
En StatsBomb, estamos comprometidos a impulsar el desarrollo de la próxima generación de analistas e investigadores de datos. Habitualmente publicamos datos de diversas competiciones de manera gratuita y también ofrecemos paquetes para los lenguajes de programación más utilizados para hacer más fácil la manipulación de dichos datos.
Hace tiempo escribimos un artículo que funciona como una introducción al uso de nuestros datos con R, pero hacía falta una guía así para Python. En abril de 2023, hicimos un taller online llamado Aprende a analizar datos de fútbol con Python y con la cantidad de feedback positivo que recibimos, decidimos utilizar lo impartido en el taller para escribir una introducción a la utilización de los datos de StatsBomb en Python.
¿Qué es Python y por qué usarlo?
Python es uno de los lenguajes de programación más populares, ampliamente utilizado en diversos ámbitos como la inteligencia artificial, la ciencia de datos o el desarrollo de aplicaciones web, entre otros.
Como es el caso de todos los lenguajes de programación, existe una curva de aprendizaje pero una vez superada se abren muchas posibilidades a la hora de manipular, analizar y visualizar conjuntos de datos muy grandes, lo que le hace un lenguaje perfecto para el análisis de datos de evento de fútbol u otros deportes.
¿Qué es un entorno de desarrollo?
Un entorno de desarrollo es un conjunto de herramientas y utilidades que se utilizan para desarrollar, depurar y ejecutar código.
Aunque es posible ejecutar código de Python sin utilizar un entorno de desarrollo, es muy aconsejable utilizar uno de los varios entornos que existen para disponer de una interfaz gráfica y fácil de manejar.
Entre las opciones más populares se encuentran Google Colab, Jupyter Notebook y Spyder. En los ejemplos de este artículo utilizaremos Google Colab, pero cualquier de los entornos mencionados y muchos de los otros que existen también te serviría para trabajar con nuestros datos.
¿Qué es un paquete de Python?
Los paquetes son conjuntos de funciones que simplifican tareas. Se pueden instalar fácilmente ejecutando: pip install [nombre del paquete]
Para trabajar con los datos de StatsBomb, hay dos paquetes casi imprescindibles:
- StatsBombPy: un paquete nuestro desarrollado por Francisco Goitia, Lead Machine Learning Engineer en StatsBomb, que hace más fácil la importación y manipulación de nuestros datos (pip install statsbombpy)
- mplsoccer: un paquete desarrollado por Andy Rowlinson que hace más fácil la creación de un campo de fútbol en Python y que también ofrece otras herramientas para la visualización de datos deportivos (pip install mplsoccer)
Asimismo, utilizamos mucho el paquete highlight_text (pip install highlight_text) en la creación de gráficas y otras visualizaciones.
La importación, manipulación y visualización de los datos de StatsBomb
Con los paquetes mencionados anteriormente ya instalados, podemos importarlos a nuestra sesión de Python para empezar a trabajar con los datos.
Ejecutamos el siguiente código:
from statsbombpy import sb
import pandas as pd
from mplsoccer import VerticalPitch,Pitch
from highlight_text import ax_text, fig_text
from matplotlib.colors import LinearSegmentedColormap
import matplotlib.pyplot as plt
Ya estamos listos para empezar.
Cómo importar los datos de StatsBomb a Python
Importamos los datos a través de varios APIs de StatsBomb:
- sb.competitions() aporta una lista de todas las competiciones abiertas disponibles, incluyendo la carrera de liga completa de Lionel Messi en el Barcelona, las últimas Copas Mundiales y Eurocopas tanto masculinas como femeninas, y muchas más. Una lista también está disponible en nuestro GitHub
- sb.matches() aporta una lista de los partidos disponibles en la competición seleccionada
- sb.events() recoge los datos de evento de un partido o de varios partidos
Empezamos con:
free_comps = sb.competitions()
free_comps
Este código nos aporta una tabla de todas las competiciones abiertas de StatsBomb, de las cuales podemos elegir la(s) que queremos analizar. En este caso, importaremos los datos del Mundial de 2022, que tiene un competition_id de 43 y un season_id de 106.
mundial_2022 = sb.matches(competition_id=43, season_id=106)
#Lista de los IDs de todos los partidos de la competición
list_matches=mundial_2022.match_id.tolist()
#Importación de los eventos de los partidos
events = []
for n in list_matches:
match_events = sb.events(match_id = n)
events.append(match_events)
events=pd.concat(events)
Cabe mencionar que también se puede utilizar la función sb.competition_events para acceder directamente a los eventos de una competición, ejecutando el siguiente código:
events = sb.competition_events(
country="International",
division= "FIFA World Cup",
season="2022",
gender="male"
)
Cómo manipular los datos de StatsBomb en Python
Como ejemplo, vamos a analizar los pases de la selección de Argentina, ganadora del Mundial, en la final ante Francia.
