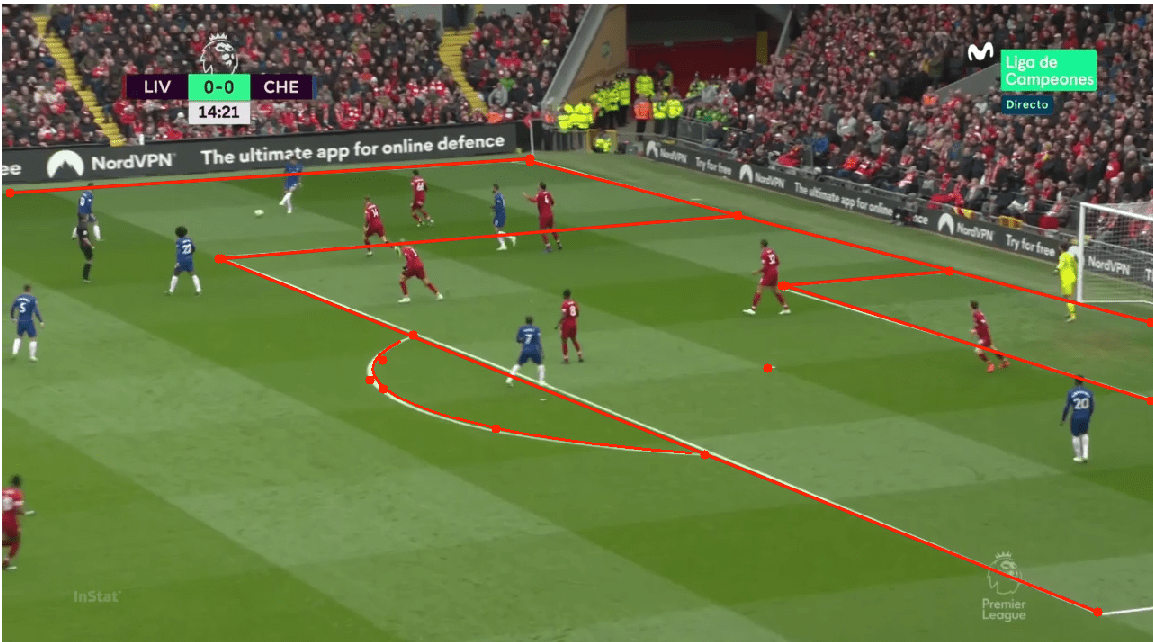
This article is written by the CV team at StatsBomb. In it, we will cover the technical details of the camera calibration algorithm that we have developed to collect the location of players directly from televised footage
Introduction
Camera calibration is a fundamental step for multiple computer vision applications in the field of sports analytics. By determining the camera pose one can accurately locate both players and events in the game at any time point. Furthermore, increasing the accuracy of the camera calibration will in turn increase the accuracy of any advanced metric derived from the collected data.
One of the applications where camera calibration is essential is player tracking. In order to tackle this problem some companies have developed a multi-camera system that records the entire football pitch. This approach has the clear advantage of allowing for accurate location of all the players in the field. However, the deployment and maintenance of these systems can be quite expensive and its applicability is limited to stadiums where the customized cameras were installed, thus requiring specific agreements with clubs.
An alternative, much more scalable, approach consists of collecting data from broadcast video, which is widely available. However, from a technical point of view this is a much more challenging problem since we cannot rely on stationary cameras. Instead, it is necessary to perform a registration between the playing surface in the video and a template model.
In the remainder of this document we present how StatsBomb is approaching the problem of camera calibration from broadcast video. We describe the methodology we are following and the results that we’ve had.
