
¿Quieres aprender cómo organizar y utilizar datos de fútbol? Aquí está una introducción de cómo trabajar con los datos gratuitos de Hudl Statsbomb en R.
En Hudl Statsbomb tenemos el compromiso de liberar parte de nuestros datos para fomentar activamente la investigación y análisis original a todos los niveles. Para tal fin, hemos puesto a disposición del público nuestros datos de varias competiciones.
Esperamos que esta introducción os sirva para iniciaros en el uso de datos para analizar el fútbol.
Los datos accesibles de manera gratuita cuentan con las mismas especificaciones que hacen a nuestros datos ser los líderes de la industria e incluyen un nivel de detalle y precisión mayor que en cualquier otro proveedor de datos.
Nuestro feed de datos incluye, entre otros, los siguientes aspectos:
- La posición de los jugadores atacantes y defensores en todas las situaciones de remate incluyendo la posición y las acciones del portero durante el desarrollo de la misma.
- Información detallada sobre todos los jugadores que ejercen presión sobre el jugador con balón durante la fase defensiva – incluyendo la duración de la presión, la dirección y las acciones subsiguientes.
- Pie con el que realiza los pases cada jugador, altura del pase, y muchas otras variables que otorgan mayor detalle a nuestros datos.
Hemos publicado una gran variedad de conjuntos de datos gratuitos, incluyendo la carrera de liga completa de Lionel Messi en el Barcelona, el PSG y el Inter de Miami, las últimas Copas Mundiales y Eurocopas tanto masculinas como femeninas o la temporada invicta del Bayer Leverkusen de Xabi Alonso.
Para los que prefieren trabajar en Python, también tenemos una guía para el uso de nuestros datos en Python.
¿Qué es R y por qué usarlo?
R es un lenguaje de programación especialmente útil para el manejo de datasets estadistícas. En el ámbito que nos ocupa (estadística avanzada en fútbol) nos permite procesar datasets para diferentes fines tales como la creación de métricas así como visualizaciones de los mismos.
R se puede descargar de manera gratuita en este enlace: https://cran.r-project.org/mirrors.html
En Hudl Statsbomb trabajamos regularmente con R en nuestro día a día, particularmente en el departamento de análisis. Empezar a trabajar con hojas de cálculo puede ser una posibilidad válida al comienzo, pero a medida que las dataset son más grandes se vuelven más difíciles de manejar haciendo casi imposible realizar un análisis detallado de los mismos sin manejar un lenguaje de programación.
Una vez superada la curva de aprendizaje, R es ideal para trabajar y analizar los datos de manera eficiente y sencilla.
Antes de empezar, es recomendable tener instalado la versión más actualizada de R, al menos la versión 3.6.2.
RStudio
La versión básica de R no es lo más visual del mundo. Esto ha llevado a la creación de varios entornos de desarrollo integrados (IDEs). Estos wrappers son softwares desarrollados a partir de la versión inicial y tratan de hacer la mayoría de tareas dentro de R más sencillas y manejables para el usuario.
El más popular de estos es RStudio: https://www.rstudio.com/products/rstudio/
Es recomendable instalar RStudio u otro IDE similar para que el proceso de trabajo con los datos de Hudl Statsbomb más simple y limpio.
Abrir un Proyecto Nuevo en R
Esto es lo que verá el usuario al cargar por primera vez RStudio (sin las anotaciones).

En caso de no tener clara la función de cada opción o sección de RStudio es recomendable echar un vistazo a alguna de las hojas de consejos y tutoriales relativos en:
Es muy fácil encontrar una gran cantidad de recursos con explicaciones y respuestas detalladas a cualquier pregunta que pueda surgir respecto a R.
¿Qué es un Paquete de R?
Los paquetes son conjuntos de funciones que simplifican tareas. Se pueden descargar fácilmente. Para instalar un paquete en R simplemente hay que ejecutar install.packages("NombreDelPaquete").