Filtrar a los pases
Primero, creamos una nueva tabla que solo incluye los datos de la final, en lugar de los de todos los partidos del torneo.
argentina_francia=events[events["match_id"]==3869685]
En este artículo hemos intentado seguir un flujo de trabajo lógico de competiciones > partidos > eventos para que tengas clara la relación entre los distintos niveles de los datos, pero también cabe mencionar que es posible importar directamente los datos de un determinado partido con el id del encuentro en cuestión. De hecho, si solo te interesa un partido específico, es la manera más eficiente de acceder a los datos.
Para hacerlo, ejecutamos:
argentina_francia = sb.events(match_id= 3869685)
Independientemente de la manera en la que llegas a este punto, luego podemos ejecutar el siguiente código para filtrar los datos a los pases del partido, crear nuevas columnas con las coordenadas x y y de cada pase y luego crear nuevas tablas para los pases de cada equipo.
#Filtrando solo las acciones de tipo 'Pase' en el partido específico
#Para ver que otro tipo de acciones existen se puede utilizar argentina_francia['type'].unique()
pases = argentina_francia[argentina_francia['type']=='Pass']
#separando la columna donde se encuentran las coordenadas x,y juntas a columnas por separado
#Primero creamos columnas nuevas 'x' & 'y' y las llenamos separando las coordenadas de la columna 'location'
#Segundo, creamos las columnas x & y de las coordenadas donde termina el pase y llenamos separando 'pass_end_location'
pases[['x', 'y']] = pases['location'].apply(pd.Series)
pases[['pass_end_x', 'pass_end_y']] = pases['pass_end_location'].apply(pd.Series)
#Separando en diferentes tablas los pases de Argentina y los de Francia
pases_argentina=pases[(pases["team"]=='Argentina')]
pases_francia = pases[(pases["team"]=='France')]
Cabe mencionar que se pueden encontrar los detalles de la estructura de nuestros datos y/o los nombres de los otros tipos de acciones en la especificación de datos.
Contar los pases de cada jugador
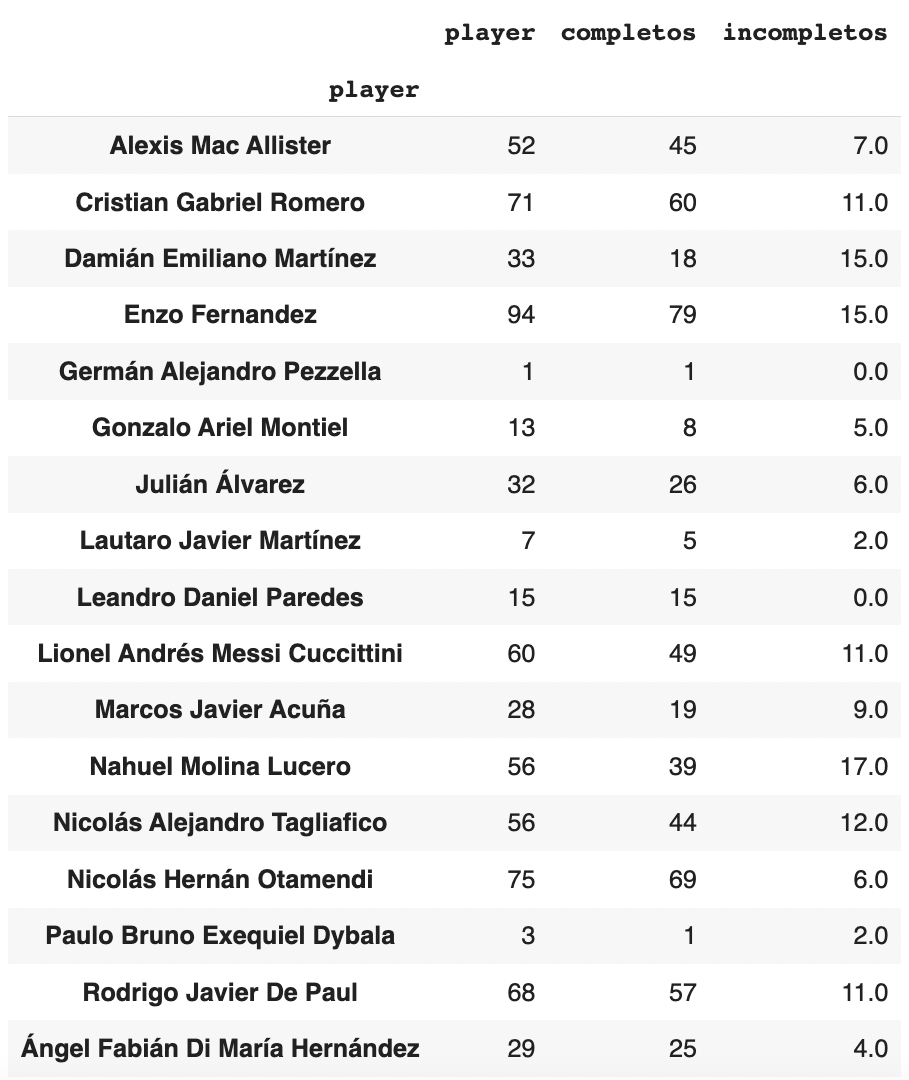
Podemos manipular nuestra tabla de los pases de Argentina para contar los pases de cada jugador del equipo…
pases_totales = pases_argentina.groupby(['player'])['player'].count().to_frame()
…y luego contar la cantidad de pases completos e incompletos para cada uno. En nuestros datos, un pase completo tiene un pass_outcome de nan.