Data Preparation
Our objective is to fully automate the camera calibration. For that purpose, we have deployed a system to collect data from which we can create a training dataset composed of frames at different locations and their ground-truth camera pose. The aim is to collect a wide range of camera poses that cover all locations within the pitch. This has been achieved through the following steps:
(1). Mechanical Turk
In order to rapidly collect data to train our models, we have created a platform that allows us to manually label pitch markings from multiple pitch locations. Camera calibration usually relies only on paired points between the images to register, requiring a minimum of four pairs of points. The corners of the penalty box are examples of easily recognizable points. However, depending on the camera angle, there might not be enough recognizable points present in the frame to retrieve the camera pose. In order to overcome this limitation, the application we have developed allows our collection team to manually outline and label all pitch lines present in the frame.

Figure 1. Four different camera angles covering different locations of the pitch. The labelled information marked by our collection team is displayed, including straight lines, circles, and special keypoints, such as the penalty spot. You can see that the labels are not perfect, but don’t worry since this will be fixed in the next step. Also, this data is just for training our machine learning models, and any imperfections here will not impact the quality of the data we give to customers.
(2) Homography estimation from manually labelled data
In projective geometry, a homography is defined as a transformation between two images of the same planar surface (1). Assuming the cameras used to record football games are well characterized by the camera-pinhole model, retrieving the camera pose is equivalent to determining the homography between the observed pitch within the frame and a template. Mathematically, the homography is described by a 3x3 matrix:
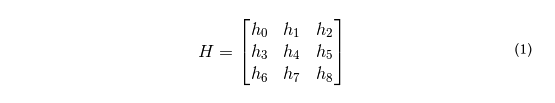
Luckily, although matrix H has 9 elements, there are only 8 degrees of freedom, and we make some assumptions about the camera to reduce the number of degrees of freedom even further. Then, we use our labelled data to estimate the homography for each image.
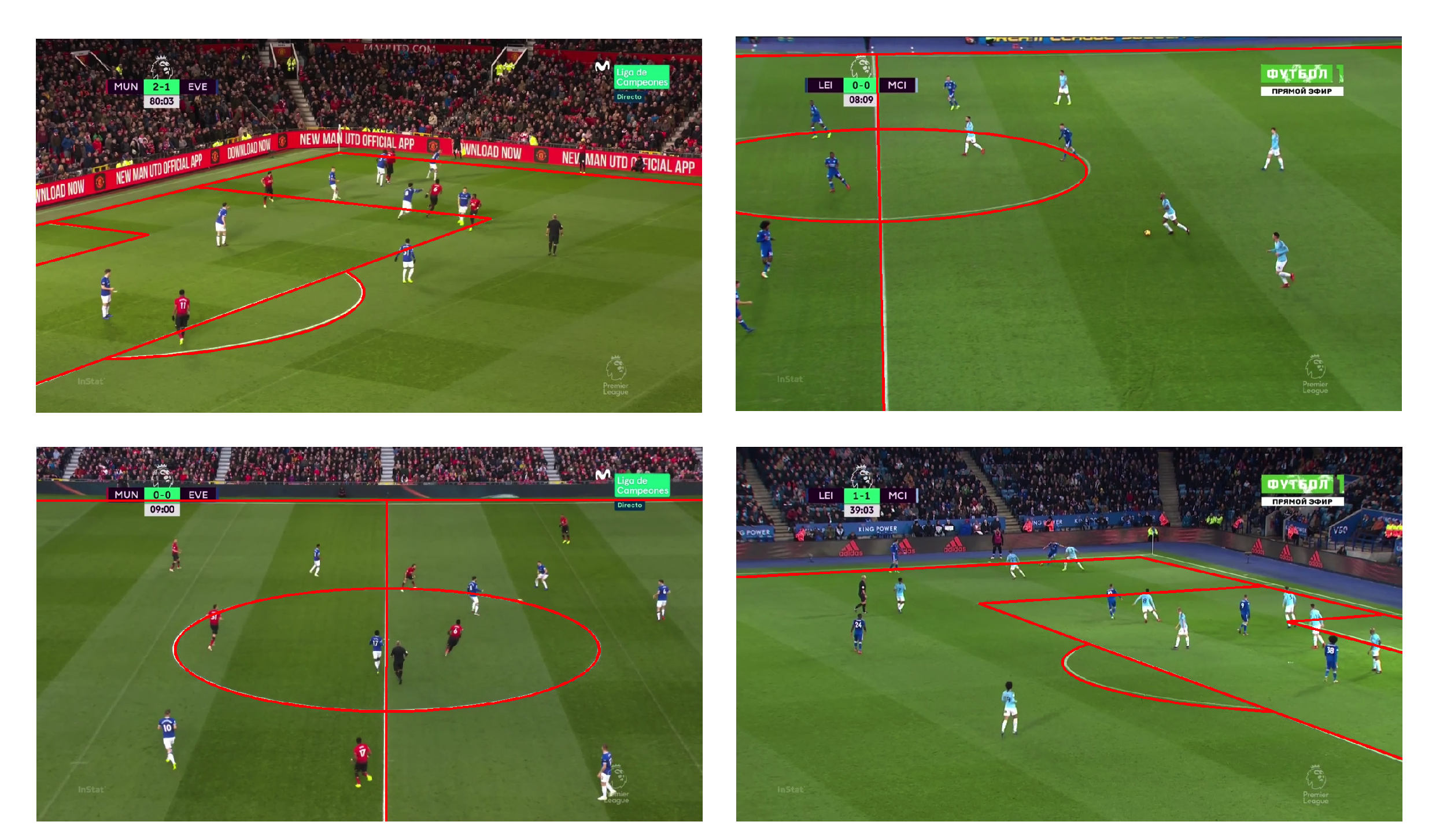