Los paquetes que utilizaremos y que será necesario tener instalados son los siguientes:
- ‘tidyverse’: tidyverse contiene dentro de sí un conjunto paquetes útiles para manipular datos (por ejemplo dplyr y magrittr). install.packages("tidyverse")
- ‘devtools’: La mayoría de paquetes se encuentran en CRAN. Sin embargo, también se pueden encontrar muchos paquete útiles en Github. Devtools permite descargar los paquetes directamente desde Github. install.packages("devtools")
- ‘ggplot2’: El paquete más popular para llevar a cabo la visualización de datos en R
- ‘StatsbombR’: El paquete propio de Hudl Statsbomb para analizar nuestros datos
Una vez que un paquete está instalado se puede cargar ejecutando library(NombreDelPaquete). Deben importarse antes del comienzo de una sesión.
¿Qué es ‘StatsbombR’?
StatsbombR es un paquete dedicado a hacer uso de los datos de Hudl Statsbomb de manera más sencilla e intuitiva. Se puede descargar en este enlace de Github donde se incluye además información sobre su uso: https://github.com/statsbomb/StatsbombR
Para instalar el paquete en R es necesario instalar primero un par de paquetes diferentes ejecutando las siguientes líneas:
install.packages("devtools")
install.packages("remotes")
remotes::install_version("SDMTools", "1.1-221")
Para instalar StatsbombR ejecuta a continuación:
devtools::install_github("statsbomb/StatsBombR")
Información Adicional Sobre los Paquetes
Para encontrar más información sobre las diferentes funciones dentro de un paquete sólo hay que hacer click en el nombre del paquete como se ve en la imagen.

Esto nos mostrará la información del paquete incluyendo los detalles de sus funciones.

Importar los datos de Hudl Statsbomb
Para manejar nuestros datos en R es necesario familiarizarse antes con varias funciones importantes dentro de StatsbombR.
- FreeCompetitions() – Muestra todas las competiciones disponibles en los datos gratuitos. Almacenar el output de esta o cualquier otra función en lugar de tenerlo en la consola de R es posible hacerlo ejecutando lo siguiente:
- Comp <- FreeCompetitions(). Así, al ejecutar Comp (o cualquier palabra utilizada para tal caso) dará el output de FreeCompetitions()
- Matches <- FreeMatches(Comp) - Muestra todos los partidos disponibles dentro de las competiciones seleccionadas.
- StatsBombData <- free_allevents(MatchesDF = Matches, Parallel = T) – Importar todos los datos de evento para los partidos seleccionados.
A continuación vamos a ver un ejemplo de cómo importar datos en R. Primero, abrimos un nuevo script para tener el código accesible de la siguiente manera File -> New File -> R Script. Se puede guardar en cualquier momento.
library(tidyverse)
library(StatsBombR)#1
Comp <- FreeCompetitions() %>%
filter(competition_id==11 & season_name=="2005/2006")#2
Matches <- FreeMatches(Comp)#3
StatsBombData <- free_allevents(MatchesDF = Matches, Parallel = T)#4
StatsBombData = allclean(StatsBombData)#5
1: tidyverse importa varios paquetes diferentes. Los más importantes para esta tarea son dplyr y magrittr. StatsbombR importa StatsbombR.
2: Importa las competiciones disponibles para el usuario y se filtran utilizando la función ‘filter’ de dplyr para obtener la temporada 05/06 de La Liga en este caso.
3: Importa todos los partidos de la competición seleccionada.
4: En este punto se ha creado una ‘dataframe’ (esencialmente una tabla u hoja de datos) llamada StatsBombData (o el nombre elegido para tal caso) con todos los datos de evento gratuitos para la temporada 05/06 de la Liga.
5: Extrae toda la información relevante previamente descrita.
Trabajar con los datos
En nuestro Github (el mismo lugar donde se pueden encontrar los datos) se pueden encontrar documentos adicionales con las especificaciones de Hudl Statsbomb Data. Estos están disponibles para ver o descargar y contienen explicaciones a las dudas que puedan surgir sobre los distintos tipos de eventos o cuestiones similares.
