as in the case of the Premier League, we were definitely getting out a list of most of the best players. Should be useful huh? There are also some notable absentees. Coutinho comes to mind as a player which is widely agreed to be amongst the best in the league who isn’t on the list. Why should we trust a list that claims to rank the top 15 creative players in the league but leaves out Coutinho? As I said before, I think of the vectorised representation as encoding the information regarding players’ key passing ability if players who tend to have a higher number of key passes are more or less clustered together as opposed to randomly located mixed with all the other players. If this is a general trend, then we know that there is a relationship between a player’s key passing ability and his location in the 45-dimensional space we are imagining. Even if a player happened to not have many key passes in a season (this can happen just as strikers have goal droughts or perhaps because a player’s teammates don’t make good runs), we should still pick up on this “ability”. What we would need then to justify our faith in the list is some sort of indicator which specified just how “clustered together” players with higher number of key passes are. There are many ways to approach this problem in mathematics. For those readers who have mathematical backgrounds we could try to fit a model and asses the goodness of fit, or apply some sort of multi-dimensional Kolmogorov-Smirnov technique comparing the actual distribution of vectors and key passes with one where the key passes where distributed randomly. However, all these tests are a bit technical and hard to apply in high dimensions, and all in all we really want an indicator more than a model of “Expected Key Passes”. Here’s a simpler validating technique: For each player, take his K (in mi list K=10) closest neighbours and compute the standard deviation of their key passes. Once we’ve done this for every player, we can compute the mean of the standard deviation of key passes in each of these K-player “neighbourhoods” (let’s call it the ‘mean of neighbourhoods’ variation number=MNV’). If in each neighbourhood the players have a relatively similar number of key passes, then the MNV should be comparatively low. The important question is: what do we compare it to in order to know if its low or not? I feel that there are two important numbers to compare this number to. The first would be simulating many (many) scenarios where the key passes are randomly permutated amongst the players and comparing the real MNV number to the average of these simulated cases. The second number would be the minimum MNV of any of the simulated scenarios. If the MNV of our actual vectorised representation is “low” in comparison to these simulated scenarios, then we know that the players’ layout in this imaginary 45-dimensional space clusters the key passers of the ball closer together than random distributions; which in turn would mean that the logic applied to obtain the list has a robust underlying reasoning because a player’s location in the 45-dimensional space should have something to do with his “key passing ability” (I fear I may have lost half the readers by this point…). Here are some results: ![]() Of the 100,000 simulations, the lowest MNV was 14.62 while the actual MNV is 11.86. This means that if we randomly assigned the players to a position in the 45-dimensional space 100,000 times, none of those simulations has the key passers clustered together better than our actual passing motif representation. This is quite promising, but even then, I suspected that maybe this is because the method clearly recognises the difference between defensive players and attacking players and attacking players are much more likely to get more key passes; so I repeated the validation using only attacking midfielders, wingers and strikers:
Of the 100,000 simulations, the lowest MNV was 14.62 while the actual MNV is 11.86. This means that if we randomly assigned the players to a position in the 45-dimensional space 100,000 times, none of those simulations has the key passers clustered together better than our actual passing motif representation. This is quite promising, but even then, I suspected that maybe this is because the method clearly recognises the difference between defensive players and attacking players and attacking players are much more likely to get more key passes; so I repeated the validation using only attacking midfielders, wingers and strikers:  The results are less overwhelmingly positive, but even when just looking at attacking players, the actual layout surpasses any random distributions of the players after 100,000 simulations. To appreciate the value of this method and what information this is actually giving us, let’s compare with an equivalent list drawn up using ‘goals’ to award points rather than ‘key passes’ (using only attacking players again for the same reason as before).
