En StatsBomb estamos orgullosos de utilizar la tecnología más vanguardista para crear los mejores datos. Desde el primer día hemos utilizado técnicas de Visión Artificial (CV, por sus siglas en inglés) en nuestra recopilación de datos de eventos, utilizando una combinación de Inteligencia Artificial (IA) y seres humanos para proporcionar los datos de evento más precisos y detallados de la industria. Ahora, a medida que avanzamos hacia la recopilación de datos de seguimiento, conocido como tracking en inglés, estamos aprovechando cada vez más la IA para ofrecer datos de gran precisión a gran escala.
Hoy, nuestro equipo de IA te guiará a través de uno de los pilares de nuestra metodología de recopilación de datos de seguimiento: la estimación de homografía.
¿Qué es la estimación de homografía?
La estimación de homografía es un problema fundamental en Visión Artificial que implica encontrar la relación entre dos imágenes de la misma escena tomadas desde diferentes puntos de vista. En términos más sencillos, es lo que tu cerebro hace automáticamente para reconstruir la escena tridimensional cuando ve dos imágenes como las que se muestran a continuación.

Nuestro cerebro identifica automáticamente puntos o áreas en común entre las imágenes y los asocia entre ellos, reconstruyendo la escena a través de la relación que establece entre las dos imágenes. Esa relación es lo que denominamos homografía.
Muchas de las aplicaciones que usamos en nuestro día a día se basan en la estimación de homografía:
- Unión de imágenes para crear imágenes panorámicas