Los documentos incluyen:
- Open Data Competitions v2.0.0.pdf– Cubre los contenidos en la información de las competiciones ( FreeCompetitions() ).
- Open Data Matches v3.0.0.pdf – Describe la información de partido para descargar ( FreeMatches() ).
- Open Data Lineups v2.0.0.pdf – Describe la estructura de la información de alineación ( getlineupsFree() ).
- Open Data Events v4.0.0.pdf – Incluye los significados de los nombres en las columnas dentro de los datos de evento.
- Statsbomb Event Data Specification v1.1.pdf – Descripción detallada de todos los eventos en los datos.
Ejemplos de uso de los datos
Una vez que tenemos disponible el archivo StatsBombData vamos a ver varios modos en los que se puede utilizar al mismo tiempo que nos familiarizamos con R. Los ejemplos irán incrementando en grado de dificultad.
Ejemplo 1: Tiros y Goles
Un punto de partida simple pero fundamental. Veremos cómo extraer los números de tiros y goles de cada equipo, primero los totales y luego los de cada partido.
Primero, vamos a importar los datos para la temporada 2018-19 de la FA Women’s Super League. Utilizamos de nuevo el código citado arriba, pero esta vez la competition_id será 42 y la season_id será "2018/2019".
Después, escribimos:
shots_goals = StatsBombData %>%
group_by(team.name) %>% #1
summarise(shots = sum(type.name=="Shot", na.rm = TRUE),
goals = sum(shot.outcome.name=="Goal", na.rm = TRUE)) #2
Vamos a desgranarlo paso a paso:
1: Este código agrupa los datos por equipo, de tal forma que cualquier operación que realicemos en ellos será ejecutada por cada equipo. I.e. extraerá los tiros y goles para cada equipo de manera individual.
2: Summarise toma cualquier operación ejecutada y genera una tabla nueva y separada con ello. La mayoría de usos de summarise suelen ser después de group_by.
shots = sum(type.name=="Shot", na.rm = TRUE) crea una nueva columna llamada ‘shots’ que suma todas las filas bajo la columna ‘type.name’ que contienen la palabra ‘Shot’.
na.rm = TRUE pide ignorar cualquier NA dentro de esa columna.
shot.outcome.name=="Goal", na.rm = TRUE) hace lo mismo con los goles.
En este punto deberíamos tener una tabla como esta.
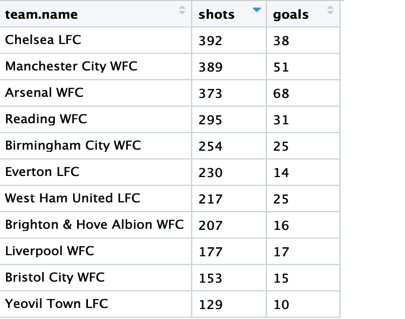
Para realizar el mismo cálculo por partido en lugar de los totales solo tenemos que cambiarlo de la siguiente manera:
shots_goals = StatsBombData %>%
group_by(team.name) %>%
summarise(shots = sum(type.name=="Shot", na.rm = TRUE)/n_distinct(match_id), goals = sum(shot.outcome.name=="Goal", na.rm = TRUE)/n_distinct(match_id))
Añadir ‘/n_distinct(match_id)’ implica que estamos dividiendo el número de tiros/goles entre el número de partidos para cada equipo.