The results are less overwhelmingly positive, but even when just looking at attacking players, the actual layout surpasses any random distributions of the players after 100,000 simulations. To appreciate the value of this method and what information this is actually giving us, let’s compare with an equivalent list drawn up using ‘goals’ to award points rather than ‘key passes’ (using only attacking players again for the same reason as before). 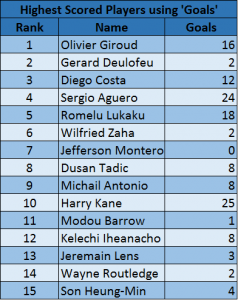
 The MNV numbers are naturally smaller because players score much less goals per season than key passes, so the overall scale of the problem is smaller. We can see that even though the real MNV is smaller than the average of the simulations, its actually relatively large when compared to the minimum MNV obtained through random simulations (notice how important it is to have a frame of reference to know when the number is small and when it is large in each specific context). This means that the position of players and goals in the 45-dimensional space can be clustered together through random simulations considerably better than using the passing motif vectorised representation. As opposed to the ‘key passes’ case, this vectorisation doesn’t encode much information pertaining to “goalscoring capability”. This actually makes sense though since the passing motif methodology is designed using only information from the passing network which doesn’t necessarily contain information regarding finishing. Therefore, the list made using ‘goals’ is much less reliable. Coming back to Coutinho’s absence from the original list, it’s important to understand that I’m not claiming the list as a know-it-all oracle for creative talent and that this talent can be rigidly ordered. What this entry tried to show is that there is solid evidence that a player’s position in the 45-dimensional space determined by the passing motif methodology encodes a good amount of information which determines how many key passes he ought to have given a sort of “passing ability”. That doesn’t mean it encodes all the information. Perhaps the vectorised representation is missing out on what it is that makes Coutinho great. Nevertheless, once we’ve accepted and understood that the list will offer us, I doubt any club could claim that a list like this from different leagues from around the world is of no use to their organisation just because they might miss out on the Serbian League’s Coutinho (sadly, such is the ‘glass half empty’ prejudice that analytics face). Finally, this way of looking at the problem of rating players opens the door to a host of possibilities. When I was doing my bachelor in pure mathematics I was actually more interested in differential geometry and topology courses than statistics courses, which is why I tend to think of data observations as vectors in high-dimensional spaces and think that their positions in those spaces encodes valuable information. This entry began by taking a vectorised representation (passing motifs vectors) and established that if we look at the number of key passes each player made, the players’ vectors’ position in this space seemed to encode this info. On the other hand, it didn’t seem to encode the information pertaining to goalscoring. That isn’t to say it might not encode information regarding other metrics. Expected Assists maybe? It also doesn’t mean that other vector representations don’t encode some of this information better than my own passing motifs representation. It’s a bit of a 3 step thing really: 1. Find a vector representation, 2. Check what sort of information it seems to encode well (especially information that isn’t explicitly available elsewhere), and 3. Find a way to give players a rating using this fact. I hope this way of thinking encourages other analysts out there to try their hand at this sort of work!
The MNV numbers are naturally smaller because players score much less goals per season than key passes, so the overall scale of the problem is smaller. We can see that even though the real MNV is smaller than the average of the simulations, its actually relatively large when compared to the minimum MNV obtained through random simulations (notice how important it is to have a frame of reference to know when the number is small and when it is large in each specific context). This means that the position of players and goals in the 45-dimensional space can be clustered together through random simulations considerably better than using the passing motif vectorised representation. As opposed to the ‘key passes’ case, this vectorisation doesn’t encode much information pertaining to “goalscoring capability”. This actually makes sense though since the passing motif methodology is designed using only information from the passing network which doesn’t necessarily contain information regarding finishing. Therefore, the list made using ‘goals’ is much less reliable. Coming back to Coutinho’s absence from the original list, it’s important to understand that I’m not claiming the list as a know-it-all oracle for creative talent and that this talent can be rigidly ordered. What this entry tried to show is that there is solid evidence that a player’s position in the 45-dimensional space determined by the passing motif methodology encodes a good amount of information which determines how many key passes he ought to have given a sort of “passing ability”. That doesn’t mean it encodes all the information. Perhaps the vectorised representation is missing out on what it is that makes Coutinho great. Nevertheless, once we’ve accepted and understood that the list will offer us, I doubt any club could claim that a list like this from different leagues from around the world is of no use to their organisation just because they might miss out on the Serbian League’s Coutinho (sadly, such is the ‘glass half empty’ prejudice that analytics face). Finally, this way of looking at the problem of rating players opens the door to a host of possibilities. When I was doing my bachelor in pure mathematics I was actually more interested in differential geometry and topology courses than statistics courses, which is why I tend to think of data observations as vectors in high-dimensional spaces and think that their positions in those spaces encodes valuable information. This entry began by taking a vectorised representation (passing motifs vectors) and established that if we look at the number of key passes each player made, the players’ vectors’ position in this space seemed to encode this info. On the other hand, it didn’t seem to encode the information pertaining to goalscoring. That isn’t to say it might not encode information regarding other metrics. Expected Assists maybe? It also doesn’t mean that other vector representations don’t encode some of this information better than my own passing motifs representation. It’s a bit of a 3 step thing really: 1. Find a vector representation, 2. Check what sort of information it seems to encode well (especially information that isn’t explicitly available elsewhere), and 3. Find a way to give players a rating using this fact. I hope this way of thinking encourages other analysts out there to try their hand at this sort of work!
2017
Player Vectorised Representations: What player lists can we draw up with confidence?
By admin
|
January 16, 2017