


Hace tres semanas presentamos On-Ball Value (en adelante, OBV), nuestro nuevo modelo que mide el valor de cada acción en una posesión. Esta semana, vamos a dar algunos ejemplos del modelo en acción, utilizando principalmente los datos de la pasada temporada de La Liga.
Para tener todos los detalles del modelo hay que leer el artículo de presentación, pero de manera sencilla, OBV mide el cambio en la probabilidad de un equipo de marcar/conceder como resultado de una acción dada. Esto permite identificar las acciones más relevantes en una posesión y poder otorgar más mérito a las acciones con mayor impacto en la posesión.
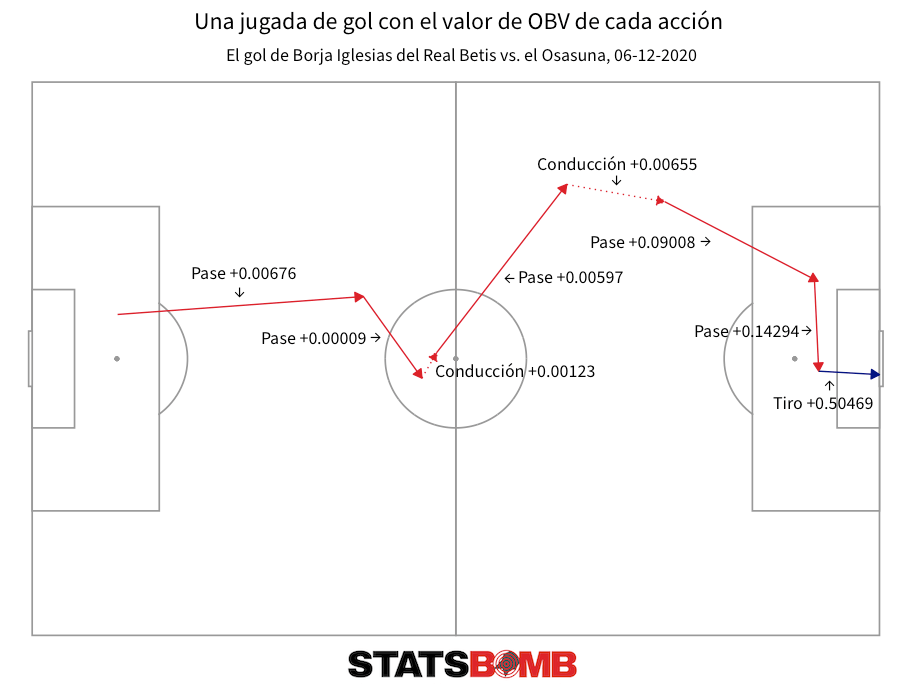
Para visualizar un poco el concepto, aquí está la jugada del gol de Borja Iglesias del Real Betis contra el Osasuna en diciembre de 2020 con el valor de OBV marcado para cada acción de la jugada. Como es lógico, los valores aumentan a medida que la jugada se acerca al área de penalti del rival.
El siguiente gráfico también ayuda a explicar la utilidad del modelo. Se trata de los pases directamente previos a una asistencia o un pase clave, a veces llamados pre asistencias, en este caso pases rasos y con los pies. Muestra los 30 pases más valiosos de este tipo según OBV y también los 30 pases menos valiosos, pases que, de hecho, tuvieron un efecto negativo en la probabilidad de que marcara el equipo.
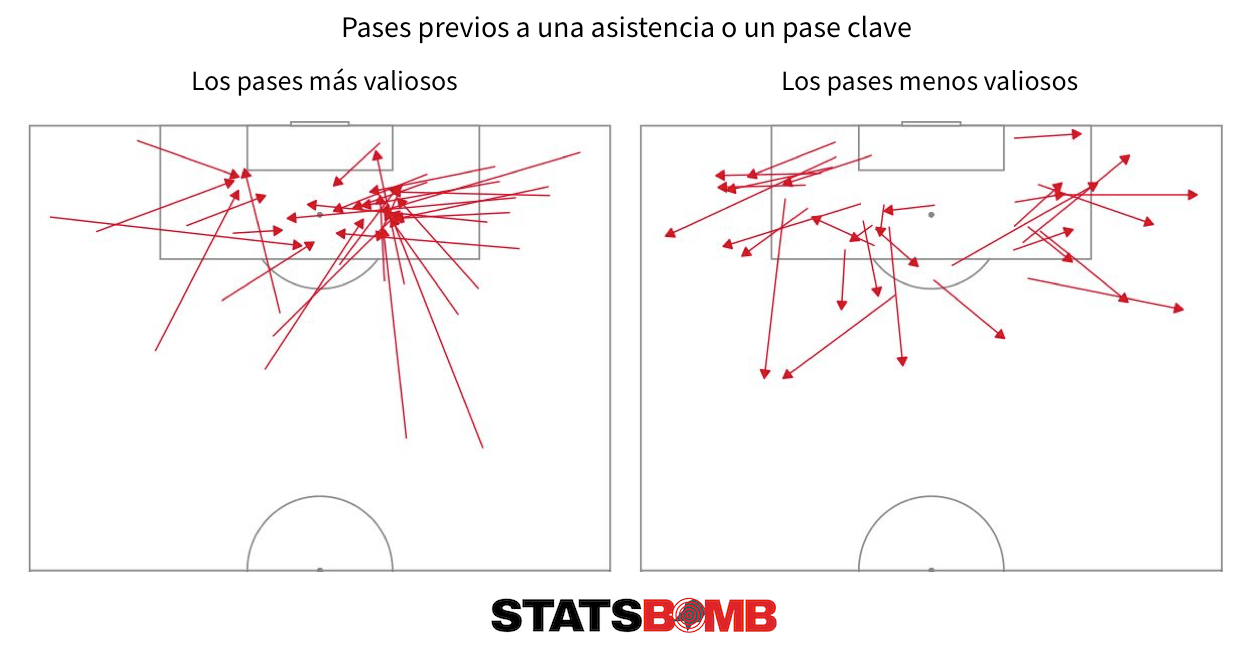
Aquí, el valor del modelo queda claro. En vez de simplemente decir que un jugador ha acumulado tres pre asistencias, por ejemplo, podemos otorgar un valor a cada una de ellas y tener una idea mucho más precisa de la contribución del jugador.
Vamos a echar un ojo a los números acumulados de la pasada temporada de La Liga a nivel de jugadores. ¿Qué jugadores de campo agregaron más valor con sus acciones con balón?
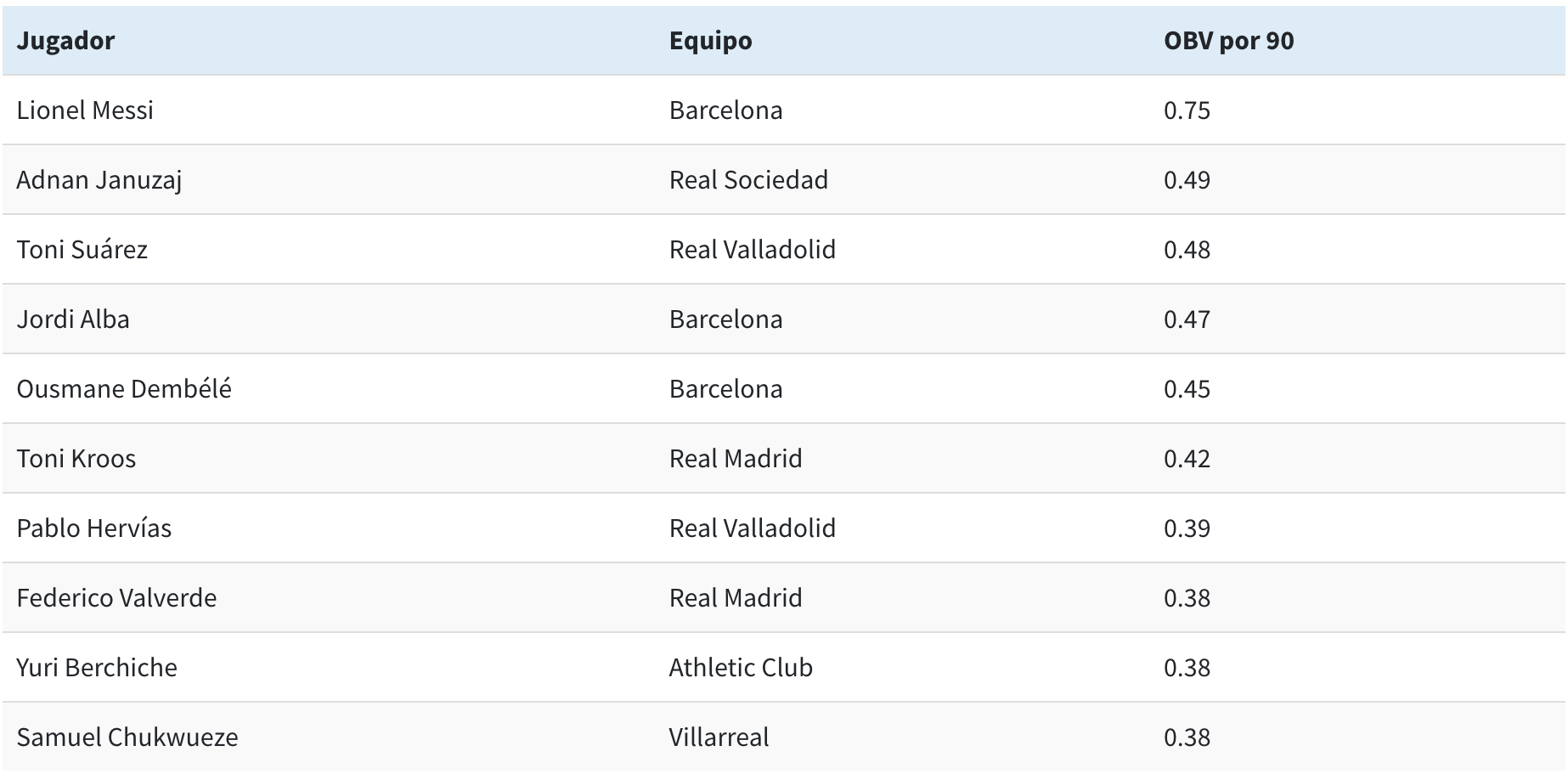
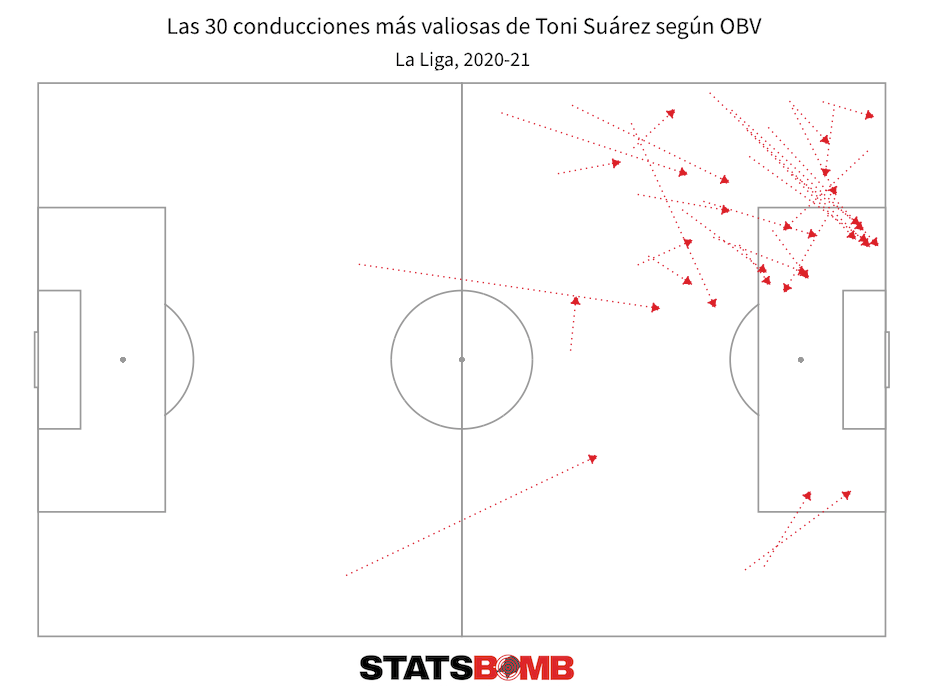
No es ninguna sorpresa que Messi agregara más valor que cualquier otro jugador de La Liga, pero hay otros nombres interesantes o quizás inesperados en la lista como Toni Suárez del Real Valladolid. Aparte de Messi, Suárez fue el jugador que agregó más valor mediante conducciones. Aquí son sus 30 conducciones más valiosas de la temporada.
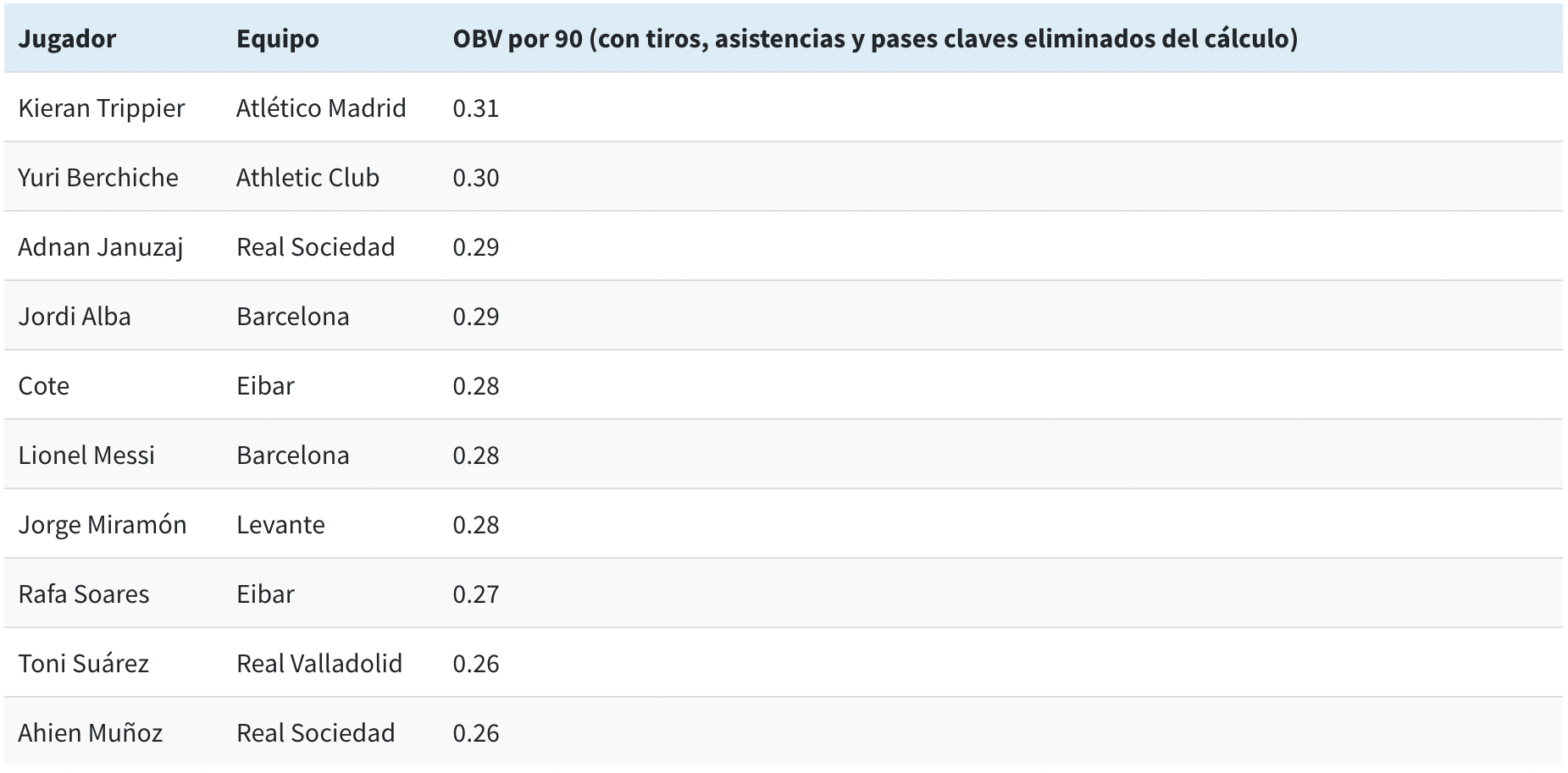
Tenemos la posibilidad de filtrar los resultados del modelo así para encontrar los jugadores que acumulan más OBV en distintos escenarios. Por ejemplo, si eliminamos del cálculo las acciones que tienen una relación directa con los tiros (los tiros en sí, las asistencias y los pases claves), otro nombres salen a relucir, sobre todo el de Kieran Tripper del Atlético Madrid.
Podemos filtrar por varias cosas: tipo de acción, localización en el campo, posición del jugador, etc... Aquí, echamos un ojo a los centrales que agregaron más valor con sus pases y conducciones en campo propio.