Figure 2. Four different camera angles covering different locations of the pitch. The projected pitch template using the estimated homography is displayed. These images and lines may look nearly identical to figure 1, but they come from the computer understanding where the camera is relative to the field, rather than just lines drawn on an image. Note that the slight imperfections in the types of images from figure 1 have been corrected after this stage.
Camera Calibration
Having the aforementioned data, we can now use supervised learning techniques to train a model that allows us to retrieve the camera pose from a given frame. The model we use is based on a ResNet architecture (2) that is often used for recognizing objects in images. However, it is necessary to train the network to find football pitches instead of dogs and cats. We do this using back-propagation and the Adam optimizer (3).
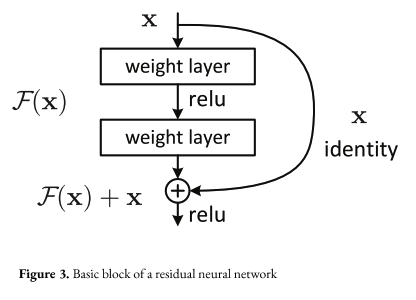

Figure 4. Sample of the camera calibration method developed at StatsBomb. The pitch template is projected in red using the estimated camera pose.
Conclusions
Thus far we have only deployed our model for shots. We have focused on shots to continue improving the quality of the data that goes into our xG model. By more accurately locating the shooter as well as the goalkeeper, defenders, and other attackers, we continue to have the best data in the industry. By the start of next season we will have rolled out a model to accurately calibrate the camera for all events. This could unlock the ability to have freeze frames for all events, player tracking, and more. The timeline for these features is still in progress and is dependent on customer demand, so let us know what you’re interested in! In this report we have presented how we have tackled the problem of camera calibration at StatsBomb, providing details about our approaches to both data collection and model training. We continue to explore ideas aiming at expanding the scope of our models and improving the current results.
References
(1) Hartley and Zisserman, “Multiple View Geometry in Computer Vision”, 2003, Cambridge.
(2) He et. al., “Deep residual learning for image recognition”, 2015, arXiv: https://arxiv.org/abs/1512.03385.
(3) Kingma et. al., “Adam: A Method for stochastic optimization”, 2017, arXiv: https://arxiv.org/pdf/1412.6980.pdf.