completos = pases_argentina[pases_argentina['pass_outcome'].isnull()]
incompletos = pases_argentina[pases_argentina['pass_outcome'].notnull()]
#agregando la cuenta de los pases completos e incompletos a nuestra tabla de cuenta de pases
pases_totales['completos'] = completos.groupby(['player'])['player'].count().to_frame()
pases_totales['incompletos'] = incompletos.groupby(['player'])['player'].count().to_frame()
pases_totales = pases_totales.fillna(0)
pases_totales
Ahora, tenemos una tabla así:
Calcular el porcentaje de acierto en el pase
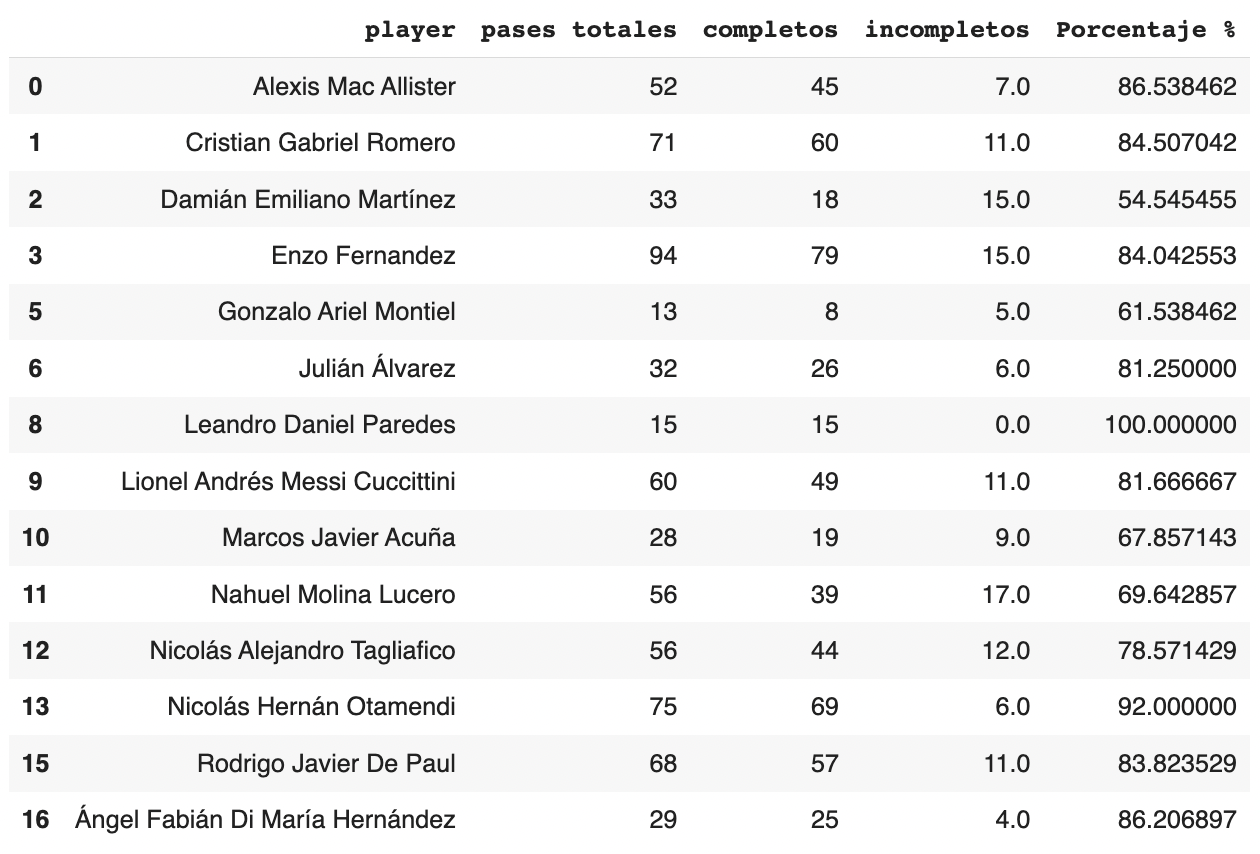
Para completar la tabla, tenemos la información necesaria para añadir una nueva columna para calcular el porcentaje de acierto en el pase de cada jugador. Asimismo, ponemos un filtro para sólo incluir a los jugadores que intentaron al menos 10 pases.