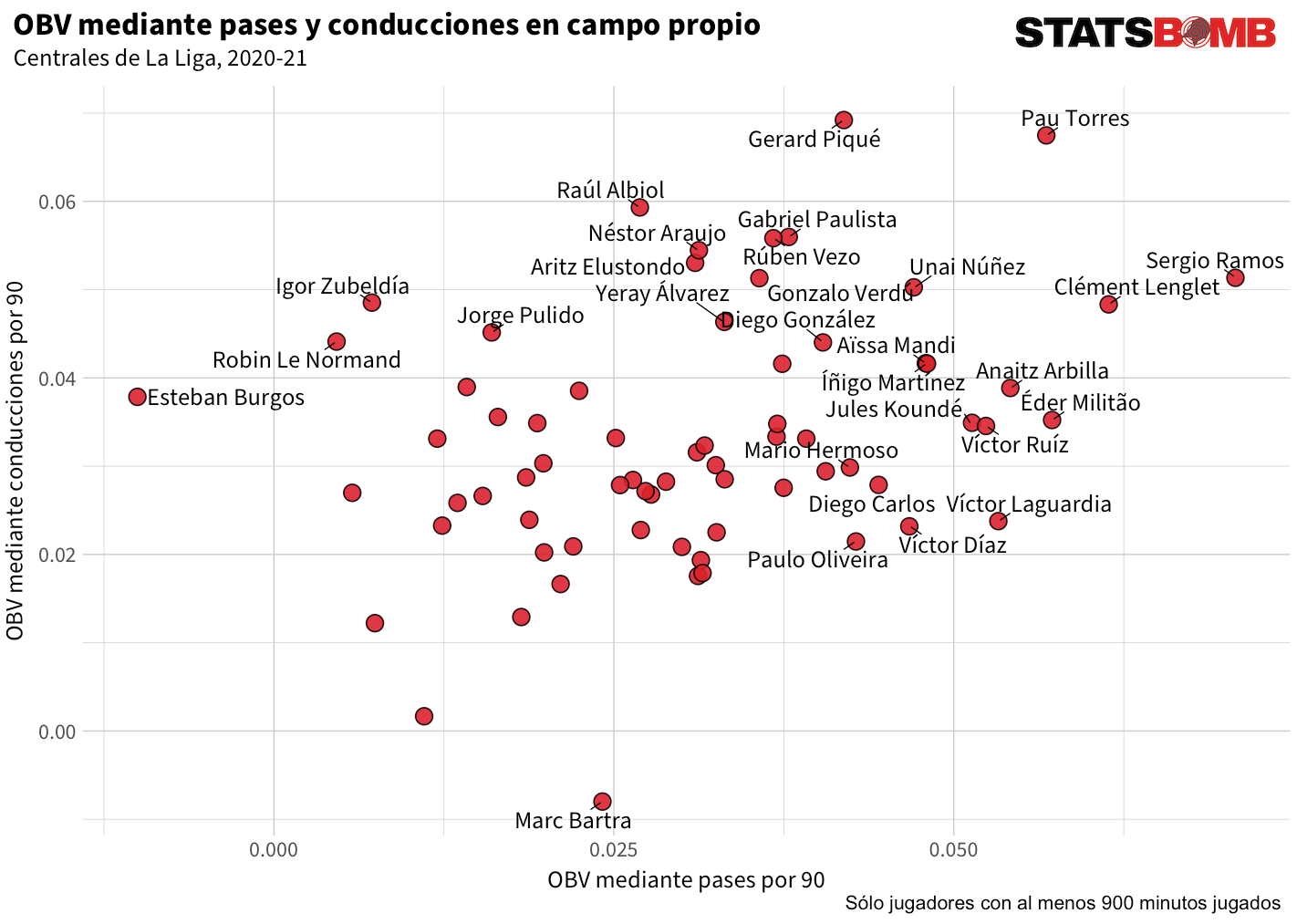
Sergio Ramos agregó más valor que cualquier otro central mediante pases, mientras que Gerard Piqué encabezó la lista en cuanto a conducciones. Pau Torres del Villarreal sobresalió en ambas acciones, sumando más OBV por 90 que cualquier otro central. Hemos marcado también a los dos centrales cuyas acciones tuvieron un efecto negativo: las conducciones en el caso de Marc Bartra del Real Betis y los pases en el de Esteban Burgos del Eibar.
OBV también proporciona un marco para poder empezar a evaluar el riesgo/recompensa en la toma de decisiones de los jugadores. Por ejemplo, podemos analizar a los jugadores que intentan más pases que mueven el balón más cerca de la portería en el último tercio del campo y ver la relación entre su porcentaje de acierto en estos pases y el valor de OBV por pase.
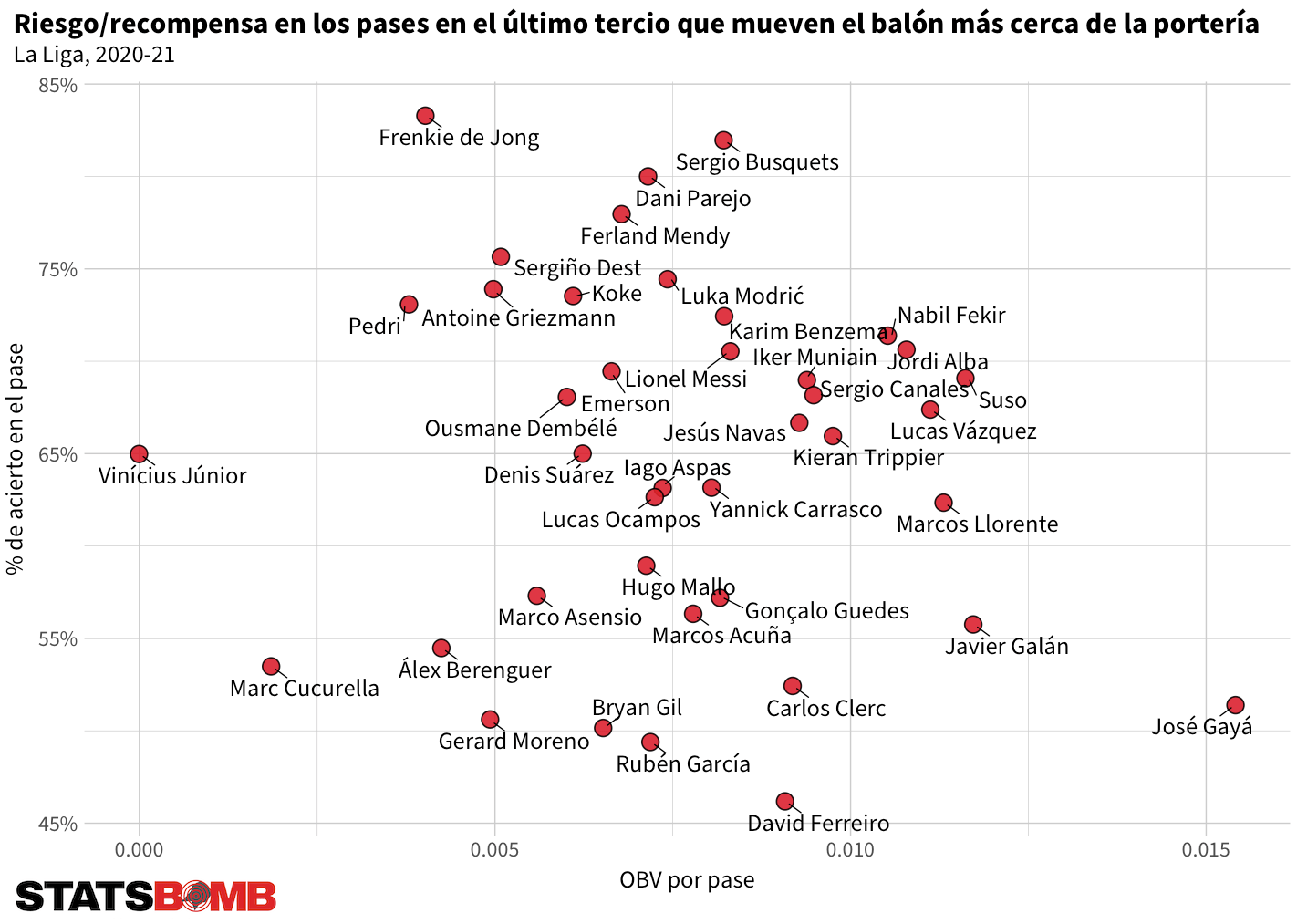
José Gayá del Valencia sobresale. Tiene un porcentaje de acierto bajo, de un 51.39%, pero el valor medio de sus pases, aun con los pases fallidos y sus correspondientes valores de OBV incluidos en el cálculo, es muy alto, lo que sugiere que agrega valor a pesar de su bajo porcentaje de acierto. Otros jugadores con porcentajes de acierto parecidos no aportan el mismo valor.
Vinícius Júnior es el único jugador entre los 40 que más pases de este tipo intentaron que tuvo un valor de OBV por pase negativo. Es decir que en suma sus pases de este tipo redujeron la posibilidad de que marcara el Real Madrid/aumentaron la posibilidad de que marcaran sus rivales.
El modelo también tiene utilidad en el análisis de equipos. Por ejemplo, podemos visualizar las zonas del campo desde las que generan más peligro respecto a la media de la liga.
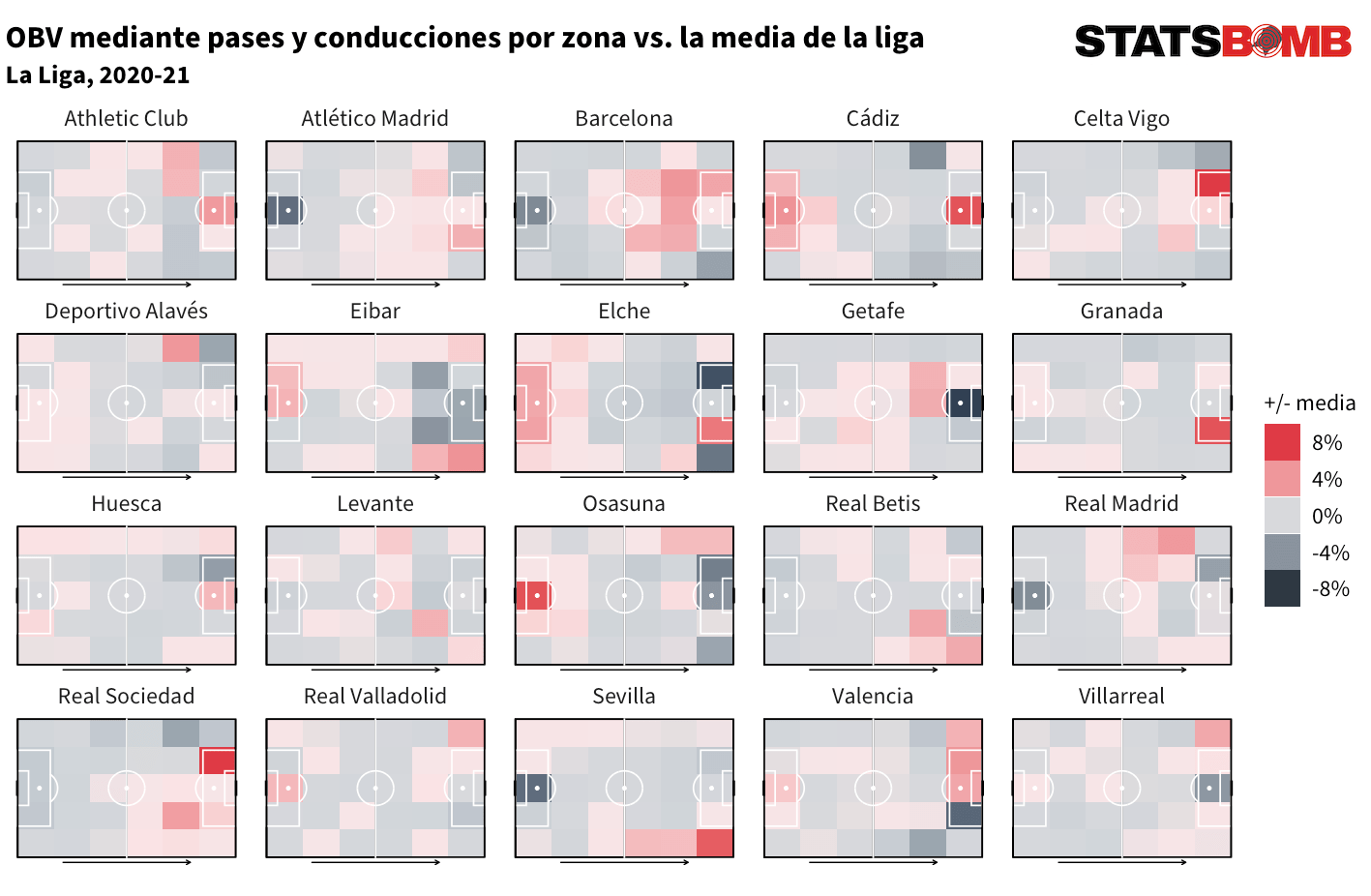
Así podemos ver que la temporada pasada, el Barcelona fue mucho más activo en zonas centrales del último tercio que otros equipos de La Liga. O que el Sevilla principalmente generó peligro por la banda derecha o que el Eibar jugó mucho por las bandas y casi nunca hizo daño a sus rivales desde zonas centrales o que el Cádiz y el Elche jugaron muy directo. En el gráfico se esconden muchas historias.
Asimismo, podemos emplear filtros para encontrar los equipos que acumularon más OBV, como un porcentaje de su total, por distintos tipos de acción:
- Pases altos: el Eibar, el Getafe y el Osasuna
- Conducciones: el Huesca, el Villarreal y el Athletic Club
- Pases al primer toque: el Eibar, el Levante y el Barcelona
- Intercepciones: el Granada, el Cádiz y el Osasuna
- Pases filtrados: el Villarreal, el Barcelona y el Celta Vigo
La mejor noticia es que OBV no es sólo para las grandes ligas de Europa. Este modelo de vanguardia está disponible en todas las más de 80 competiciones que cubrimos a lo largo del mundo. Podemos analizar las mismas cosas en La Liga que en la Liga MX de México...
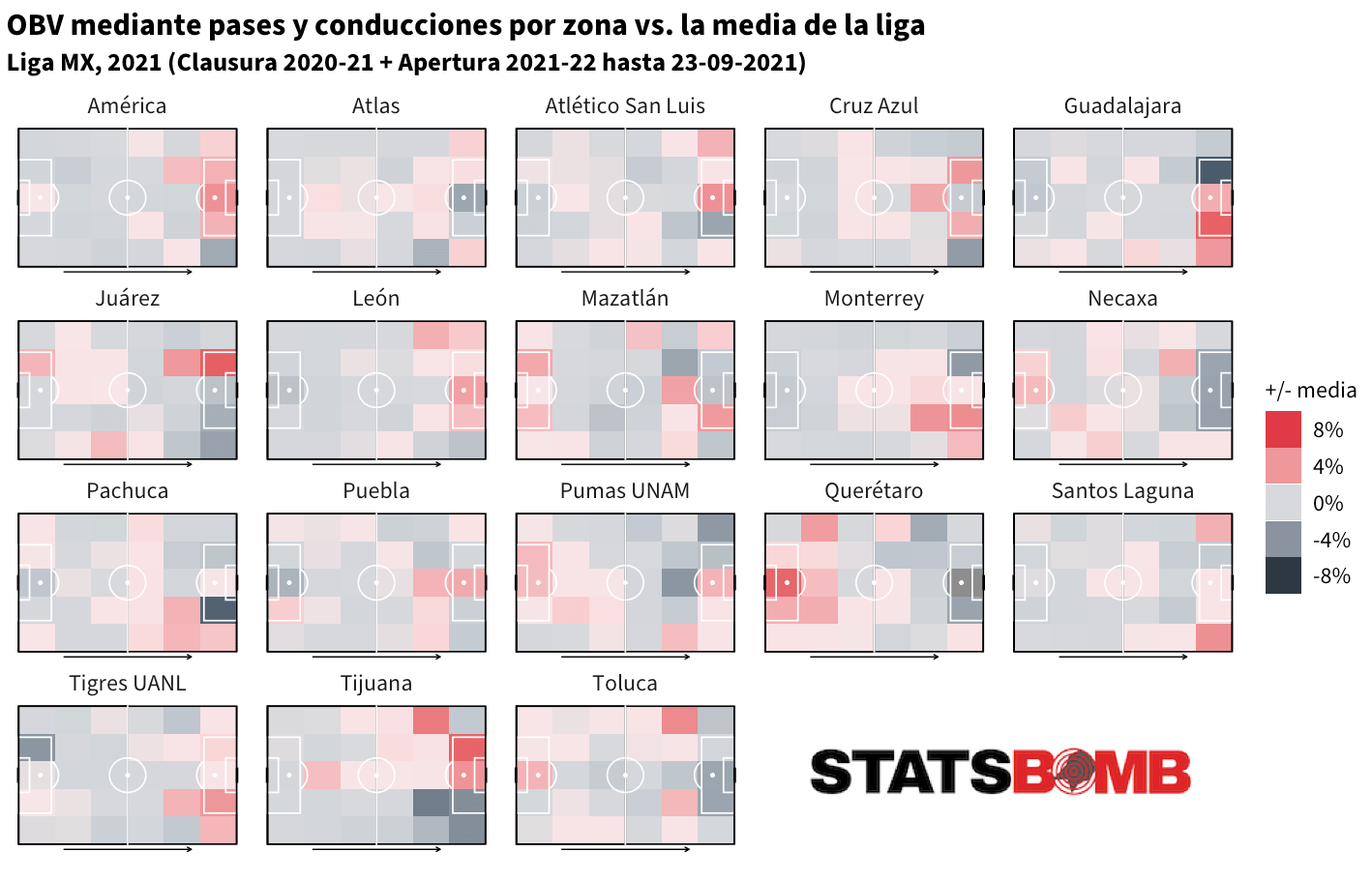
o la Primera División de Perú...