- La imagen HDR permite que tu teléfono capture imágenes en alta definición en condiciones de iluminación difíciles.

- Navegación autónoma: se puede utilizar para estimar la posición y orientación de un robot con respecto a su entorno. Gracias a esto, el robot puede navegar por un entorno complejo sin intervención humana.

¿Por qué es tan importante en la industria de la analítica deportiva?
Sabemos lo que es una homografía, pero ¿por qué se ha vuelto tan importante en la industria actual?
¿Alguna vez te has preguntado cómo es posible estimar cuántos kilómetros ha recorrido un jugador en un partido? ¿O cómo calcular mapas de calor de la ubicación de los jugadores?
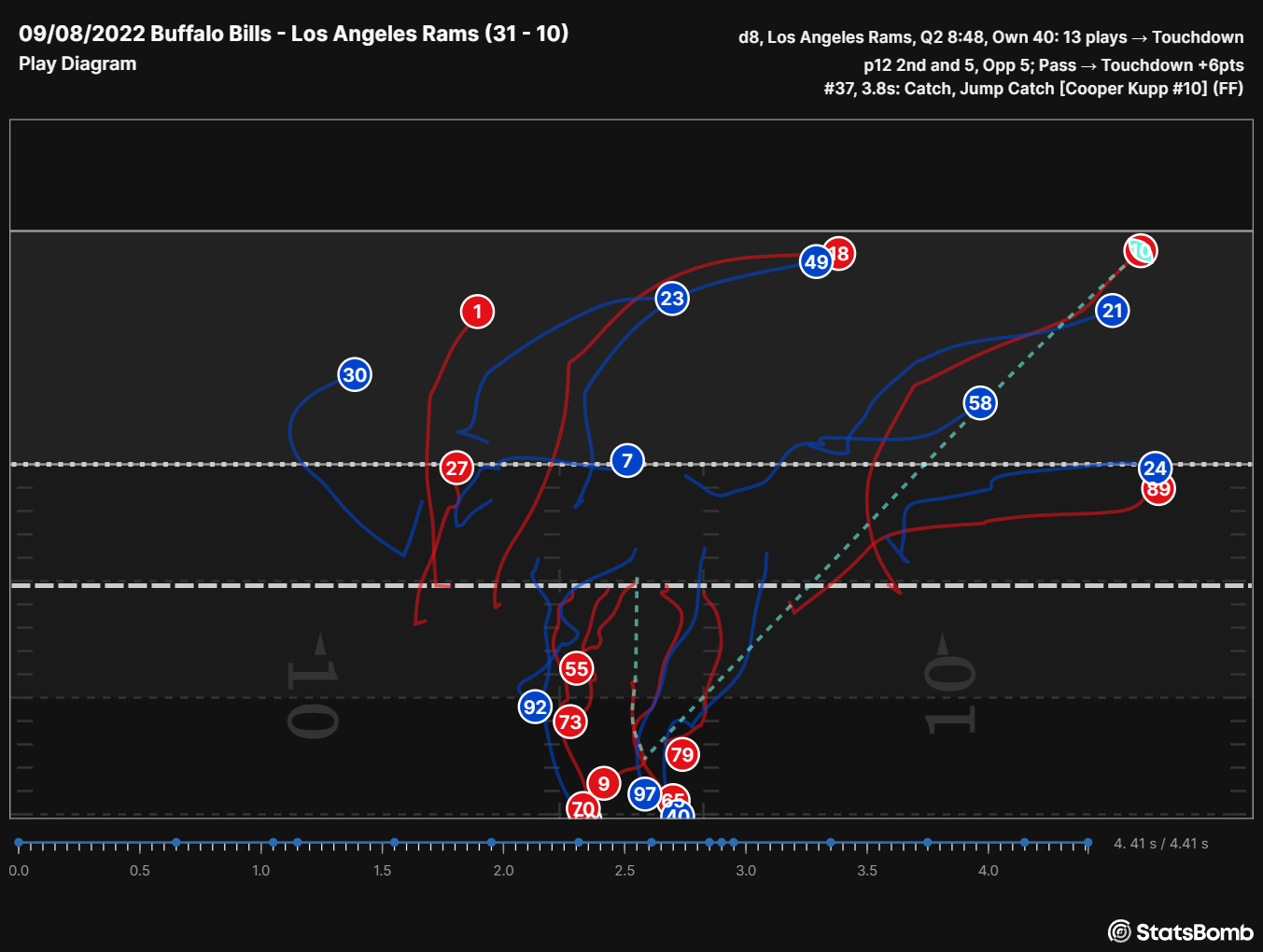
Exacto, todas estas tareas se pueden realizar gracias a la estimación de homografía. Nos permite seguir con precisión la posición y el movimiento de los jugadores y el balón en el campo, lo cual es esencial para aplicaciones de análisis deportivo como el seguimiento de jugadores, el análisis de tiros y el análisis táctico.
¿Cómo se puede lograr esto? El truco es sencillo: sabemos que una homografía relaciona dos imágenes de la misma escena desde diferentes puntos de vista. Podemos crear una imagen de control de la plantilla del campo y transferir toda la información que vemos en un partido a esa imagen. El punto de vista perfecto para nuestro caso es una vista cenital del campo, ya que no está sujeta a ninguna distorsión de perspectiva.
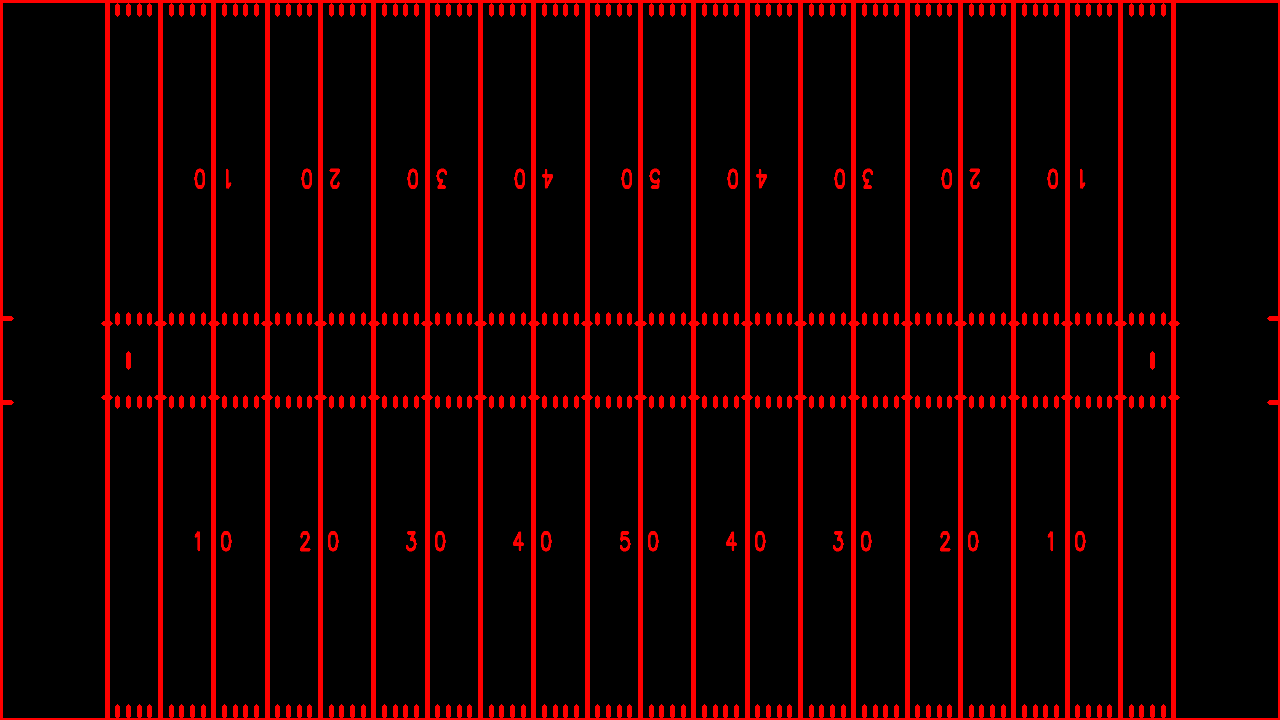
De esta forma, si conocemos la homografía que relaciona nuestra imagen de plantilla con cualquier otra, podemos transformar nuestra plantilla para que coincida con la imagen real.