pases_totales = pases_totales.rename(columns={'player' : 'pases totales'})
pases_totales = pases_totales.reset_index()
pases_totales['Porcentaje %'] = pases_totales['completos']/pases_totales['pases totales']*100
pases_totales = pases_totales[pases_totales['pases totales']>=10]
Así queda la tabla:
Cómo visualizar los datos de StatsBomb en Python
Ahora podemos empezar a visualizar los datos de los pases.
Modificar los nombres de los jugadores
Los nombres de los jugadores que figuran en nuestros datos gratuitos son los nombres completos y para crear visualizaciones tiene sentido modificarlos a versiones más cortas.
Por ejemplo:
pases_totales['player'] = pases_totales['player'].replace(['Lionel Andrés Messi Cuccittini'],'Leo Messi')
pases_totales['player'] = pases_totales['player'].replace(['Damián Emiliano Martínez'],'Emi Martinez')
pases_totales['player'] = pases_totales['player'].replace(['Germán Alejandro Pezzella'],'Pezzella')
pases_totales['player'] = pases_totales['player'].replace(['Lautaro Javier Martínez'],'Lautaro M')
pases_totales['player'] = pases_totales['player'].replace(['Leandro Daniel Paredes'],'L.Paredes')
pases_totales['player'] = pases_totales['player'].replace(['Nicolás Alejandro Tagliafico'],'Tagliafico')
pases_totales['player'] = pases_totales['player'].replace(['Ángel Fabián Di María Hernández'],'Di María')
pases_totales['player'] = pases_totales['player'].replace(['Nicolás Hernán Otamendi'],'N.Otamendi')