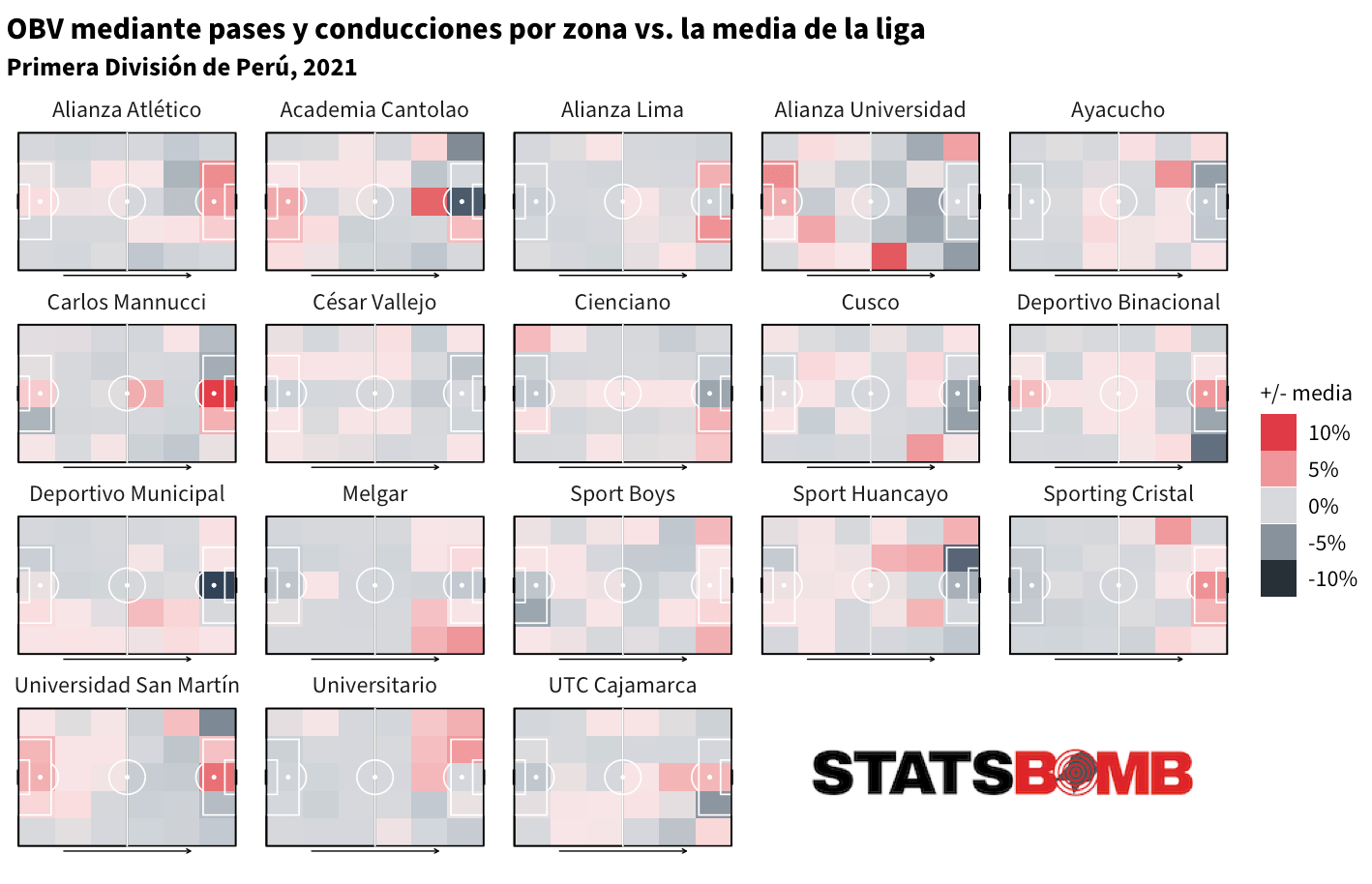
o incluso la J1 League de Japón.
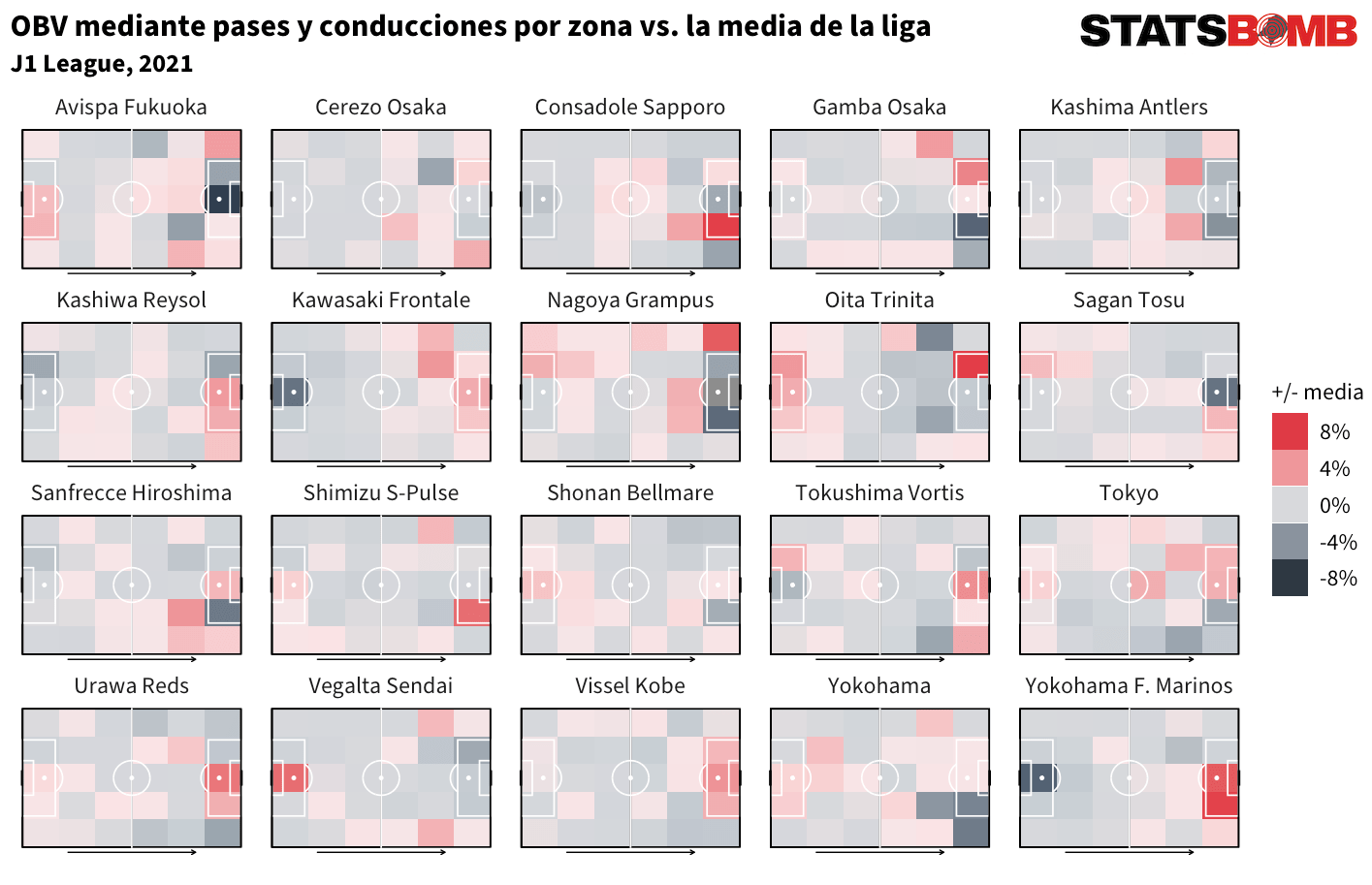
Tenemos muchas ganas de ver cómo nuestros clientes sacan provecho del modelo porque OBV abre muchas posibilidades de análisis, incluyendo muchas que aún están por descubrir. Y OBV es sólo la primera de muchas novedades que pronto llegarán a StatsBomb Data.
¿Quiere saber más? Un miembro de nuestro equipo de expertos le puede demostrar todas las ventajas de los datos de StatsBomb, los mejores y más detallados de la industria https://statsbomb.com/es/contact/

El fútbol siempre ha ido de números. La pura naturaleza del juego consiste en contar cosas, como qué equipo consigue más goles. Después de contar goles, se pasó a contar los remates, y con eso se pasó a medir la calidad de esos tiros. El siguiente paso obvio era tratar de medir la calidad de las ocasiones que precedían a esos tiros, y yendo más allá tratar de medir cómo el resto de acciones previas a la asistencia influyen en la calidad de las ocasiones posteriores. Existen diferentes tipos de modelos, a los cuales nos referimos en general como Possession Value, que tratan de medir el valor de cada acción en una posesión.
De manera sencilla, los modelos de Possession Value (en adelante PV) miden el cambio en la probabilidad de un equipo de marcar/conceder como resultado de una acción dada. Inicialmente, esto permite identificar las acciones más relevantes en una posesión (o cambios de estado más formalmente) y poder otorgar más mérito a las acciones con mayor impacto en la posesión. Esto también proporciona un marco para poder evaluar de manera apropiada el coste de oportunidad el riesgo/recompensa en la toma de decisiones de los jugadores (con balón). Por ejemplo, jugadores que asumen mucho riesgo en sus acciones tenderán a perder el balón más veces, pero el efecto neto de sus acciones puede ser positivo. El primer modelo público con datos de evento de PV es el de Sarah Rudd en 2012 -- cabe mencionar que Charles Reep en 1997 desarrolló un modelo seminal que podría ser considerado de PV.
En 2021, presentamos el nuestro: On-Ball Value (en adelante, OBV). Nuestros clientes ya tenían acceso a este modelo, ahora lo presentamos al público general. Existen numerosas razones por la que nuestra metodología y por ende los resultados que arroja el modelo representan una mejora respecto a modelos previos:
Nuestro modelo está entrenado con nuestro modelo de goles esperados, StatsBomb xG
Otros modelos utilizan los goles como muestra de entrenamiento. Emplear los xG para estimar los goles nos permite entrenar los modelos de manera más precisa con la misma cantidad de datos pero reduciendo la varianza y la “class imbalance” inherente a utilizar sólo los goles como variable dependiente. Existen otros enfoques que también emplean los xG, sin embargo, ninguno de ellos emplea los xG de StatsBomb, el modelo más preciso que existe.
Hemos optado por entrenar dos modelos diferentes para los componentes Goles Marcados y Goles Concedidos del modelo
Esto representa un enfoque distinto a la mayoría de los demás. Esto nos permite identificar el impacto de cada acción en la probabilidad de marcar y conceder de manera separada para así poder ver el efecto en la contribución ofensiva y defensiva de cada acción en lugar de utilizar simplemente el efecto neto (i.e. Diferencia de Goles).
Hemos decidido no otorgar mérito a los receptores de los pases
Mientras que es obvio que ser capaz de recibir y mantener la posesión en espacios reducidos, consideramos que depende en gran medida del movimiento sin balón. Esto es complicado de cuantificar con datos de evento.
Así, desde la perspectiva de la posición del balón y los datos de evento, no hay un valor intrínseco en la recepción que no esté mejor representado por la acción subsiguiente del receptor. Es decir, si no podemos cuantificar el movimiento previo, el valor de la recepción está representado por el valor de la acción que realiza el jugador.
Características relativas al estado de la posesión
Nuestra decisión ha sido incluir información relativa a la localización en el campo (coordinadas x/y, distancia y ángulo a portería, etc), contexto de la acción (balón parado, juego dinámico, etc) y si la acción se realizó bajo presión de un oponente (sí, esto también es una característica exclusiva de los datos de StatsBomb), entre otros. Sin embargo, hemos decidido a propósito no incluir información sobre la “historia de la posesión”.
Con esto nos referimos a información relativa a los eventos previos en la posesión. Es decir, no queremos que el modelo sepa qué ha ocurrido antes de la acción concreta que está evaluando. Mientras que esto puede parecer trivial tiene verdadera relevancia en la metodología - y como siempre que se trata de números y modelos el diablo está en los detalles - y por tanto en los resultados del modelo. Vamos a explicarlo: La información relativa a la historia de la posesión suele ser incluida con el argumento de que actúa como proxy de aspectos que no podemos tener de manera explícita en los datos de evento, por ejemplo la posición de los atacantes o de los oponentes. Sin embargo, en la práctica la gran mayoría de esta información se correlaciona de manera muy fuerte con el estilo de juego del equipo y con el “team strength” (el nivel global de los equipos).
Modelos previos empleando información de la historia de la posesión sobrevaloran los pases que se realizan en posesiones largas, dado que normalmente los mejores equipos tienen posesiones más largas que los equipos más débiles. Así, nuestro enfoque se asegura de que cada evento es evaluado de manera independiente al resto.
Bueno, ya vale explicaciones, vamos con algunos ejemplos
A continuación se pueden ver el Top 20 de las cinco grandes ligas desde la 2016-2017. Los números representan la diferencia de goles agregada de todas las acciones del jugador por cada 90 minutos en el campo.
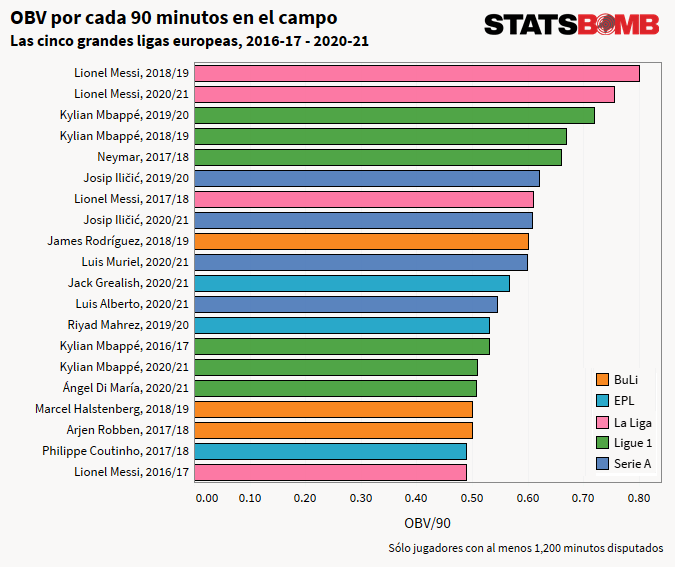
¿Lionel Messi encabeza la lista? Tick. ¿Neymar y Kylian Mbappé justo detrás? Tick. ¿Aritz Aduriz mejor rematador del mundo? Bueno, ningún modelo es perfecto...
Esto es sólo la puntuación global. Podemos ser mucho más específicos e ir al detalle dividiendo la contribución por tipo de acción. Aquí están los diez mejores jugadores en cuanto a OBV mediante conducciones en las cinco grandes ligas europeas la temporada pasada.
Anteriormente, podíamos analizar la cantidad y la longitud de las conducciones, así como las zonas del campo en las se realizaban, pero OBV nos permite asignar un valor más sutil a cada una de las conducciones y así formarnos una idea más clara de los jugadores que están generando valor con sus conducciones. Hay muchas más cosas que podemos hacer con los resultados de este nuevo modelo. Podemos separarlo por tipo de acción (conducción, pase, tiro, etc) o filtrar por posición para comparar a los jugadores en cada posición entre sí.
Incluso podemos hacer un análisis a nivel de equipos para encontrar respuestas a preguntas del tipo: ¿Desde qué zonas del campo están creando más valor? ¿Cuáles de sus pases son más valiosos? ¿Crean más valor mediante las conducciones o los pases? La mejor noticia es que este modelo de vanguardia está disponible en más de 80 competiciones a lo largo del mundo con el mismo nivel de detalle y precisión.
No todos los clubes del mundo tienen la capacidad de desarrollar in-house modelos de este tipo, por eso nos preocupamos de darles las herramientas necesarias para competir con los mejores. No podemos terminar sin reconocer el trabajo del equipo de Data Science de StatsBomb, no sólo por haber desarrollado este modelo sino porque este modelo es la primera de muchas novedades que pronto llegarán a StatsBomb Data.
Más >> On-Ball Value (OBV): Un análisis de La Liga 2020-21
¿Quiere saber más? Un miembro de nuestro equipo de expertos le puede demostrar todas las ventajas de los datos de StatsBomb, los mejores y más detallados de la industria https://statsbomb.com/es/contact/

Nuestra plataforma de análisis StatsBomb IQ está diseñada por y para analistas, con una serie de herramientas eficientes y potentes que permiten que los equipos accedan a la información que necesitan mientras ahorran una cantidad significativa de tiempo.
Como ejemplo de su utilidad, detallaremos un proceso de scouting de jugadores dentro de la plataforma.