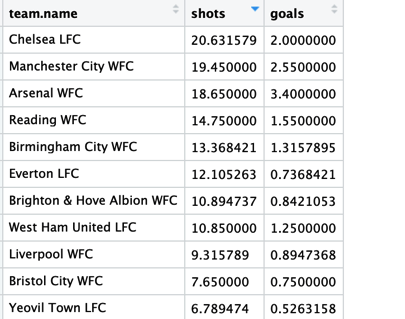
Ejemplo 2: Crear Gráficos de los Tiros
Una vez que tenemos los datos de tiros y goles ¿cómo podemos crear un gráfico a partir de ellos?
library(ggplot2)
ggplot(data = shots_goals, aes(x = reorder(team.name, shots), y = shots)) #1 +
geom_bar(stat = "identity", width = 0.5) #2 +
labs(y="Shots") #3 +
theme(axis.title.y = element_blank()) #4 +
scale_y_continuous( expand = c(0,0)) #5 +
coord_flip() #6
1: Aquí estamos diciendo a ggplot qué datos estamos utilizando y qué queremos en los ejes x/y del gráfico. ‘Reorder’ ordena los nombres de los equipos en función de los tiros.
2: Pide a ggplot formatearlo como un gráfico de barras.
3 : Cambia el nombre del eje de tiros.
4 : Elimina el título del eje.
5 : Aquí podemos reducir el espacio entre las barras y el límite del gráfico.
6 : Rota el gráfico completo colocando las barras en sentido horizontal.
Lo anterior debería generar un gráfico como este.

El diseño obtenido es básico y diáfano. Puede ser modificado de diferentes maneras para conseguir un visual más atractivo.
Cualquier elemento de un gráfico ggplot desde el texto a los datos en sí puede ser modificado de numerosas maneras abriendo la puerta a la creatividad del usuario.
Más información sobre el tipo de diseños que se pueden conseguir: https://ggplot2.tidyverse.org/reference/
Ejemplo 3: Tiros cada 90 minutos
Extraer los tiros para jugadores es relativamente sencillo una vez que sabemos hacerlo para equipos. ¿Pero cómo podemos ajustar los números por cada 90 minutos?
player_shots = StatsBombData %>%
group_by(player.name, player.id) %>%
summarise(shots = sum(type.name=="Shot", na.rm = TRUE)) #1
player_minutes = get.minutesplayed(StatsBombData) #2
player_minutes = player_minutes %>%
group_by(player.id) %>%
summarise(minutes = sum(MinutesPlayed)) #3
player_shots = left_join(player_shots, player_minutes) #4
player_shots = player_shots %>%
mutate(nineties = minutes/90) #5
player_shots = player_shots %>%
mutate(shots_per90 = shots/nineties) #6
1: Similar al cálculo para los equipos. Incluimos aquí ‘player.id’ ya que será importante después.
2: Esta función obtiene los minutos de cada jugador en cada partido en la muestra.
3: Agrupamos lo anterior sumando los minutos en cada partido para obtener el total de minutos disputados por cada jugador.
4 : left_join combina las tablas de tiros y de minutos con el player.id actuando como punto de referencia.
5: mutate es una función dplyt que crea una nueva columna. En este caso estamos creando una columna que divide los minutos totales entre 90 dando como resultado el número de 90s del jugador en la temporada.
6 : Finalmente dividimos los tiros totales entre el número de 90s para obtener la columna de tiros cada 90 minutos (shots per 90).
En este punto tendremos los tiros cada 90 minutos para todas las jugadoras de la WSL.

A continuación, se puede filtrar la tabla eliminando a las jugadores con insuficiente muestra mediante la función ‘filter’ (dplyr).
El mismo proceso puede ser aplicado a todo tipo de eventos: diferentes tipos de pases, acciones defensivas, etc.
Ejemplo 4: Representar Pases Gráficamente
Filtar los datos extrayendo un subconjunto de datos y visualizarlos sobre un campo empleando para ello ggplot2.
Finalmente, vamos a trazar los pases de un jugador en el campo. Para esto necesitaremos en primer lugar una visualización de un campo de fútbol. Es posible crear uno propio una vez estemos familiarizados con ggplot que pueda ser utilizado además para diferentes propósitos. Más adelante veremos opciones para ello. De momento, hay opciones ya formateadas que podemos utilizar.
La que utilizaremos aquí es cortesía de FC rStats. Este usuario de Twitter ha creado varios paquetes públicos de R para analizar datos de fútbol. El paquete que nos ocupa se llama ‘SBPitch’ y sirve exactamente para eso. En ‘Paquetes Adicionales’ veremos otras alternativas para crear campos de juego.