pases_totales['player'] = pases_totales['player'].replace(['Cristian Gabriel Romero'],'Romero')
Crear gráficas de barras
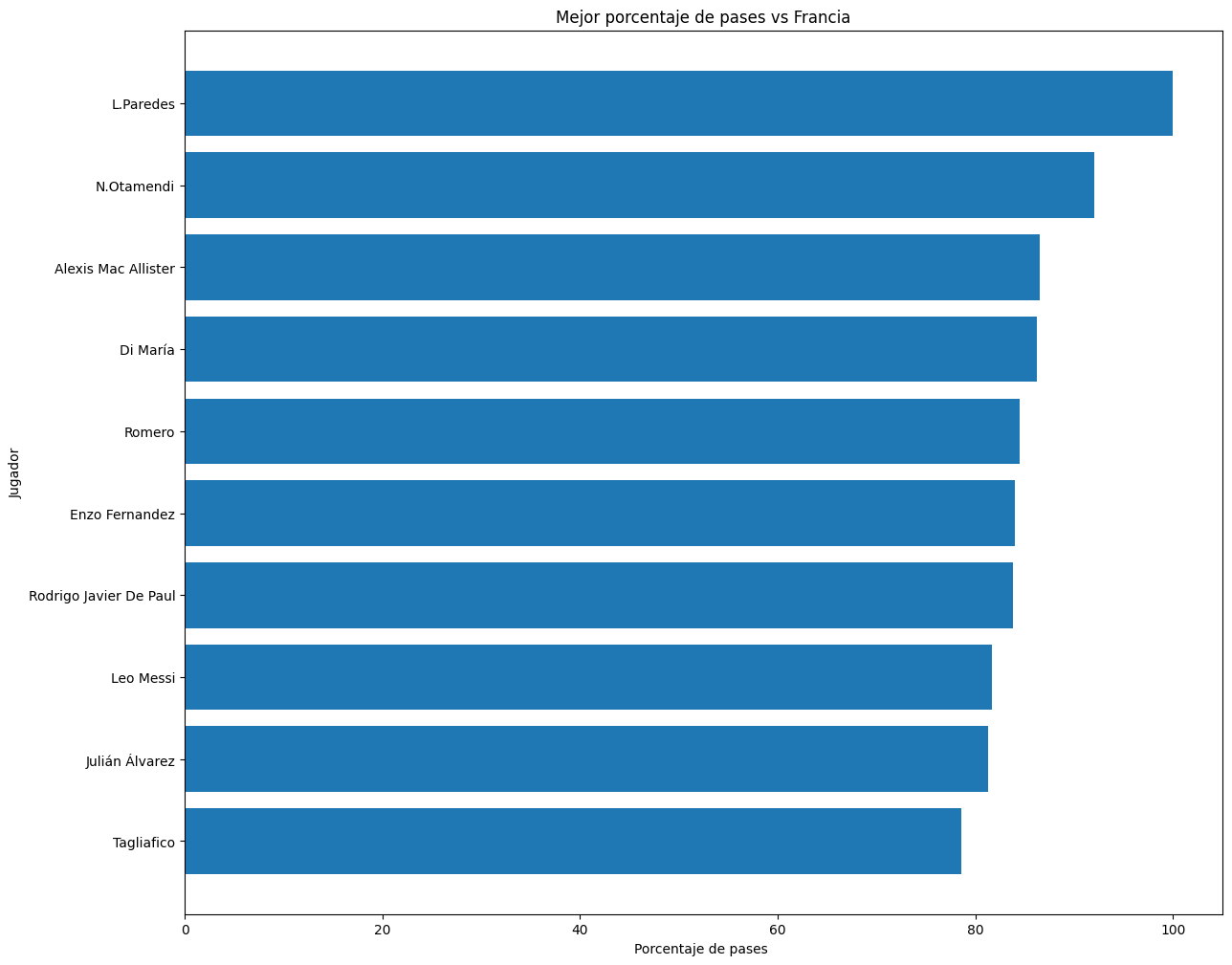
Crearemos una tabla de los 10 jugadores con las mejores cifras de acierto en el pase…
top_10_porcentaje = pases_totales.sort_values('Porcentaje %', ascending = True).tail(10)
…para luego visualizarla en una gráfica de barras.
#Puedes cambiar a gráfica vertical utilizando ax.bar en lugar de as.barh (intentalo!)
fig = plt.figure(figsize=(14, 12))
ax = plt.axes()
ax.barh(top_10_porcentaje['player'],
top_10_porcentaje['Porcentaje %'])
plt.title("Mejor porcentaje de pases vs Francia")
plt.xlabel("Porcentaje de pases ")
plt.ylabel("Jugador")
plt.show()
Con este resultado:
Asimismo, es posible mostrar dos variables en la misma barra.
#stacked = False opcional dentro de (plot.bar) para ver las barras apiladas cambiar a 'bar' para vertical
ax = pases_totales[['player','completos','incompletos']].sort_values('completos',
ascending = True).head(10).plot.barh(x='player',stacked=True)
plt.title("Pases vs Francia")
plt.xlabel("# Pases")
plt.ylabel("Jugador")
plt.show()
Con este resultado:
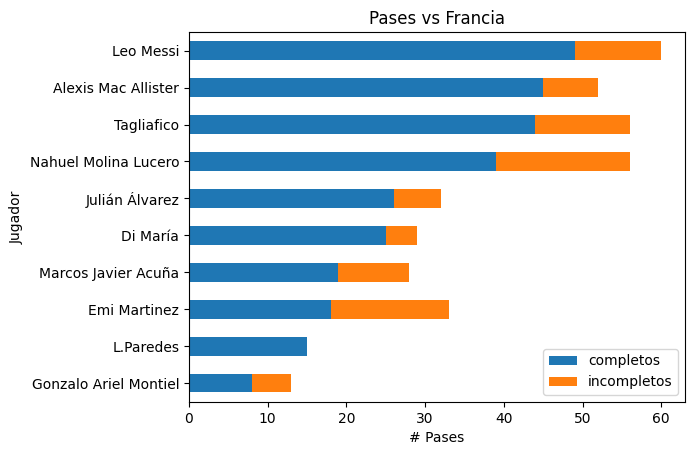
Graficar pases en un campo de fútbol
Una manera muy útil de visualizar datos de evento de fútbol es trasladarlos a un campo de juego. Como mencionamos anteriormente, el paquete mplsoccer hace mucho más fácil esta tarea en Python y en este ejemplo, lo utilizaremos para graficar los pases de un jugador.