Una de las ventajas de utilizar los datos en los primeros pasos de un proceso de scouting es que le da la posibilidad de reducir el mundo de futbolistas a un listado de jugadores interesantes en un rol determinado. Vamos a explorar dos maneras de crear un listado así con las herramientas que forman parte de StatsBomb IQ, pero primero, tenemos que crear una plantilla de radar personalizada que formará la base de nuestras búsquedas.
Los radares son el símbolo de StatsBomb, una manera original y práctica de visualizar datos tanto de jugadores como equipos. Podéis leer más sobre ellos aquí, pero en pocas palabras, muestran varias estadísticas y métricas que abarcan tanto el rendimiento como el estilo de juego de un jugador.
En StatsBomb IQ tenemos plantillas de radar estándares para cada posición en el campo: Porteros, centrales, laterales, centrocampistas / mediocampistas, extremos / mediapuntas y delanteros. Sin embargo, también existe la posibilidad de personalizar las estadísticas y métricas incluidas en los radares para crear una plantilla de radar personalizada que se ajuste mejor a lo que está buscando analizar y/o visualizar el usuario final.
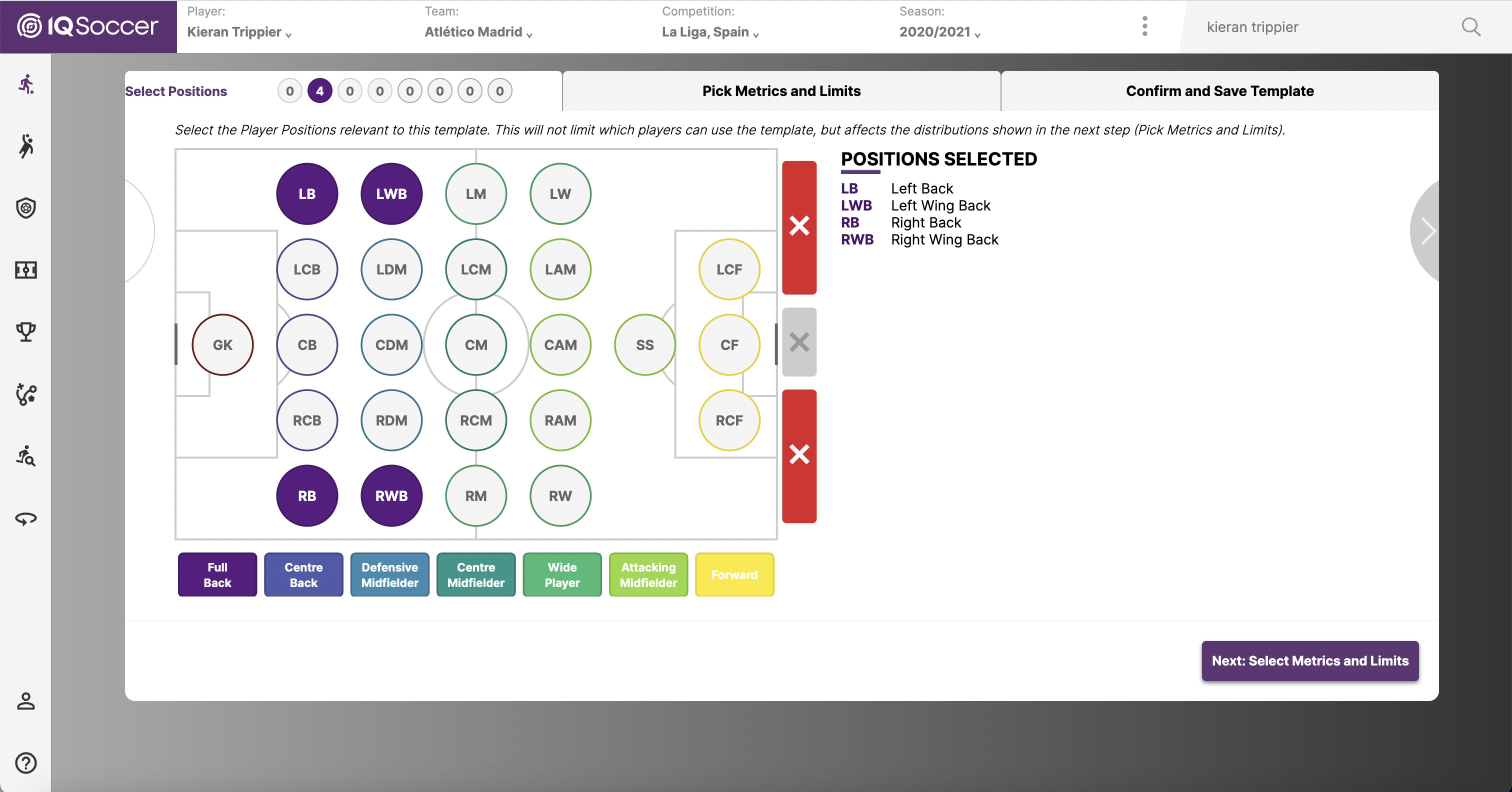
En este ejemplo, vamos a elegir a Kieran Trippier del Atlético Madrid campeón de La Liga como el perfil de lateral que estamos buscando.
Aquí está el radar de Trippier en la plantilla estándar de laterales.
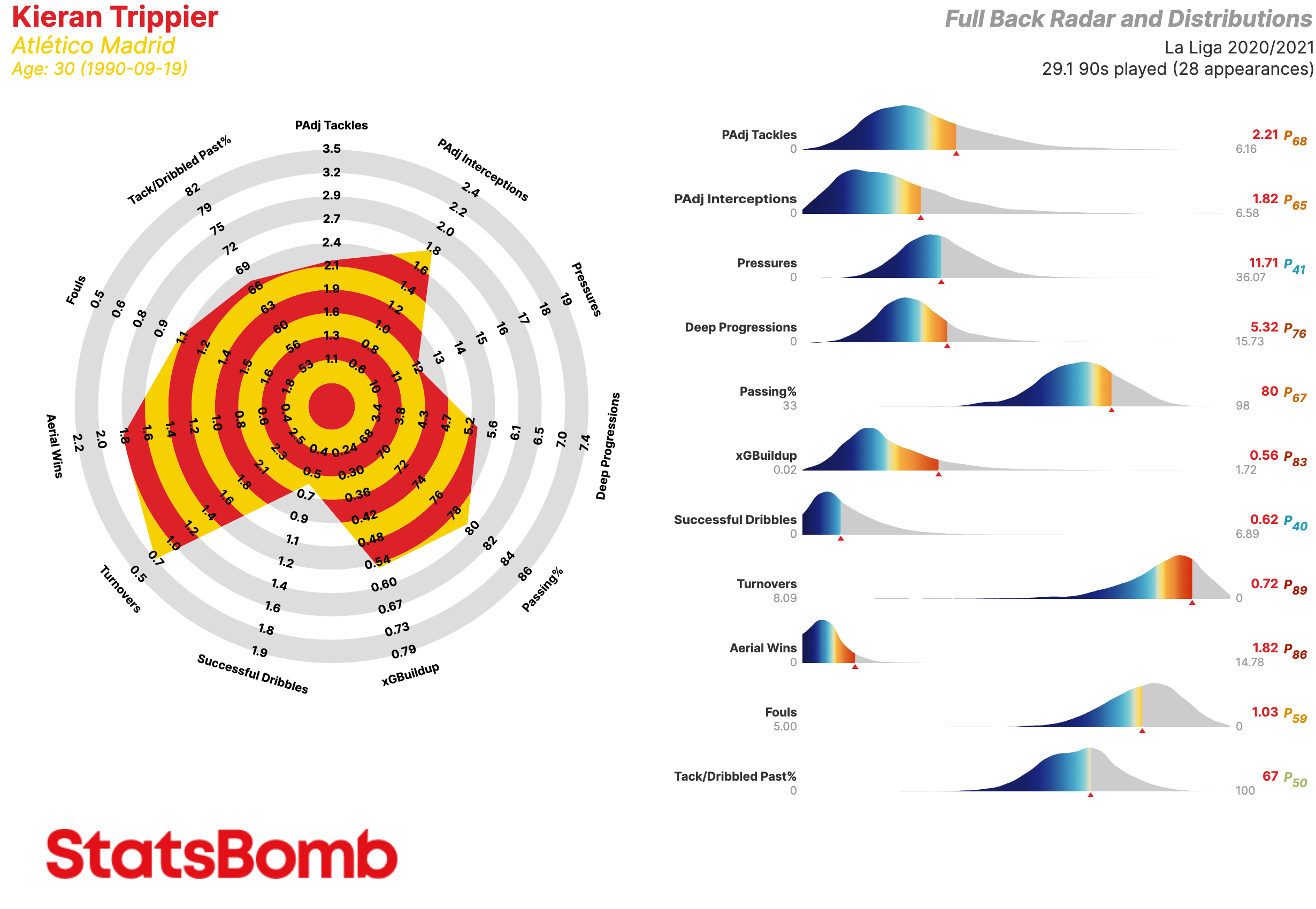
No es nada mal. Podemos observar que Trippier hace muchas de las cosas típicas de un lateral. Sin embargo, las estadísticas incluidas en este radar no cubren algunas de sus capacidades más destacables. Trippier es un jugador que tiene mucho peso en el avance del balón tanto al último tercio como al área y uno capaz de realizar una cantidad elevada de pases al área sin realizar muchos centros. Solo un 17% de sus pases completados al área son centros, lo que se sitúa en el percentil 93 respecto a los laterales de las cinco grandes ligas europeas.
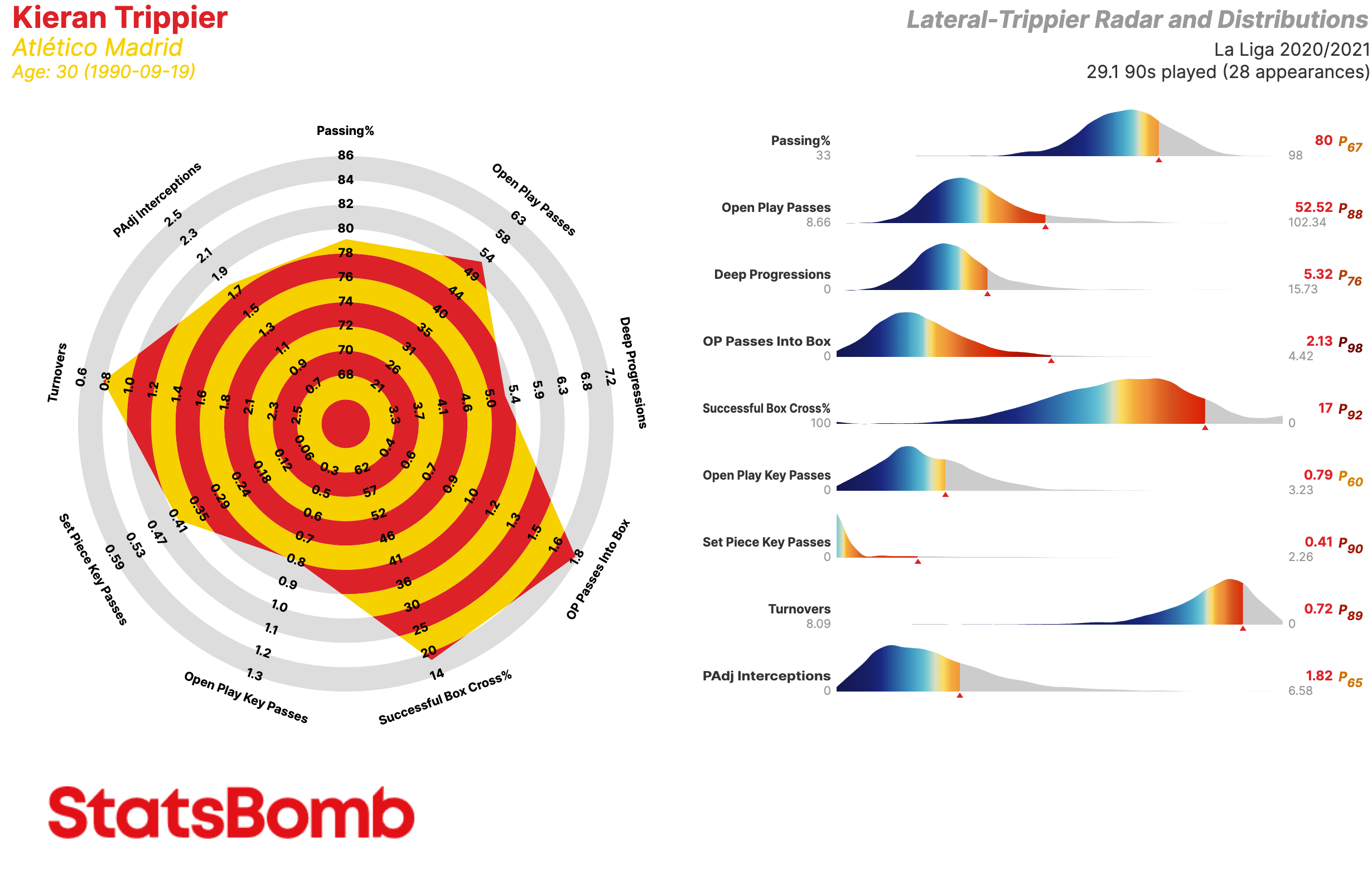
Vamos a construir un radar que mejor abarca sus características. Descartamos PAdj Tackles, Pressures, xGBuildup, Successful Dribbles, Aerial Wins, Fouls y Tack/Dribbled Past%, mantenemos PAdj Interceptions (intercepciones ajustadas en función de la posesión del equipo), Deep Progressions (incursiones en el último tercio mediante pases, regates o conducciones), Passing % (porcentaje de acierto en el pase) y Turnovers (perdidas de posesión a través de fallos en el control del balón o regates fallidos), y añadimos:
- Open Play Passes: La cantidad de pases intentados en juego dinámico
- OP Passes Into Box: La cantidad de pases completados al área en juego dinámico
- Successful Box Cross %: El porcentaje de los pases completados al área que son centros
- Open Play Key Passes: La cantidad de pases claves en juego dinámico
- Set Piece Key Passes: La cantidad de pases claves en las jugadas a balón parado
Ahora tenemos un radar que abarca mucho mejor las cualidades de Trippier.
Se puede guardar la plantilla y compartirla con colegas. Con la plantilla construida, podemos utilizarla como la base de los dos tipos de búsqueda que vamos a realizar.
1) Similar Player Search
Hemos explicado antes la utilidad de nuestra herramienta Similar Player Search, pero en resumen se trata de un algoritmo de similitud que produce una lista de jugadores con perfiles estadísticos similares al del jugador elegido como objetivo de búsqueda, clasificados en una escala de 0 a 100, siendo 100 una coincidencia exacta. Se pueden aplicar varios filtros. En este caso, aplicaremos los siguientes:
- Posición: Lateral derecho o carrilero derecho
- Edad: Sub-25
- Minutos jugados: Al menos 1200 minutos
- Temporadas: 2020, 2020-21 y 2021
- Competiciones: Todas las más de 80 competiciones que cubrimos
Ponemos en marcha el algoritmo y así son los resultados.
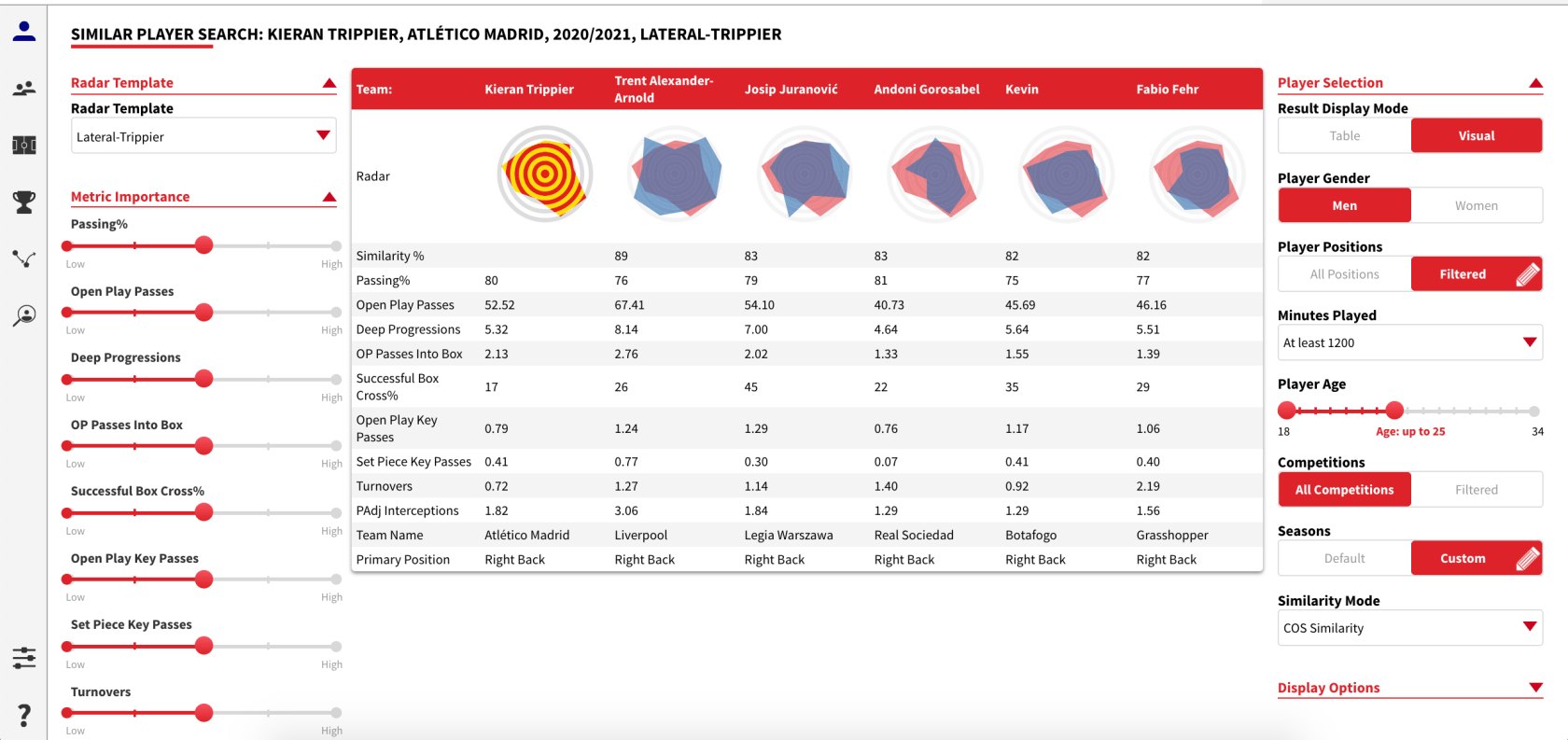
Parece un listado bueno. Trent Alexander-Arnold, otro lateral que tiene mucho peso en el avance del balón al ataque, aparece como el jugador más parecido a Trippier y hay otros nombres ahí que merecen más análisis.