¡Eso parece magia! Lo que es aún más interesante es que la transformación también se puede hacer en sentido contrario. Es decir, podemos proyectar elementos de la imagen del mundo real en nuestra plantilla. Por ejemplo, podemos dibujar el área del campo que se puede observar en la imagen anterior:

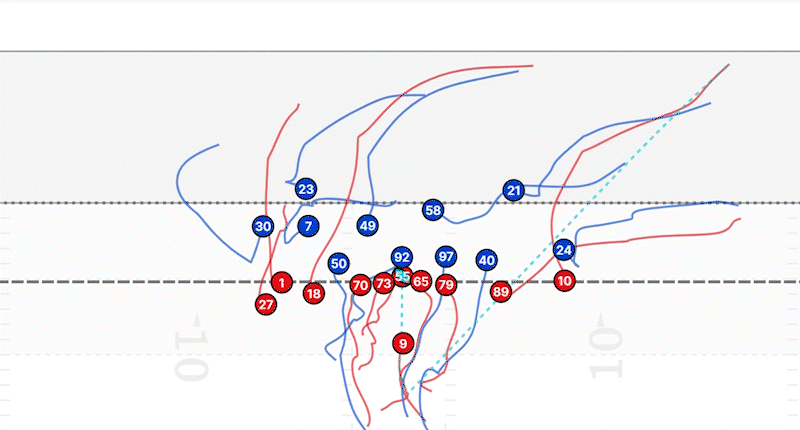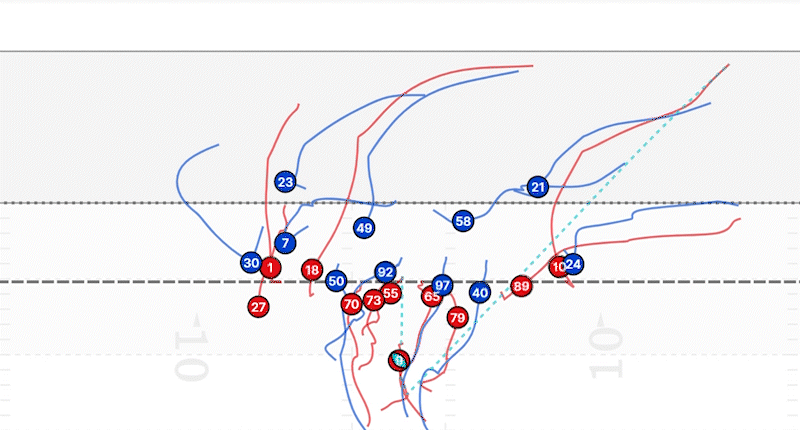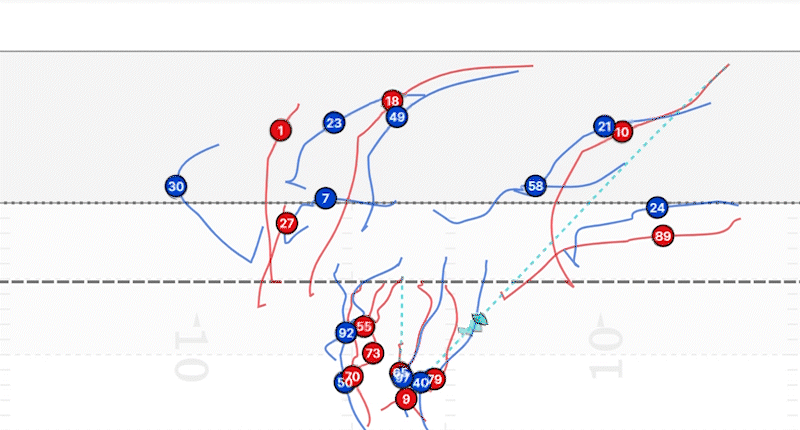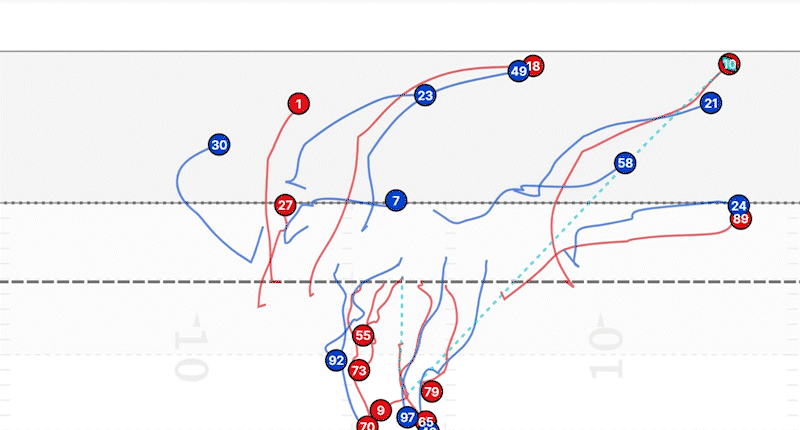
Asimismo, podemos realizar dicha transformación con cualquier objeto que esté presente en la imagen original. Supongamos, por ejemplo, que dedicamos un tiempo etiquetando a todos los jugadores que aparecen en una imagen:
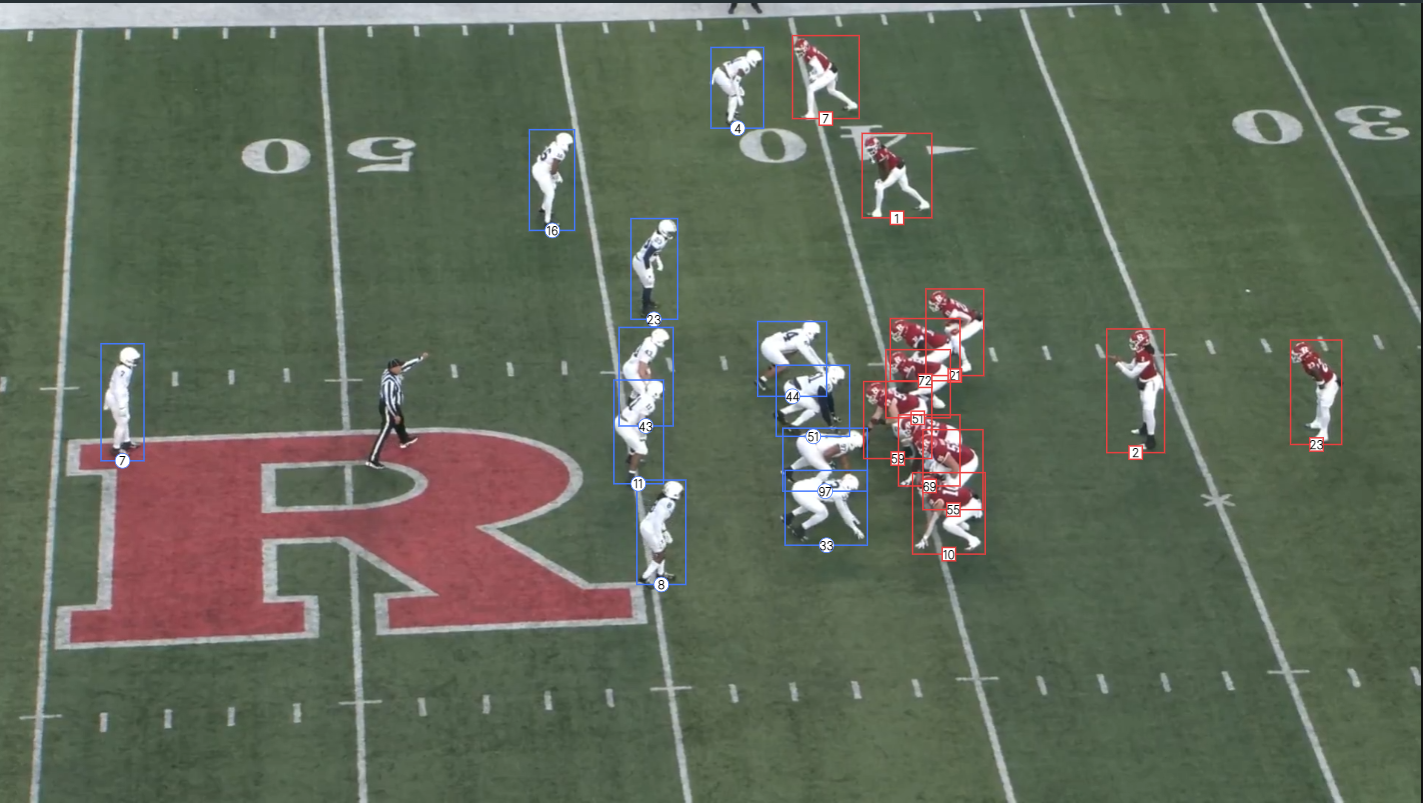