#detalles de los colores de las líneas en el gráfico
white="white"
sbred='#e21017'
lightgrey="#d9d9d9"
darkgrey='#9A9A9A'
cmaplist = [white, darkgrey, sbred]
cmap = LinearSegmentedColormap.from_list("", cmaplist)
#Creando una función para crear el mapa de calor y de pases
def passMap(player):
player=player
#Filtrando los pases solo del jugador seleccionado
comp=completos[(completos["player"]==player)]
incomp=incompletos[(incompletos["player"]==player)]
#dibujando el campo de fútbol
pitch = Pitch(pitch_type='statsbomb', pitch_color='white', line_color='black',line_zorder=2)
fig, ax = pitch.draw(figsize=(16, 11), constrained_layout=True, tight_layout=False)
fig.set_facecolor('white')
#Contando los pases por zona y coordenadas x & y de finalizacion de los pases para el mapa de calor
bin_statistic = pitch.bin_statistic(comp.pass_end_x, comp.pass_end_y, statistic='count', bins=(12, 8), normalize=True)
pitch.heatmap(bin_statistic, ax=ax, alpha=0.5, cmap=cmap)
#Graficando las flechas de los pases
pitch.arrows(comp.x, comp.y,
comp.pass_end_x, comp.pass_end_y, width=3,
headwidth=8, headlength=5, color=sbred, ax=ax, zorder=2, label = "Pase completado")
pitch.arrows(incomp.x, incomp.y,
incomp.pass_end_x, incomp.pass_end_y, width=3,
headwidth=8, headlength=5, color=darkgrey, ax=ax, zorder=2, label = "Pase fallado")
#etiquetas de color
ax.legend(facecolor='white', handlelength=5, edgecolor='None', fontsize=20, loc='best')
#titulo
ax_title = ax.set_title('Pases de ' f'{player} vs Francia', fontsize=30,color='black')
plt.show()
#Escoge al jugador para analizar. Para repetir el mismo gráfico con otro jugador simplemente tienes que cambiar el nombre
passMap('N.Otamendi')
El resultado es así:
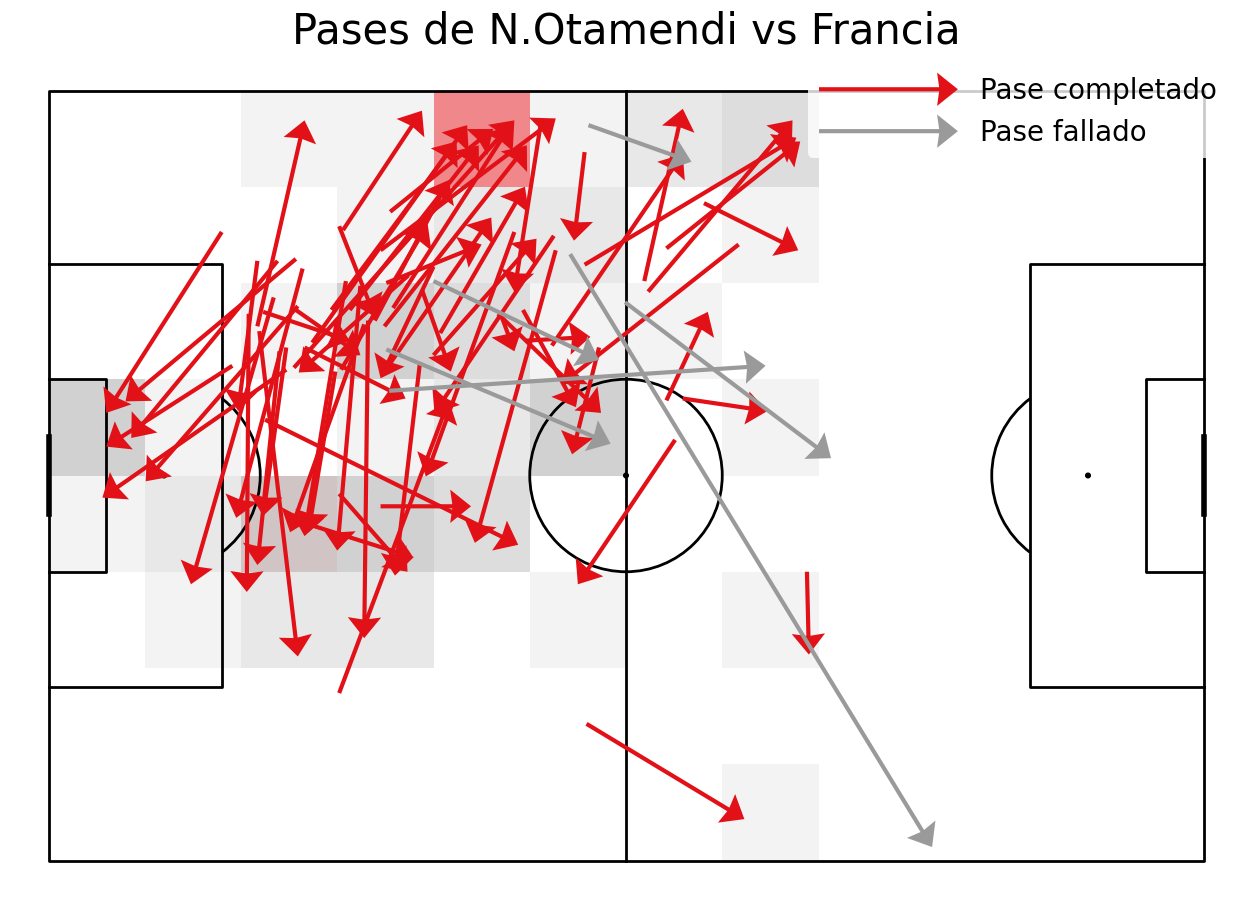
Creando el gráfico mediante una función hace mucho más fácil la repetición del mismo gráfico para otro jugador y es aconsejable para cualquier tarea que quieres repetir así.
Graficar pases al último tercio
Vamos a crear el mismo tipo de gráfico pero filtrando los datos a pases al último tercio.
#Filtrando por coordenadas pases que empezaron antes del último tercio y terminaron en el último tercio
complete_f3 = completos[(completos["pass_end_x"]>=80)]
incomplete_f3 = incompletos[(incompletos["pass_end_x"]>=80)]
complete_f3 = complete_f3[(complete_f3["x"]<80)]
incomplete_f3 = incomplete_f3[(incomplete_f3["x"]<80)]
#Creando función para hacerlo de jugadores en específico
def passMap_f3(player):
player=player
#Filtrando los pases solo del jugador seleccionado
comp=completos[(completos["player"]==player)]
incomp=incompletos[(incompletos["player"]==player)]
complete_f3 = comp[(completos["pass_end_x"]>=80)]
incomplete_f3 = incomp[(incompletos["pass_end_x"]>=80)]
complete_f3 = complete_f3[(complete_f3["x"]<80)]
incomplete_f3 = incomplete_f3[(incomplete_f3["x"]<80)]
#dibujando el campo de fútbol
pitch = Pitch(pitch_type='statsbomb', pitch_color='white', line_color='black',line_zorder=2)
fig, ax = pitch.draw(figsize=(16, 11), constrained_layout=True, tight_layout=False)
fig.set_facecolor('white')
#Contando los pases por zona y coordenadas x & y de finalización de los pases para el mapa de calor
bin_statistic = pitch.bin_statistic(complete_f3.pass_end_x, complete_f3.pass_end_y, statistic='count', bins=(12, 8), normalize=True)
pitch.heatmap(bin_statistic, ax=ax, alpha=0.5, cmap=cmap)
#Graficando las flechas de los pases
pitch.arrows(complete_f3.x, complete_f3.y,