Sin embargo, el algoritmo toma en cuenta todas las estadísticas incluidas en el radar y puede que queramos hacer la búsqueda de otra manera, estableciendo cifras mínimas para las estadísticas que consideramos más importantes. Para ella, tenemos IQ Scout.
2) IQ Scout
IQ Scout es una herramienta que funciona como una aplicación de scouting, permitiendo que los equipos exploren rápidamente todo el mundo de fútbol. Los datos de StatsBomb cubren más de 80 competiciones y cerca de 50,000 jugadores, así que existen muchas oportunidades de encontrar jugadores que se ajustan al perfil que busca el equipo.
Usaremos la plantilla de radar que ya hemos creado como base de búsqueda y mantendremos los mismos filtros que utilizamos en la búsqueda de jugadores similares. De ahí, seleccionamos las cuatro estadísticas que mejor sintetizan la capacidad de Trippier de avanzar el balón tanto al último tercio como el área, y elegimos las cifras mínimas que queremos establecer para cada una de ellas:
- Pases al área en juego dinámico: >=1.33 por 90
- Porcentaje de los pases completados al área que son centros: <=25%
- Incursiones en el último tercio: >=4.51 por 90
- Porcentaje de acierto en el pase: >=75%
Así producimos una lista de cinco jugadores que merecen un análisis más profundo.
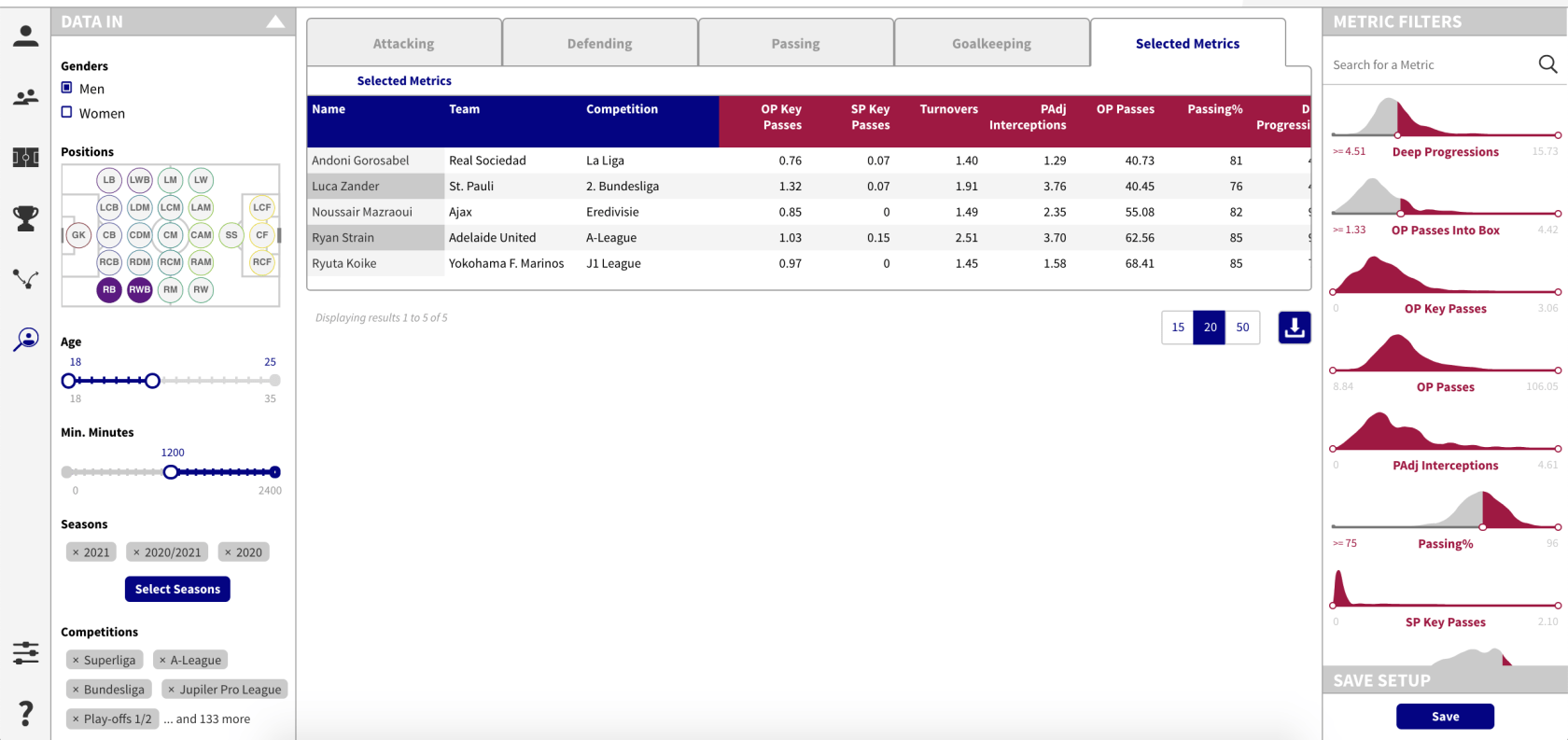
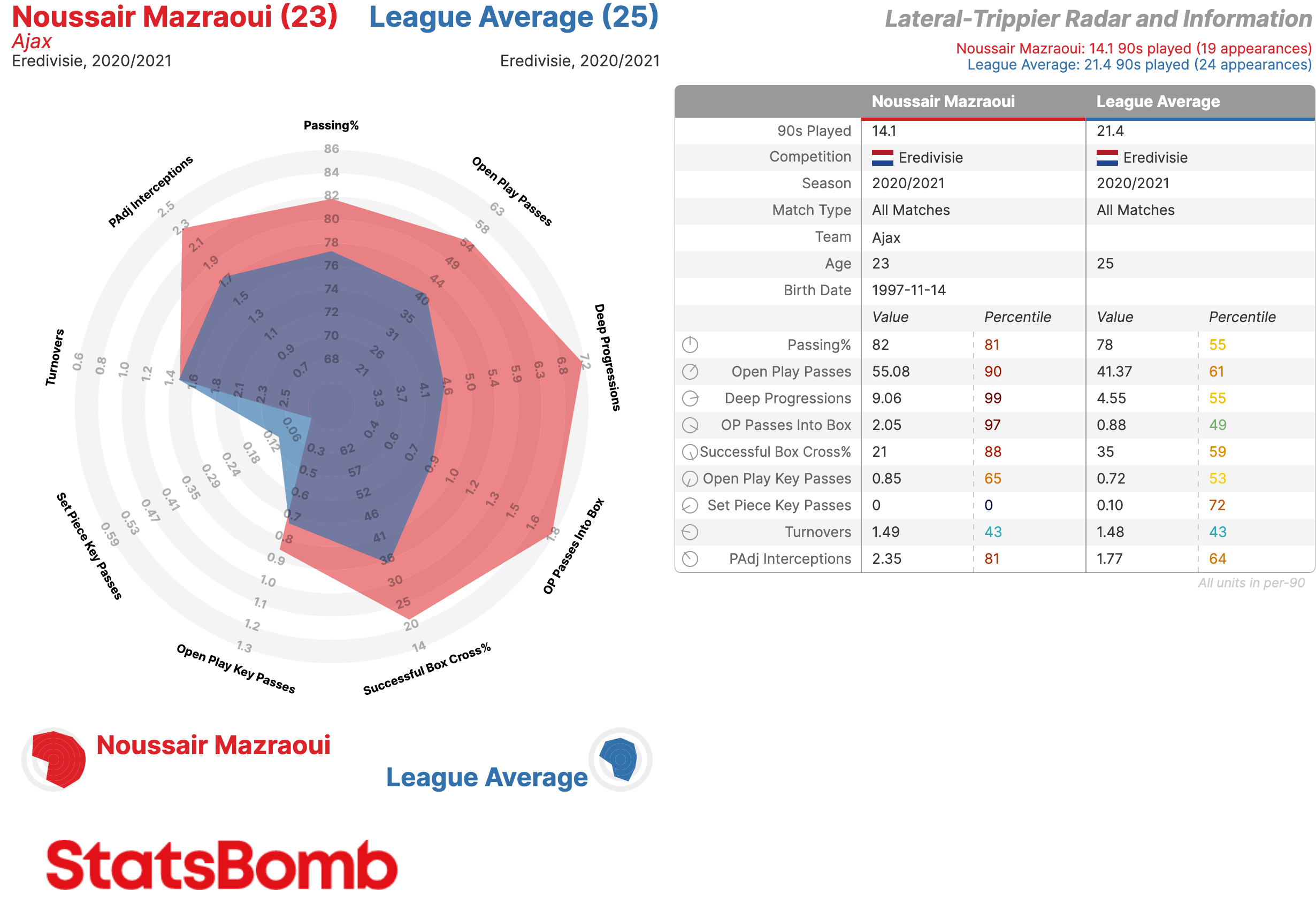
Andoni Gorosabel de la Real Sociedad aparece otra vez, mientras que Noussair Mazraoui del Ajax parece un jugador muy interesante si comparamos su producción con la media de los laterales de la Eredivisie en nuestro radar personalizado.
Esto ha sido un pequeño resumen de la utilidad de StatsBomb IQ en la identificación inicial de jugadores de interés. Nuestra plataforma también cuenta con las herramientas adecuadas para hacer el siguiente paso de un análisis más profundo de las características de los jugadores encontrados ya que tiene una gran variedad de estadísticas, métricas y visualizaciones altamente personalizables.
¿Quiere saber más sobre las posibilidades de StatsBomb IQ? Un miembro de nuestro equipo de expertos le puede demostrar todas las ventajas de StatsBomb IQ y de los datos de StatsBomb. Contacte con nosotros >>

La semana pasada analizamos las conducciones en La Liga a nivel de jugadores, resaltando los jugadores más involucrados en el avance del balón mediante esta acción. Esta semana vamos a echar un ojo a este aspecto del juego a nivel de equipos. ¿Hay equipos que confían mucho en las conducciones para llevar el balón hacia adelante, al último tercio o al área?
Este gráfico nos aporta una idea bastante clara de los equipos que utilizan mucho las conducciones para mover el balón hacia adelante. El campo está dividido en tercios verticales y cuartos horizontales. La tonalidad indica el porcentaje de las progresiones del balón del tercio inicial a los siguientes (o el siguiente en el caso del tercio medio) realizadas mediante conducciones, en lugar de pases, respeto a la media de la liga en cada zona.
Cabe mencionar que en todas las zonas, los pases representan la manera más habitual de avanzar el balón hacia adelante tanto de media como en el caso de equipos específicos.
Existen muchos casos interesantes. Hay equipos que no suelen utilizar las conducciones para avanzar el balón como el Alavés, el Eibar o sobre todo el Osasuna, otros que las utilizan mucho en casi todo el campo como el Barcelona o el Huesca y otros que las utilizan en algunas zonas, sean verticales o horizontales, y no en otras como el Betis, el Cádiz, el Getafe o el Sevilla.
En suma, el Huesca es el equipo que más a menudo avanza el balón de un tercio hacia adelante con las conducciones pero aún así se destaca su banda izquierda, donde juegan Javi Ontiveros y Javier Galán. Solo dos jugadores de La Liga ha ganado más metros en las conducciones por cada 90 minutos en el campo que Ontiveros (308.98m), mientras que Galán (233.39m por 90) también figura entre los 20 jugadores que más metros han ganado y está cuarto entre los laterales y carrileros.
Es fácil ver los equipos que habitualmente salen en corto, como el Barcelona, la Real Sociedad o el Villarreal. Estos equipos buscan generar ventajas para avanzar del tercio defensivo al tercio medio con el balón en los pies, algo que podemos ver claramente en las conducciones de los centrales del Villarreal, Pau Torres y Raúl Albiol.
El plot del Getafe tiene una forma particular, con un porcentaje por debajo de la media de conducciones en todas las zonas del campo salvo las dos zonas en el centro del mediocampo, pero una que tiene sentido dado el estilo de juego del equipo. El conjunto de José Bordalás busca avanzar el balón de forma directa y rápida, pero cuando un avance inicial no funciona, jugadores como Mauro Arambarri toman la iniciativa para progresar el balón de otra manera: las conducciones.
Es revelador comparar el gráfico de esta temporada con el de la 2019-20.
Hay equipos que muestra patrones recurrentes, como el Barcelona o la Real Sociedad, pero también muchos con formas muy diferentes, como el Villarreal, el Real Valladolid o el Osasuna. En la 2020-21, el Osasuna es el equipo que menos utiliza las conducciones para avanzar el balón, pero en la 2019-20, estuvo mucho más cerca de la media de la liga en la mayoría de las zonas e incluso superó la media por la banda izquierda, propiedad de Pervis Estupiñán, ahora del Villarreal.
El Sevilla es un caso similar. Jesús Navas sigue siendo un jugador que conduce mucho por la banda derecha, pero la manera de avanzar balón por la banda izquierda ha cambiado con la salida de Sergio Reguilón.
En la 2019-20, Navas y Reguilón fueron los primeros dos en el ranking de metros ganados mediante conducciones entre los laterales y carrileros. Marcos Acuña, el reemplazo de Reguilón, es más combinativo y menos de carreras largas. Para terminar, volveremos a la temporada actual y enfocarnos en las zonas de ataque, donde otra vez sobresalen el Huesca y el Osasuna. Respectivamente, son los equipos que más y menos veces en base porcentual progresa el balón al área de penalti mediante conducciones.
El Granada estuvo muy cerca de la media en todas las zonas del gráfico sobre el avance del balón del tercio defensivo al tercio medio y de allí al último tercio, pero es un equipo que utiliza mucho las conducciones para progresar el balón al área. Antonio Puertas, Darwin Machís y Luis Suárez son los jugadores más activos en estas acciones.
El caso del Alavés es muy parecido, mientras que el Valencia parece ser el ejemplo opuesto, un equipo que utiliza mucho las conducciones en el avance del balón hacia adelante pero no para incursionar en el área.
Las conducciones son una parte importante y quizás infra-analizada del fútbol, entonces vamos a echar un ojo a este aspecto del juego a través de una serie de dos artículos sobre las conducciones en La Liga española. La semana que viene las abarcaremos a nivel de equipos, pero esta vez nuestro enfoque será las conducciones a nivel de jugadores.
Como promedio, hay un poco más de 300 conducciones hacia adelante en un partido de La Liga española, con una media longitud de 9.40 metros. Es decir, en un partido promedio, las conducciones llevan el balón unos 2,800 metros hacia adelante.
¿Como se distribuyen estos metros entre las distintas posiciones? Este Violin Plot muestra la distribución de los metros avanzados mediante conducciones por posición, utilizando los datos de esta temporada y de la 2019-20. Cada plot visualiza la distribución y el rango de valores para la posición en cuestión. Los puntos negros marcan la media de cada una.

Como es de esperar, los porteros son los jugadores que menos avanzan el balón mediante conducciones, seguidos por los delanteros. Las medias de los centrales, los laterales/carrileros y los centrocampistas son casi iguales, aunque el rango de valores es más amplio en el caso de los centrales y los centrocampistas. Los extremos/mediapuntas son los futbolistas que ganan más metros mediante conducciones.