Dado que conocemos la homografía que relaciona esta imagen con nuestra plantilla, podemos proyectar nuevamente la posición de cada jugador en nuestro espacio controlado.
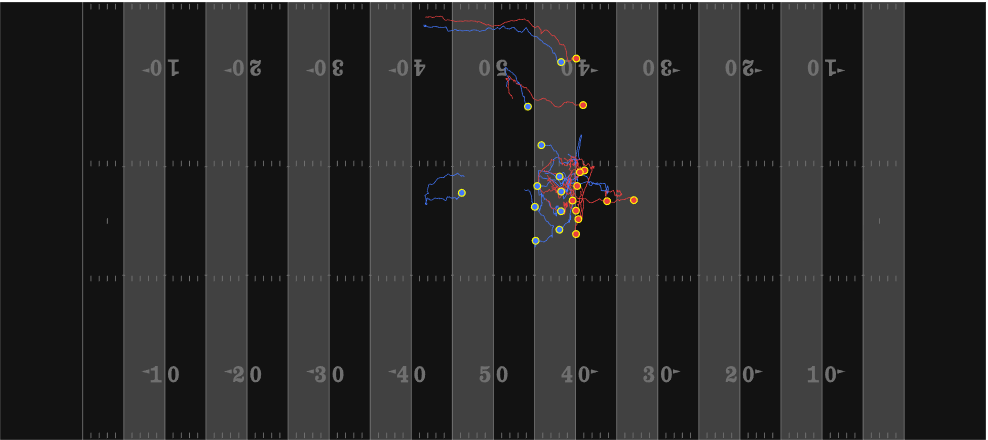
Como consecuencia, si lo que queremos es seguir la trayectoria de los jugadores, solo necesitamos etiquetar a cada jugador en los diferentes fotogramas de un video y determinar la homografía para cada una de esas imágenes. De esta forma podremos obtener esas líneas de seguimiento que se muestran en la imagen anterior.
Nuestra plantilla de control es útil para establecer relaciones espaciales. Podemos relacionar píxeles con yardas. Por ejemplo, en la realidad, la distancia entre dos líneas de yarda contiguas es de 5 yardas. En nuestra imagen de plantilla, esa distancia está representada por 20 píxeles. Por lo tanto, podemos establecer que 1 yarda corresponde a 4 píxeles. Así es cómo podemos determinar cuántas yardas ha recorrido un jugador.
Tener homografías para todas las imágenes es la clave para poder construir sistemas que pueden obtener una comprensión espacial del juego, facilitando múltiples aplicaciones que van desde proyectar gráficos de realidad virtual en el campo hasta mediciones métricas.
¿Qué necesitamos para calcular una homografía?
Como se explicó previamente, la homografía relaciona dos imágenes de la misma escena tomadas desde diferentes puntos de vista. Esto significa que un punto en la imagen A puede ser ubicado en la imagen B aplicando esa transformación.