complete_f3.pass_end_x, complete_f3.pass_end_y, width=3,
headwidth=8, headlength=5, color=sbred, ax=ax, zorder=2, label = "Pase Completo")
pitch.arrows(incomplete_f3.x, incomplete_f3.y,
incomplete_f3.pass_end_x, incomplete_f3.pass_end_y, width=3,
headwidth=8, headlength=5, color=darkgrey, ax=ax, zorder=2, label = "Pase Fallado")
#etiquetas de color
ax.legend(facecolor='white', handlelength=5, edgecolor='None', fontsize=20, loc='best')
#titulo
ax_title = ax.set_title('Pases de ' f'{player} vs Francia al ultimo tercio', fontsize=30,color='black')
plt.show()
#Escoge al jugador para analizar
passMap_f3('Enzo Fernandez')
El resultado es este:
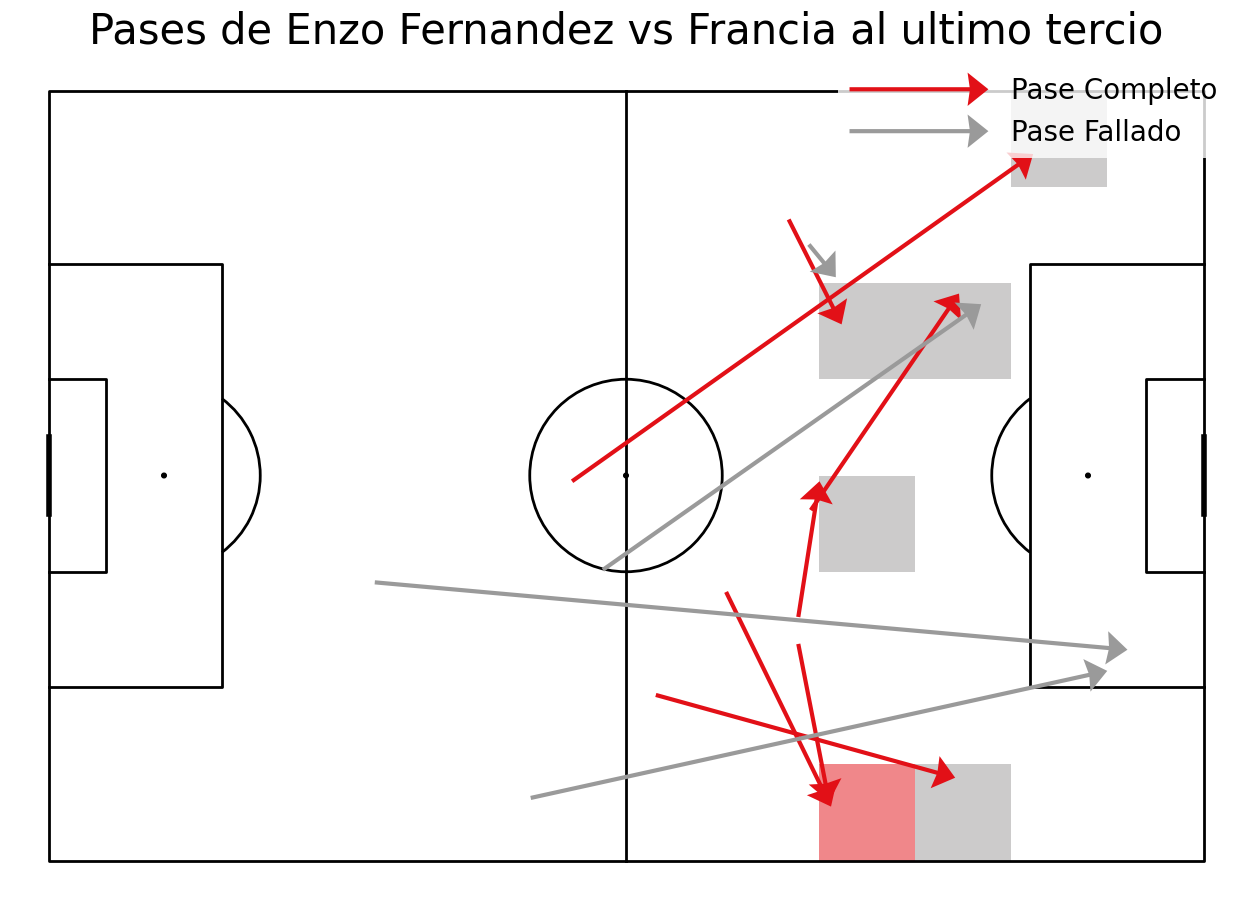
Conclusión
Este artículo funciona como una introducción a la manipulación y visualización de los datos abiertos de StatsBomb en Python, un punto de partida para análisis y visualizaciones más personalizadas. Incluso con un cambio sencillo de los filtros para incluir a diferentes variables, se puede crear algo distinto.
Si prefieres aprender a través de video, también hemos publicado la grabación del anteriormente mencionado taller online, Aprende a analizar datos de fútbol con Python, que cubre mucha de la material revisada en este artículo, en dos partes:
- Cómo empezar a utilizar los datos de StatsBomb en Python
- Cómo visualizar los datos de StatsBomb en Python
Asimismo, puedes descargar el archivo .ipynb con todo el código que utilizamos en el taller.
Publicamos datos gratuitos para impulsar el desarrollo de la próxima generación de analistas. Si harás algo interesante con nuestros datos, puedes mencionarnos en Twitter (@StatsBombES) o LinkedIn (@StatsBomb_ES). Siempre rogamos que nos menciones como la fuente de los datos.