A nivel individual, hemos encontrado otro dato en el que Lionel Messi es el líder de La Liga, porque esta temporada ha sido el futbolista que ha avanzado el balón más metros mediante conducciones por cada 90 minutos en el campo: 364.19m por 90. Aquí, una lista de los que han llevado el balón más metros hacia adelante en las otras posiciones:
- Portero: David Soria, Getafe: 97.60m por 90
- Central: Pau Torres: 289.36m por 90
- Lateral/Carrilero: Yannick Carrasco, Atlético Madrid: 257.52m por 90
- Centrocampista: Frenkie de Jong, Barcelona: 331.13m por 90
- Delantero: Iago Aspas, Celta Vigo: 172.66m por 90
La longitud media de una conducción es 9.40 metros, pero existen varios ejemplos de conducciones muchas más largas. La más larga de todas esta temporada ha sido la de Jon Moncayola del Osasuna en un partido contra con el Elche en diciembre, una conducción desde su propio campo casi a la línea de fondo de unos 94 metros, diez veces la media. Aquí están algunas de las otras conducciones más largas de la temporada.
¿Qué jugadores son capaces de utilizar conducciones más largas que la media de la liga para avanzar el balón tanto el último tercio como el área?
Messi sobresale como el jugador que más veces hace llegar el balón el último tercio mediante estas conducciones, mientras que su compañero de equipo Ousmane Dembéle es el que más veces llega al área. Existen varias agrupaciones: los que principalmente atacan él area como Iago Aspas o Iñaki Williams; los que, más que nada, avanzan el balón del tercio medio como Iker Muniain, Pablo Hervías o Sergio Canales; y los que hacen ambas tareas como Messi, Dembéle, Vinícius Júnior, Yannick Carrasco o Samuel Chukwueze.
Entre todos los jugadores de La Liga, Vinícius Junior, del Real Madrid, es el que más a menudo en base porcentual utiliza conducciones (en lugar de pases) para avanzar el balón hacia adelante en campo contrario. Un 67.84% de los metros que ha ganado en campo contrario esta temporada han sido ganados mediante conducciones. Otro gráfico: conducciones de 10 metros o más que acaban en tiros o asistencias y/o pases claves.
Dos casos interesantes. Primero, el de Javi Ontiveros. Ha hecho casi dos veces más tiros tras estas conducciones que cualquier otro jugador de La Liga. Como hemos comentado antes, él extremo del Huesca es un jugador intensamente positivo. Es implacable en el avance del balón y también realiza muchos tiros, aunque muchos de ellos se realizan desde localizaciones que tienen menor probabilidad de gol.
Segundo, el de Jorge de Frutos.
El extremo de Levante consigue avanzar el balón a los metros finales del campo antes de dar asistencias y/o pases claves más a menudo que cualquier otro jugador de la división.

En los últimos años, la presión alta se ha convertido en un recurso utilizado tanto por clubes grandes como pequeños. Por ello, los entrenadores han tenido que buscar soluciones para contrarrestarla. En este artículo, vamos a analizar la reacción de los equipos de La Liga ante la presión alta y agresiva del Getafe.
El 17 de marzo en nuestro evento online StatsBomb Evolve presentaremos el nuevo salto adelante en los datos avanzados de fútbol con StatsBomb 360. En el periodo previo al evento, vamos a publicar una serie de artículos en los que explicamos la utilidad de algunos de los datos y métricas actualmente disponibles de StatsBomb, los más precisos y detallados de la industria.
En esta ocasión, vamos a hablar de nuestros datos exclusivos de presión. StatsBomb es el único proveedor de datos que recoge acciones de presión a nivel de tanto jugadores como equipos, permitiendo un análisis más profundo de este aspecto del juego que va más allá de los duelos individuales.
Con estos datos podemos ver las zonas del campo en las que los equipos realizan presión, tanto en un partido concreto...

...como en el transcurso de una temporada.

A nivel colectivo esto nos permite tener una visión más realista y completa de los mecanismos tácticos que los equipos usan en fase defensiva, en qué zonas comienzan a ejercer presión, hacia qué lado dirigen a los rivales, dónde son más fuertes, con qué frecuencia presionan en determinadas zonas del campo y muchos más aspectos clave defensivos.
Asimismo, podemos ver cómo los equipos se desenvuelven ante presión rival. Para cada acción relevante (pases, conducciones, tiros...) tenemos una variable llamada under_pressure que registra si la acción fue realizada bajo presión. Así, podemos filtrar nuestras búsquedas para que sólo aparezcan las acciones realizadas bajo presión del rival.
Vamos a analizar la reacción de los equipos en la pasada temporada de La Liga ante la presión en campo contrario del Getafe. Los azulones han sido menos activos y por ello menos efectivos esta temporada, pero en la 2019-20 el equipo de José Bordalás fue el equipo que realizó la presión más agresiva y adelantada de todas las grandes ligas de Europa.
Algunos equipos simplemente no tuvieron respuesta, el Alavés, por ejemplo. En el partido de julio de 2020, el equipo vasco no fue capaz de encontrar una manera fiable de mover el balón a campo rival. Sufrió un bajón notable respecto a su media de la temporada tanto en porcentaje de pases completados como en el porcentaje de pases completados bajo presión. No completó ninguno de los tres regates que intentó.
(Rojo = acción completada; amarillo = acción fallida).
El Alavés sólo realizó tres tiros en el transcurso de los 90 minutos con una suma de 0.19 goles esperados (xG). Dos de ellos provinieron de acciones a balón parado.
El Barcelona tuvo más éxito en romper la presión alta del Getafe, particularmente en el partido en el Coliseum Alfonso Pérez, en el que apostó por un juego más directo, con más balones largos de los que habitualmente realizan. Doce veces consiguió llegar a territorio rival desde acciones realizadas bajo presión en campo propio*.
* Para este propósito, hemos definido estas entradas en territorio rival como las acciones que tienen su punto de origen en campo propio con el poseedor de balón bajo presión y su punto final al menos 10 metros dentro del campo contrario.
El Barça generó tres de sus tiros en las tres acciones posteriores a un pase bajo presión en campo propio, incluyendo su primer gol de encuentro, marcado por Luis Suárez después de un pase largo del portero Marc-André ter Stegen.
El Sevilla también pareció tener un plan adecuado para contrarrestar la presión alta de los azulones. El equipo de Julen Lopetegui ganó ambos encuentros, por 3-0 y 2-0 respectivamente, y registró en esos partidos los porcentajes más altos de acciones bajo presión que llegaron directamente a territorio rival.

En el partido de casa, sacó mucho provecho de los regates para ganar metros en el campo y crear líneas de pase, un recurso que el Real Madrid y la Real Sociedad también utilizaron con éxito en sus respectivos encuentros contra el Getafe. El Madrid combinó los regates con muchos pases de primer toque. Realizó así un 20% de sus pases bajo presión.
Otros datos interesantes:
- El Real Betis, el Celta Vigo y el Valencia fueron los tres equipos que registraron los porcentajes más altos de pases al primer toque, principalmente con éxito en el caso del Betis y el Valencia, pero no en el caso del Celta Vigo, que completó menos de un 45% de sus pases bajo presión en el partido de julio 2020, la segunda peor cifra entre todos los equipos.
- El Granada fue el único equipo que registró una media de más de dos segundos entre el control del balón y el pase posterior.
- El Athletic Club fue el equipo con la media longitud de pase más larga y también uno de dos equipos, junto al Alavés, que bajo presión realizaron más pases altos que medios y rasos.
¿Hay una clave universal para contrarrestar la presión alta del Getafe?
La realidad es que en este caso no existe mucha correlación entre las variables que se puede analizar, como la dirección, la altura (otro dato exclusivo de StatsBomb) o la longitud de los pases, la longitud o la frecuencia de las conducciones, la cantidad de regates o el tiempo medio entre el control del balón y el pase posterior, y medidas de éxito como el porcentaje de acciones completadas bajo presión, la cantidad de llegadas a territorio rival o de acciones que preceden tiros.
El Getafe perdió todos los partidos contra los cinco mejores equipos de la clasificación: el Real Madrid, el Barcelona, el Atlético Madrid, el Sevilla y el Villarreal. Marco sólo dos goles y encajó 20. Sin embargo, no existieron muchas similitudes entre las soluciones que propusieron estos equipos. Esto parece confirmar que la mayoría de los entrenadores preparan su plan de juego mayormente en función de las capacidades de sus jugadores que en función del éxito que otros equipos han tenido o no con los planteamientos.
Este ha sido un ejemplo del tipo de análisis que se puede hacer únicamente con los datos de StatsBomb. Únete a nosotros el 17 de marzo para conocer el próximo avance de los datos en fútbol: StatsBomb Evolve.


Hace un mes, escribimos un artículo sobre la utilidad de la herramienta 'Similar Player Search' que forma parte de nuestra plataforma de análisis StatsBomb IQ. Hoy, nuestro tema es una herramienta que hemos desarrollado que da la posibilidad de buscar equipos similares: 'Similar Team Search'. La herramienta funciona de una manera muy parecida al 'Similar Player Search'. Se eligen un equipo como objeto de la búsqueda y un radar (de ataque, de defensa o personalizado) que aporta las métricas para incluir en el algoritmo. El sistema produce una lista de equipos con perfiles estadísticos similares, clasificados en una escala de 0 a 100, siendo 100 una coincidencia exacta.
Se trata de una poderosa herramienta que utiliza los datos de la amplia gama de competiciones del mundo que recogemos (más de 80 a partir de 2021), y que tiene varios casos de uso para los clubes, entre ellos:
- Reclutamiento de entrenadores: ¿Qué equipos tienen un planteamiento parecido al nuestro? ¿Quienes son sus entrenadores?
- Ideas tácticas: Equipo X presiona de manera muy similar a nosotros pero concede menos tiros. ¿Qué podemos aprender de su planteamiento?
- Fichajes: Equipo X tiene un estilo de juego parecido al nuestro. ¿Tiene algún jugador de interés?
Vamos a hacer algunos ejemplos utilizando radares personalizados que buscan identificar similitudes estilísticas más que de rendimiento.
Primero, un radar de ataque que busca capturar la manera en la que los equipos avanzan el balón y generan ocasiones. ¿Qué equipos se parecen al Manchester City, el máximo goleador de la Premier League la temporada pasada?
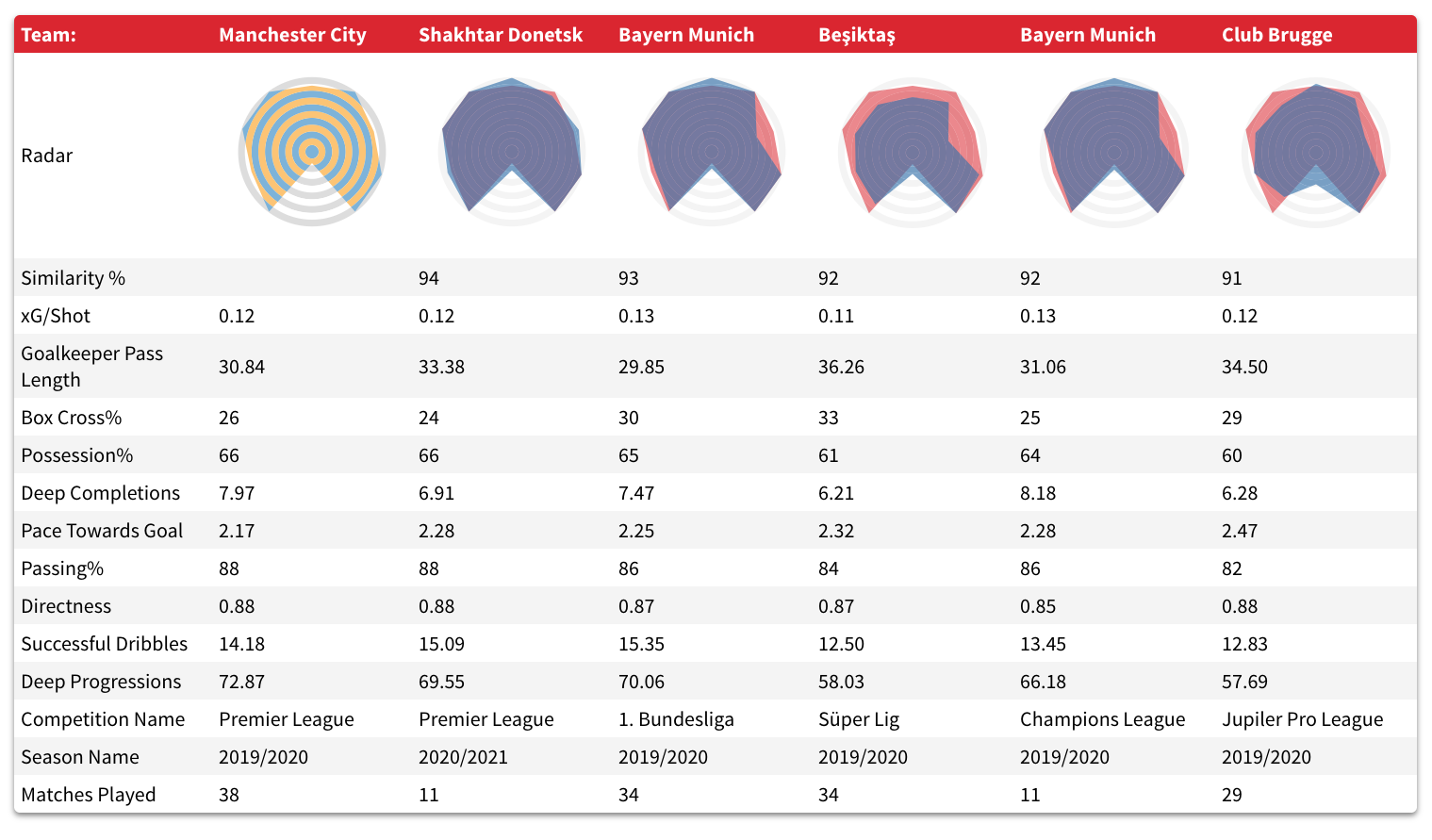
Parece una buena lista de equipos que dominan territorio y balón. Un poco más abajo se encuentran conjuntos como el PSV Eindhoven, el Crvena Zvezda y el Flamengo, este último entrenado hasta hace poco por el ex ayudante de Pep Guardiola en el City, Doménec Torrent.
Ahora vamos a centrarnos en el aspecto defensivo, más concretamente en la forma en la que presionan los equipos. Nuestro ejemplo en este caso es el Leeds de Marcelo Bielsa en su campaña de ascenso a la Premier League. Era un equipo que presionaba de forma agresiva en todo el campo y dificultaba mucho la llegada de sus rivales a zonas de peligro.
Entonces ¿qué equipos producen datos defensivos similares a los de ese Leeds?
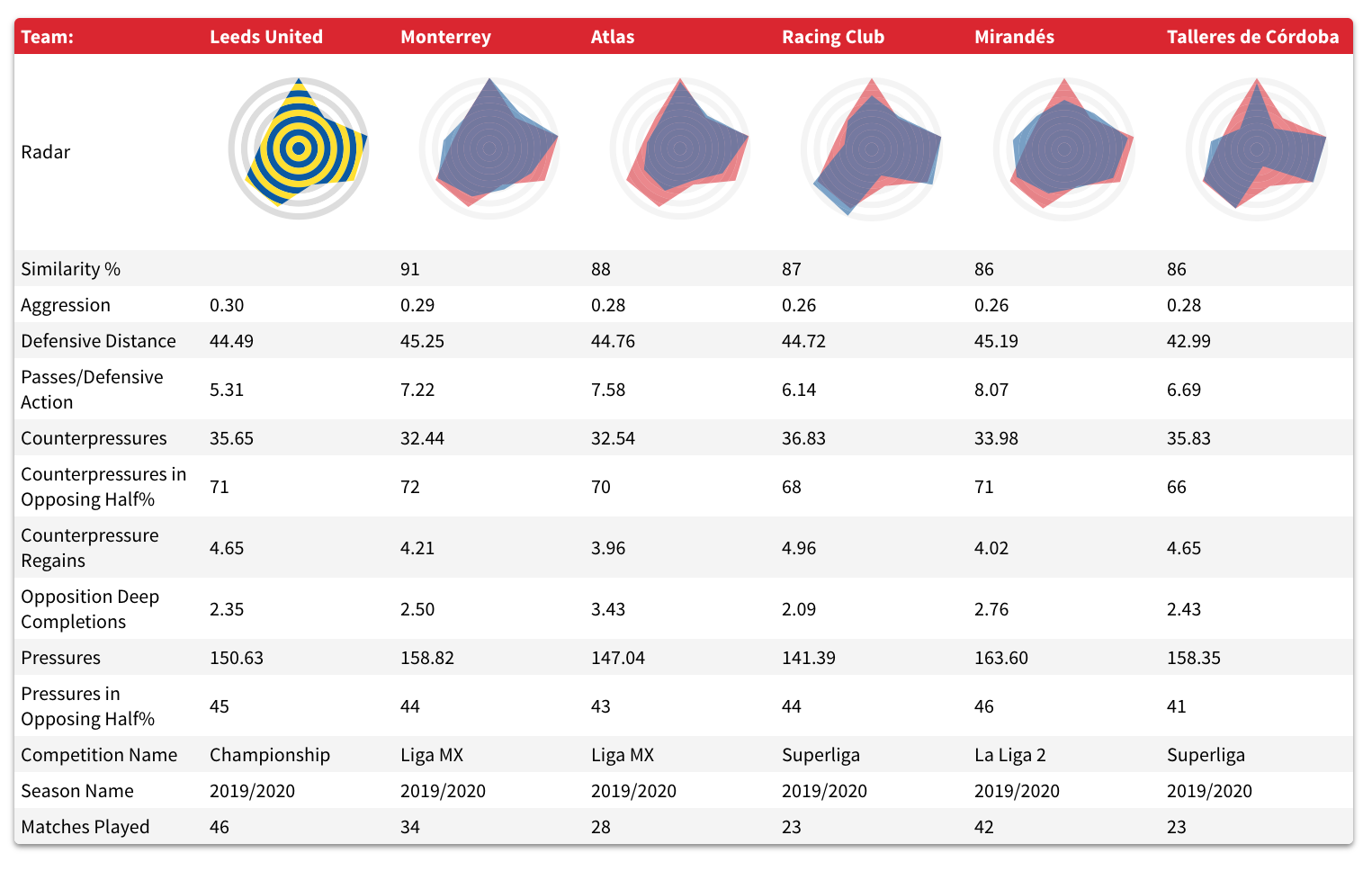
Los dos equipos más parecidos son de la Liga MX, el Monterrey y el Atlas, seguidos por dos equipos argentinos y el Mirandés de la segunda división española. ¿Esta lista podría ser un buen punto de partida para encontrar un eventual reemplazo para Bielsa?