La transformación en sí está representada por una matriz de 3x3. No vamos a profundizar demasiado en los detalles técnicos en este artículo, pero como simple intuición, puedes pensar en ello de la siguiente manera: si obtenemos las coordenadas en pixeles de un jugador en la imagen real \(p_i\), y después las multiplicamos por la matriz de homografía \(H\), obtendremos las coordenadas del jugador en la plantilla \(p_t\).
\(p_i H = p_t\)

Para calcular una homografía, primero necesitamos encontrar puntos correspondientes entre las dos imágenes. Es decir, necesitamos localizar los mismos puntos en ambas imágenes. Matemáticamente, necesitamos al menos cuatro pares de puntos correspondientes para obtener una matriz de homografía válida.
StatsBomb ha desarrollado una excelente aplicación que permite a nuestros etiquetadores crear rápidamente cuatro pares de puntos para después resolver automáticamente el sistema de ecuaciones que proporciona la matriz de homografía.
Este procedimiento es rápido, pero cuando se considera la increíble cantidad de ligas, partidos y fotogramas que deben procesarse en una sola semana, es fácil darse cuenta de que escalar y automatizar esta tarea es esencial. Sin la automatización, se convierte en un cuello de botella para todas las demás aplicaciones.
¿Cómo ayuda la IA?
La inteligencia artificial (IA) ha tenido un impacto importante en el campo de la visión artificial, con aplicaciones en tareas como la detección de objetos, la segmentación de imágenes y la estimación de homografía. Los métodos tradicionales para la estimación de homografías son a menudo computacionalmente costosos y pueden ser inexactos, especialmente en casos en los que las imágenes son de baja calidad o se han tomado en condiciones complejas. La IA se puede utilizar para mejorar la precisión y eficiencia de la estimación de homografías aprendiendo de grandes conjuntos de datos de imágenes. Se ha demostrado que los modelos de Deep Learning, en particular, son muy efectivos para esta tarea.
El Deep Learning es una subdisciplina de la inteligencia artificial (IA) que se centra en el entrenamiento de redes neuronales artificiales para aprender de grandes cantidades de datos. El aprendizaje supervisado es una técnica común utilizada en el Deep Learning, donde la red se entrena sobre datos etiquetados para así predecir la salida correcta para nuevas entradas no vistas.
Hay muchas formas diferentes de entrenar un modelo de Deep Learning para recuperar la matriz de homografía entre una imagen y una plantilla del campo. Nuestro modelo actual está entrenado para reconocer ubicaciones características en el campo, que luego se pueden usar para resolver la ecuación \(p_i H = p_t\) para obtener la matriz de homografía.
Al comienzo del entrenamiento, el rendimiento del modelo es pobre. Comete muchos errores y no es capaz de distinguir entre diferentes ubicaciones específicas. Por ejemplo, podría confundir la línea de touchdown con una línea de yarda. Sin embargo, a medida que el modelo se expone a más imágenes, comienza a extraer patrones que se pueden aplicar a nuevas imágenes no vistas. Esto le permite predecir la homografía de una imagen que nunca ha visto antes. A todo este proceso se le conoce como entrenamiento del modelo, y es la clave del rendimiento de nuestro estimador de homografías.
Una de las principales desventajas de estos modelos es que necesitan de una gran cantidad de datos etiquetados para funcionar correctamente. Gracias a nuestro experimentado equipo de etiquetado, StatsBomb puede presumir de disponer de la mayor calidad de datos en el mercado.
Una vez que nuestro modelo ha sido entrenado, está listo para ser implementado y utilizado. Sin embargo, es importante tener en cuenta que los modelos se entrenan con datos del pasado. Los cambios en los estadios o los partidos jugados en condiciones climáticas extremas o condiciones de iluminación especiales pueden no estar presentes en nuestros datos de entrenamiento. Como resultado, nuestro modelo puede tener problemas en estas nuevas situaciones por falta de experiencia. Es por eso que continuamos entrenando nuestros modelos periódicamente, incorporando nuevos datos para garantizar resultados de alta calidad.
Ejemplos de StatsBomb
Este es el primero de una serie de artículos de nuestro equipo de IA, con el objetivo de transmitir cómo la IA es fundamental para nuestro equipo de recopilación de datos. Si deseas discutir cualquiera de los temas o ideas tratados en el artículo, no dudes en ponerte en contacto con nuestro ingeniero de aprendizaje automático y autor del artículo Miguel Méndez Pérez.