Para instalar SBPitch ejecutamos:
devtools::install_github("FCrSTATS/SBpitch")
Vamos a representar los pases completados por Messi dentro del área en la Liga 05/06. Trazar todos los pases sería farragoso y poco útil por tanto elegimos un subconjunto. Es importante asegurarse de utilizar las funciones explicadas anteriormente para importar los datos.
library(SBpitch)
passes = messidata %>%
filter(type.name=="Pass" & is.na(pass.outcome.name) & player.id==5503) #1 %>%
filter(pass.end_location.x>=102 & pass.end_location.y<=62 & pass.end_location.y>=18) #2
create_Pitch() +
geom_segment(data = passes, aes(x = location.x, y = location.y, xend = pass.end_location.x, yend = pass.end_location.y), lineend = "round", size = 0.6, arrow = arrow(length = unit(0.08, "inches"))) #3 +
labs(title = "Lionel Messi, Completed Box Passes", subtitle = "La Liga, 2005/2006") #4 +
scale_y_reverse() +
coord_fixed(ratio = 105/100) #5
1: Filtrar los pases de Messi. is.na(pass.outcome.name) filtrar solo los pases completados.
2: Filtrar los pases dentro del área. Las coordenadas del campo se pueden encontrar en nuestro event spec.
3: Obtenemos una flecha desde un punto de origen (location.x/y inicio del pase) a un punto final (pass.end_location.x/y, final del pase). Lineend, size y length son las opciones de customización disponibles aquí.
4: Crea un título y subtítulo para el gráfico. Entre otras opciones se puede añadir una leyenda usando caption =.
5: Ajusta el gráfico a la relación de aspecto elegida para que no quede estirado o poco estético. El resultado será un gráfico tal que así. De nuevo, esta es una versión básica a partir de la cual se pueden implementar todo tipo de mejoras visuales.

La opción theme() permite cambiar el tamaño, posición, fuente y otros aspectos de los títulos así como otros apartados estéticos del gráfico.
Es posible añadir colour= a geom_segment() para colorear los las flechas de cada pase del modo escogido.
En el siguiente enlace se pueden encontrar diferentes posibilidades disponibles para customizar los gráficos: https://www.rstudio.com/resources/cheatsheets/
Funciones útiles en StatsbombR
Existen docenas de funciones dentro de StatsbombR para realizar diferentes tareas. Se puede consultar la lista completa aquí. No todas las funciones están disponibles en los datos gratuitos. Algunas solo son accesibles para nuestros clientes (vía API). Una pequeña muestra de las más útiles:
- get.playerfootedness() – Devuelve la pierna hábil (preferida) de un jugador a partir de nuestros datos de pases (incluyen la pierna con la que se realiza el pase).
- get.opposingteam() – Devuelve una columna opuesta para cada equipo en cada partido.
- get.gamestate() – Devuelve la información de cuánto tiempo acumula cada equipo en cada uno de los posibles Game States (ganando/empatando/perdiendo).
- annotate_pitchSB() – Nuestra solución para trazar un campo de juego en ggplot.
Paquetes adicionales
La comunidad ha desarrollado múltiples paquetes para R. Es probable que cualquier cuestión o tarea que se quiera llevar a cabo en R tenga desarrollado un paquete específico para ella. Nombrar todos sería imposible pero aquí va una pequeña selección de algunos que son relevantes para trabajar con nuestros datos:
- Ben Torvaney, ggsoccer - Alternativa para trazar campos de juego con los datos de Hudl Statsbomb.
- Joe Gallagher, soccermatics – Otra alternativa para dibujar campos de juego incluyendo además atajos sencillos para crear mapas de calor entre otras funciones.
- ggrepel – Solución para problemas de texto superpuesto en las gráficas.
- gganimate – Opción sencilla para crear gráficos animados con ggplot en R.