Finalmente, tenemos un radar global que intenta capturar dónde y cómo defienden los equipos, y cómo y a qué ritmo hacen la transición entre defensa y ataque.
El Getafe parece un buen ejemplo, pues realiza una presión alta y agresiva pero no la combina con un alto porcentaje de posesión, como suele ser el caso con los equipos que presionan así, sino con un bajo porcentaje de posesión y ataques directos y rápidos. Si José Bordalás se marchara mañana, ¿quién sería capaz de mantener el planteamiento que le ha ayudado al Getafe a conseguir tres clasificaciones consecutivas entre los ocho mejores de la división desde su regreso a La Liga en 2017?
Pues... Diego Dabove del Argentinos Juniors parece una buena opción. No sólo es el Argentinos el equipo con el perfil estadístico más cercano al Getafe sino que además no habría ninguna barrera lingüística que superar.
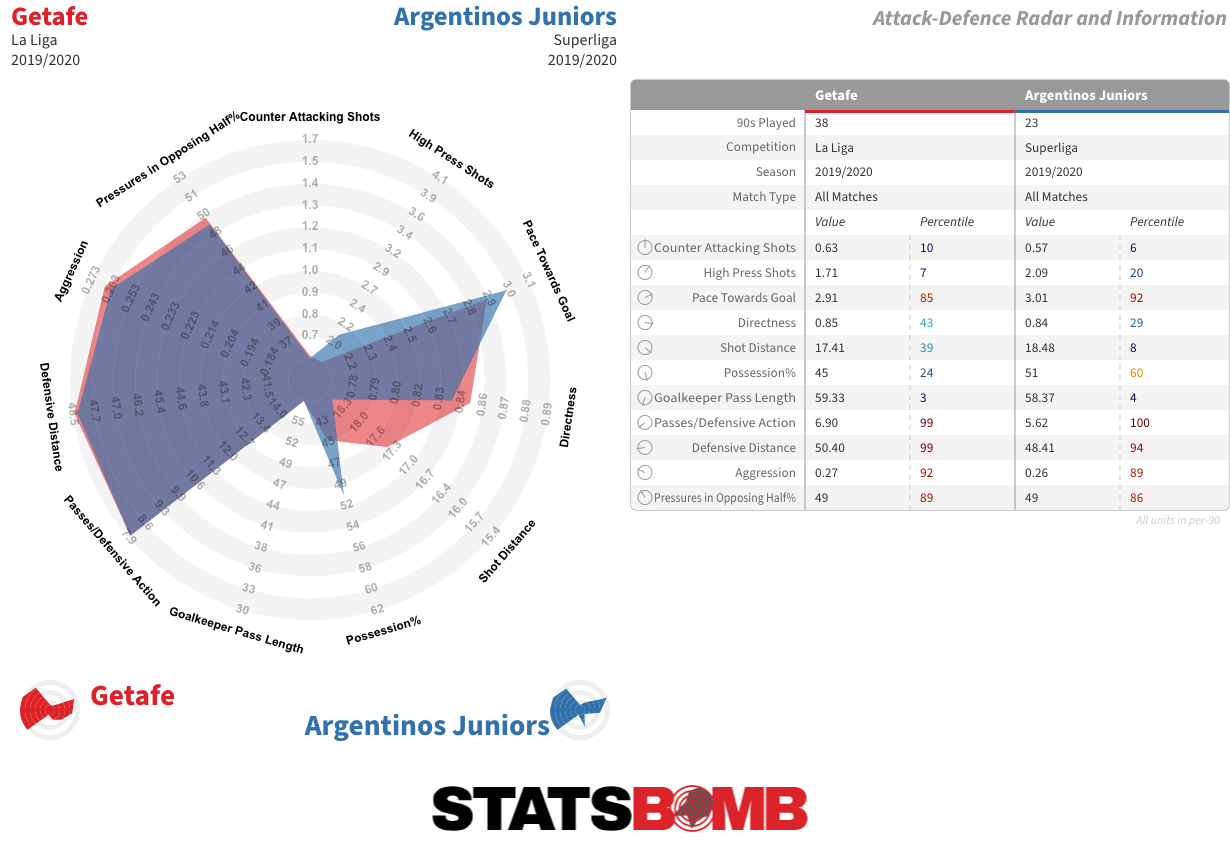
Otros equipos con perfiles estadísticos similares incluyen el Slovácko de la Liga Checa y el Barnsley de la Championship de Inglaterra.
Esto ha sido un rápido resumen del funcionamiento del 'Similar Team Search' en StatsBomb IQ. Con una amplia variedad de métricas para elegir, es una herramienta altamente personalizable y estamos seguros de que nuestros clientes la utilizarán en formas que no hemos concebido.
Actualmente estamos ofreciendo una prueba extendida de 14 días de nuestra plataforma de análisis StatsBomb IQ a clientes potenciales. Contacte con nosotros para más información.
Hace un par de meses, añadimos los datos del Barcelona de la temporada 2019-20 a nuestro repositorio de la carrera completa de Lionel Messi y la gente ya ha empezado a hacer cosas interesantes con ellos. Por ejemplo, Eoin O’Brien ha creado una página interactiva en la que puedes ver los redes de pases del Barça en cada partido de la temporada.
Ahora, vamos a enseñar algunas cosas que podéis hacer con estos datos en R, un programa y lenguaje de programación que solemos utilizar en nuestro trabajo de análisis. Ya hemos escrito una introducción al uso de StatsBomb Data en R y recomendamos que la leéis antes de intentar hacer las cosas incluidas en este artículo, que tiene como base un artículo en inglés por nuestro analista Euan Dewar.
Podéis hacer estas cosas con tanto los datos de Messi como los de las otras competiciones que ofrecemos de manera gratuita, incluyendo los últimos mundiales tanto masculino como femenino, la temporada de liga del mítico Arsenal de la 2003-04 y las ligas femeninas de Inglaterra y los Estados Unidos. Podéis encontrar una lista completa de las competiciones aquí.
Importar los datos
Primero, tenemos que importar los datos del Barcelona de la 2019-20:
library(tidyverse)
library(StatsBombR)
Comp <- FreeCompetitions() %>%
filter(competition_id==11 & season_name=="2019/2020")
Matches <- FreeMatches(Comp)
StatsBombData <- StatsBombFreeEvents(MatchesDF = Matches, Parallel = T)
StatsBombData = allclean(StatsBombData)
events = StatsBombData
Para crear visualizaciones es útil tener los nombres cortos de los jugadores en vez de sus nombres completos con segundo apellido, etc... Este código crea otra columna con este detalle ('player.nickname'):
lineups <- StatsBombFreeLineups(MatchesDF = Matches, Parallel = T)
lineups <- cleanlineups(lineups)
lineups <- lineups %>% mutate(player_nickname = ifelse(is.na(player_nickname), player_name, player_nickname))
lineups <- lineups %>% select(player.id = player_id, player.nickname = player_nickname) %>%
group_by(player.id) %>% slice(1) %>% ungroup()
events <- events %>% left_join(lineups)
Mapas de tiros
Bueno, ahora podemos crear un mapa de tiros de un jugador.
shots = events %>%
filter(type.name=="Shot" & (shot.type.name!="Penalty" | is.na(shot.type.name)) & player.nickname=="Luis Suárez") %>% #1 mutate(shot.body_part_ESP.name = recode (shot.body_part.name, "Right Foot" = "Pie derecho", "Left Foot" = "Pie izquierdo", "Head" = "Cabeza")) #2
shotmapxgcolors <- c("#192780", "#2a5d9f", "#40a7d0", "#87cdcf", "#e7f8e6", "#f4ef95", "#FDE960", "#FCDC5F", "#F5B94D", "#F0983E", "#ED8A37", "#E66424", "#D54F1B", "#DC2608", "#BF0000", "#7F0000", "#5F0000") #3
ggplot() +
annotate("rect",xmin = 0, xmax = 120, ymin = 0, ymax = 80, fill = NA, colour = "black", size = 0.6) +
annotate("rect",xmin = 0, xmax = 60, ymin = 0, ymax = 80, fill = NA, colour = "black", size = 0.6) +
annotate("rect",xmin = 18, xmax = 0, ymin = 18, ymax = 62, fill = NA, colour = "black", size = 0.6) +
annotate("rect",xmin = 102, xmax = 120, ymin = 18, ymax = 62, fill = NA, colour = "black", size = 0.6) +
annotate("rect",xmin = 0, xmax = 6, ymin = 30, ymax = 50, fill = NA, colour = "black", size = 0.6) +
annotate("rect",xmin = 120, xmax = 114, ymin = 30, ymax = 50, fill = NA, colour = "black", size = 0.6) +
annotate("rect",xmin = 120, xmax = 120.5, ymin =36, ymax = 44, fill = NA, colour = "black", size = 0.6) +
annotate("rect",xmin = 0, xmax = -0.5, ymin =36, ymax = 44, fill = NA, colour = "black", size = 0.6) +
annotate("segment", x = 60, xend = 60, y = -0.5, yend = 80.5, colour = "black", size = 0.6)+
annotate("segment", x = 0, xend = 0, y = 0, yend = 80, colour = "black", size = 0.6)+
annotate("segment", x = 120, xend = 120, y = 0, yend = 80, colour = "black", size = 0.6)+
theme(rect = element_blank(),
line = element_blank()) +
annotate("point", x = 108 , y = 40, colour = "black", size = 1.05) +
annotate("path", colour = "black", size = 0.6, x=60+10*cos(seq(0,2*pi,length.out=2000)), y=40+10*sin(seq(0,2*pi,length.out=2000)))+
annotate("point", x = 60 , y = 40, colour = "black", size = 1.05) +
annotate("path", x=12+10*cos(seq(-0.3*pi,0.3*pi,length.out=30)), size = 0.6, y=40+10*sin(seq(-0.3*pi,0.3*pi,length.out=30)), col="black") +
annotate("path", x=107.84-10*cos(seq(-0.3*pi,0.3*pi,length.out=30)), size = 0.6, y=40-10*sin(seq(-0.3*pi,0.3*pi,length.out=30)), col="black") +
geom_point(data = shots, aes(x = location.x, y = location.y, fill = shot.statsbomb_xg, shape = shot.body_part_ESP.name), size = 6, alpha = 0.8) + #4
theme(axis.text.x=element_blank(),
axis.title.x = element_blank(),
axis.title.y = element_blank(),
plot.caption=element_text(size=13,family="Source Sans Pro", hjust=0.5, vjust=0.5),
plot.subtitle = element_text(size = 18, family="Source Sans Pro", hjust = 0.5),
axis.text.y=element_blank(), legend.position = "top",
legend.title=element_text(size=18,family="Source Sans Pro"),
legend.text=element_text(size=16,family="Source Sans Pro"),
legend.margin = margin(c(15, 30, -60, 10)), legend.key.size = unit(1.5, "cm"),
legend.key.width = unit(0.95, "cm"),
plot.title = element_text(margin = margin(r = 10, b = 10), face="bold",size = 26, family="Source Sans Pro", colour = "black", hjust = 0.5),
legend.direction = "horizontal",
axis.ticks=element_blank(),
aspect.ratio = c(65/100),
plot.background = element_rect(fill = "white"),
strip.text.x = element_text(size=13,family="Source Sans Pro")) +
labs(title = "Luis Suárez, Mapa de tiros", subtitle = "La Liga, 2019-20") + #5
scale_fill_gradientn(colours = shotmapxgcolors, limit = c(0,0.8), oob=scales::squish, name = "Valor de xG") + #6
scale_shape_manual(values = c("Cabeza" = 21, "Pie derecho" = 23, "Pie izquierdo" = 24), name ="") + #7
guides(fill = guide_colourbar(title.position = "top"),
shape = guide_legend(override.aes = list(size = 5, fill = "black"))) + #8
coord_flip(xlim = c(85, 125)) #9
1. Un filtro básico para eliminar los penaltis y elegir el jugador que quieras.
2. Para asignar los nombres castellanos a las partes del cuerpo.
3. Los colores para los valores de xG.
4. Empezamos a trazar los tiros con geom_point. Elegimos el valor de xG como la fill y la parte del cuerpo como la shape (forma) de los puntos. Se pueden cambiarlos por otros valores, como el tipo de asistencia, el resultado del tiro (gol, a puerta, bloqueado...), etc...
5. Para poner el título y subtítulo a la visualización.
6. Los parámetros para la fill de los tiros. En el parámetro colours, hacemos referencia a los colores que elegimos antes.
7. Para elegir las formas para cada parte del cuerpo. Los números son los números asignados a las formas estándares de ggplot. Una lista aquí. Las formas de 21 en adelante son los que tienen colores interiores (controlados por fill).
8. Con guides() podemos ajustar la forma, el color y otras cosas de la leyenda. En este ejemplo, estamos cambiando la posición del título de la fill para situarlo por encima de la leyenda. Asimismo, estamos cambiando el tamaño y color de las formas.
9. coord_flip() cambia los ejes para mostrar el campo de juego de forma vertical. Con xlim podemos poner un límite al eje x para mostrar sólo una parte del campo.
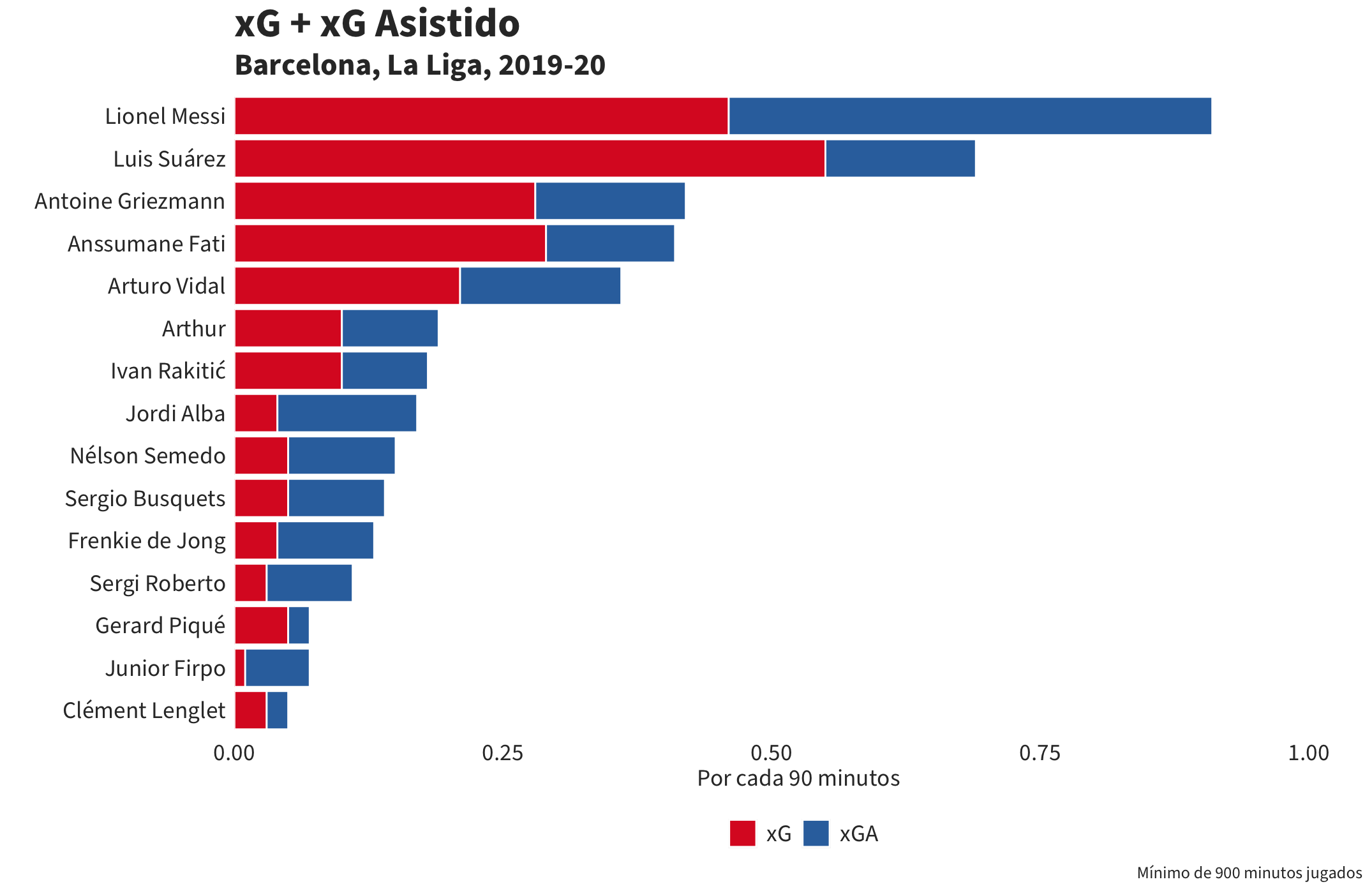
El resultado será esta visualización:
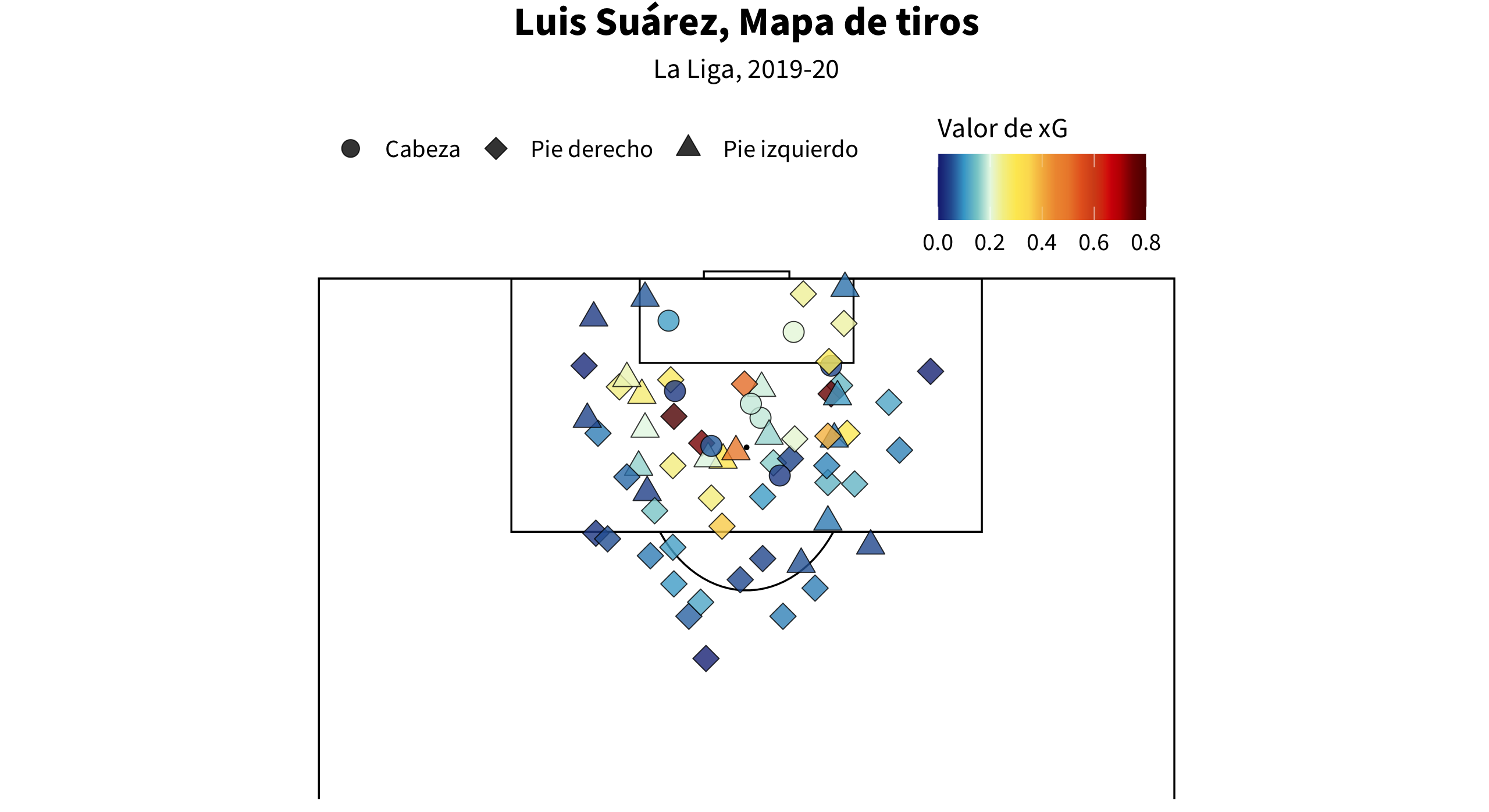
xG + xG Asistido
No existe una columna para los valores de xG asistido en nuestros datos pero es algo que podemos generar si conectamos el valor de xG de un tiro a la pase que creó la ocasión usando la función join.
Aquí está el código:
xGA = events %>%
filter(type.name=="Shot") %>% #1
select(shot.key_pass_id, xGA = shot.statsbomb_xg) #2
shot_assists = left_join(events, xGA, by = c("id" = "shot.key_pass_id")) %>% #3
select(team.name, player.nickname, player.id, type.name, pass.shot_assist, pass.goal_assist, xGA ) %>%
filter(pass.shot_assist==TRUE | pass.goal_assist==TRUE) #4
1. Filtrando a los tiros, los únicos eventos que tienen valores de xG.
2. Con Select() podemos elegir las columnas que queremos incluir en el Data Frame. Elegimos la columna 'shot.key_pass_id', una variable de los tiros que da la ID de la pase que creó el tiro. Asimismo, renombramos la columna 'shot.statsbomb_xg' a 'xGA' para que ya tenga el nombre correcto cuando la juntamos con las pases.
3. left_join() es una función para combinar las columnas de dos Data Frames diferentes. En este ejemplo, estamos juntado nuestro Data Frame inicial (‘events’) y el que hemos creado (‘xGA’). La clave es la parte by = c(“id” = “shot.key+pass_id) que junta los dos Data Frames cuando la columna de ID en ‘events’ coincide con la columna ‘shot.key_pass_id’ en ‘xGA’. Ahora, la columna ‘xGA’ muestra el valor de xG de cada pase clave y asistencia.
4. Filtrando los datos a las pases claves y asistencias. El resultado debería ser algo así:
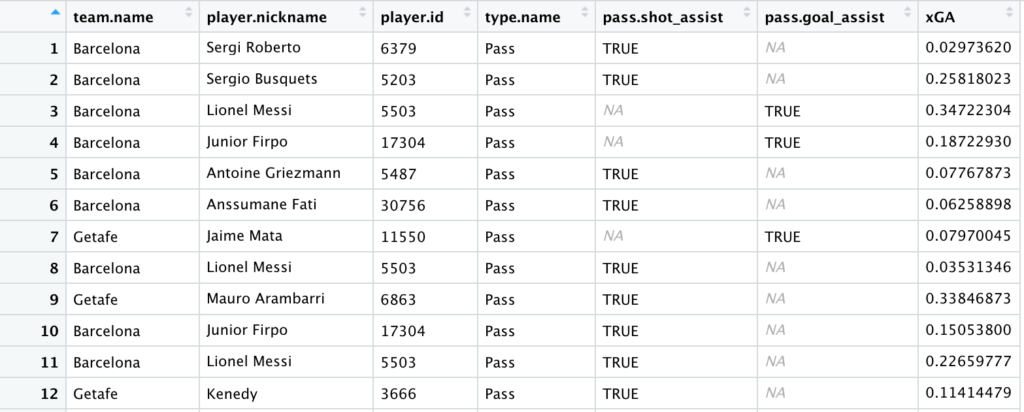
Todo bien hasta ahora. ¿Pero qué tenemos que hacer para crear un gráfico de estos datos? Por ejemplo, un ranking de jugadores que incluye tanto el xG como el xGA.
player_xGA = shot_assists %>%
group_by(player.nickname, player.id, team.name) %>%
summarise(xGA = sum(xGA, na.rm = TRUE)) #1
player_xG = events %>%
filter(type.name=="Shot") %>%
filter(shot.type.name!="Penalty" | is.na(shot.type.name)) %>%
group_by(player.nickname, player.id, team.name) %>%
summarise(xG = sum(shot.statsbomb_xg, na.rm = TRUE)) %>%
left_join(player_xGA) %>%
mutate(xG_xGA = sum(xG+xGA, na.rm =TRUE) ) #2
player_minutes = get.minutesplayed(events)
player_minutes = player_minutes %>%
group_by(player.id) %>%
summarise(minutes = sum(MinutesPlayed)) #3
player_xG_xGA = left_join(player_xG, player_minutes) %>%
mutate(nineties = minutes/90,
xG_90 = round(xG/nineties, 2),
xGA_90 = round(xGA/nineties,2),
xG_xGA90 = round(xG_xGA/nineties,2) ) #4
chart = player_xG_xGA %>%
filter(minutes>=900)
chart<-chart %>%
select(1, 9:10)%>%
pivot_longer(-player.nickname, names_to = "variable", values_to = "value") %>%
filter(variable=="xG_90" | variable=="xGA_90") #6
1. Agrupando los datos por jugador y calculando sus totales de xGA para la temporada.
2. Eliminando los penaltis, calculando los totales de xG para cada jugador y sumando el xG y xGA para crear una nueva columna con la suma de los dos.
3. Una función para importar los minutos disputados de cada jugador.
4. Juntando el xG y xGA a los minutos y calculando las cifras por cada 90 minutos en el campo.
5. Aquí creamos un Data Frame para el gráfico, con un filtro para incluir sólo a jugadores con 900 o más minutos disputados.
6. La función pivot_longer() aplana los datos para crear filas individuales para cada variable y valor relacionada a un jugador. Es más fácil visualizarlo:
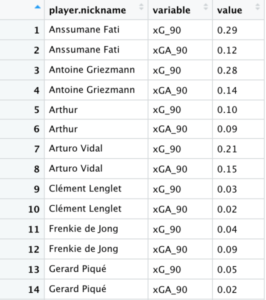
Tenemos los datos preparados para crear el gráfico.
ggplot(chart, aes(x =reorder(player.nickname, value), y = value, fill=fct_rev(variable))) + #1
geom_bar(stat="identity", colour="white")+
labs(title = "xG + xG Asistido", subtitle = "Barcelona, La Liga, 2019-20", x="", y="Por cada 90 minutos", caption ="Mínimo de 900 minutos jugados")+
theme(axis.text.y = element_text(size=14, color="#333333", family="Source Sans Pro"),
axis.title = element_text(size=14, color="#333333", family="Source Sans Pro"),
axis.text.x = element_text(size=14, color="#333333", family="Source Sans Pro"),
axis.ticks = element_blank(),
panel.background = element_rect(fill = "white", colour = "white"),
plot.background = element_rect(fill = "white", colour ="white"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
plot.title=element_text(size=24, color="#333333", family="Source Sans Pro" , face="bold"),
plot.subtitle=element_text(size=18, color="#333333", family="Source Sans Pro", face="bold"),
plot.caption=element_text(color="#333333", family="Source Sans Pro", size =10),
text=element_text(family="Source Sans Pro"),
legend.title=element_blank(),
legend.text = element_text(size=14, color="#333333", family="Source Sans Pro"),
legend.position = "bottom") + #2
scale_fill_manual(values=c("#3371AC", "#DC2228"), labels = c( "xGA","xG")) + #3
scale_y_continuous(expand = c(0, 0), limits= c(0,max(chart$value) + 0.5)) + #4
coord_flip()+ #5
guides(fill = guide_legend(reverse = TRUE)) #6
1. Usamos reorder() para poner los jugadores en orden de su suma de xG y xGA. Hemos puesto el ‘variable’ como la fill de la barra. Así podemos poner los dos datos juntos en la misma barra con un color distinto para cada uno de los dos.
2. La función labs() controla el título, el subtítulo y las etiquetas de los ejes. La función theme() controla la tipografía, el color del fondo y cosas así.
3. Aquí estamos eligiendo los colores para cada dato (xG = rojo; xGA = azul) y creando la etiqueta.
4. Poniendo un límite al eje y. En este caso hemos usado el valor máximo + 0.3.
5. Cambiando los ejes para tener un diagrama de barras horizontal en vez de vertical.
6. Tenemos que invertir la leyenda para que muestre los datos en el mismo orden que el diagrama. El resultado final será esta visualización:
Existen muchas variaciones que podéis hacer con un diagrama de barras así: presiones, dividido entre campo propio y campo contrario; incursiones al área, dividido entre pases y conducciones; pases, dividido entre los dos pies. Nuestra especificación de datos incluye los nombres de todos los variables que podéis utilizar.
Ahora es el turno de vosotros. Podéis compartir sus resultados con nosotros: @statsbombes en Twitter. Cabe mencionar que además del nuestro paquete de R, tenemos uno de Python, StatsBombPy. Podéis encontrar todos los detalles en nuestro Github.
Los radares son el símbolo de StatsBomb, una manera original y práctica de visualizar datos tanto de jugadores como equipos. A pesar de que hoy en día parecen omnipresentes en los círculos de análisis de datos en el fútbol, siguen siendo una de las marcas distintivas de StatsBomb, puesto que estos fueron creados y popularizados aquí.
Sin embargo, hasta ahora no habíamos escrito algo en Castellano para ayudaros a interpretar los radares que utilizamos tanto en nuestros análisis como en las redes sociales.
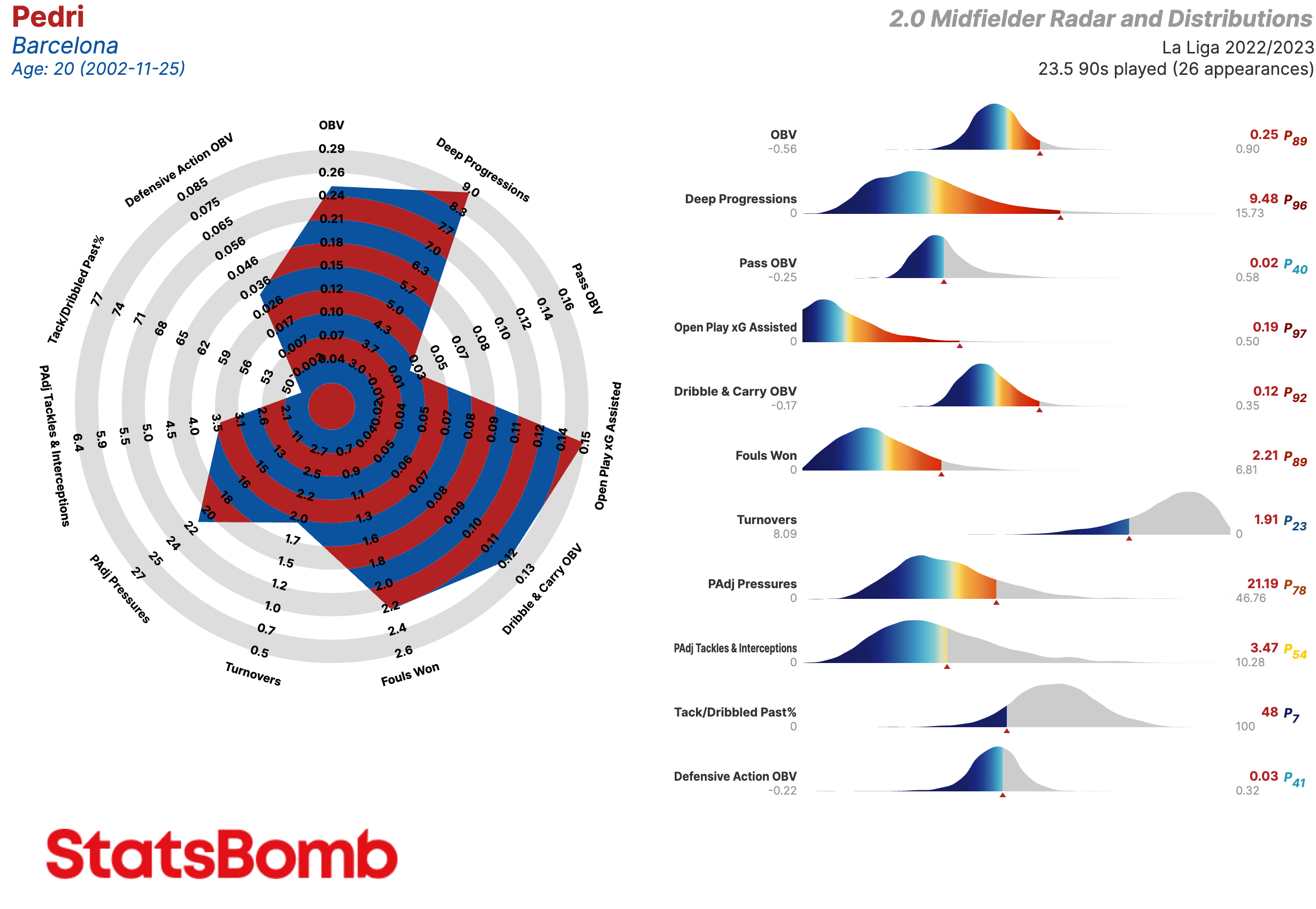
¿De qué estamos hablando? Aquí está un ejemplo de uno de nuestros radares.
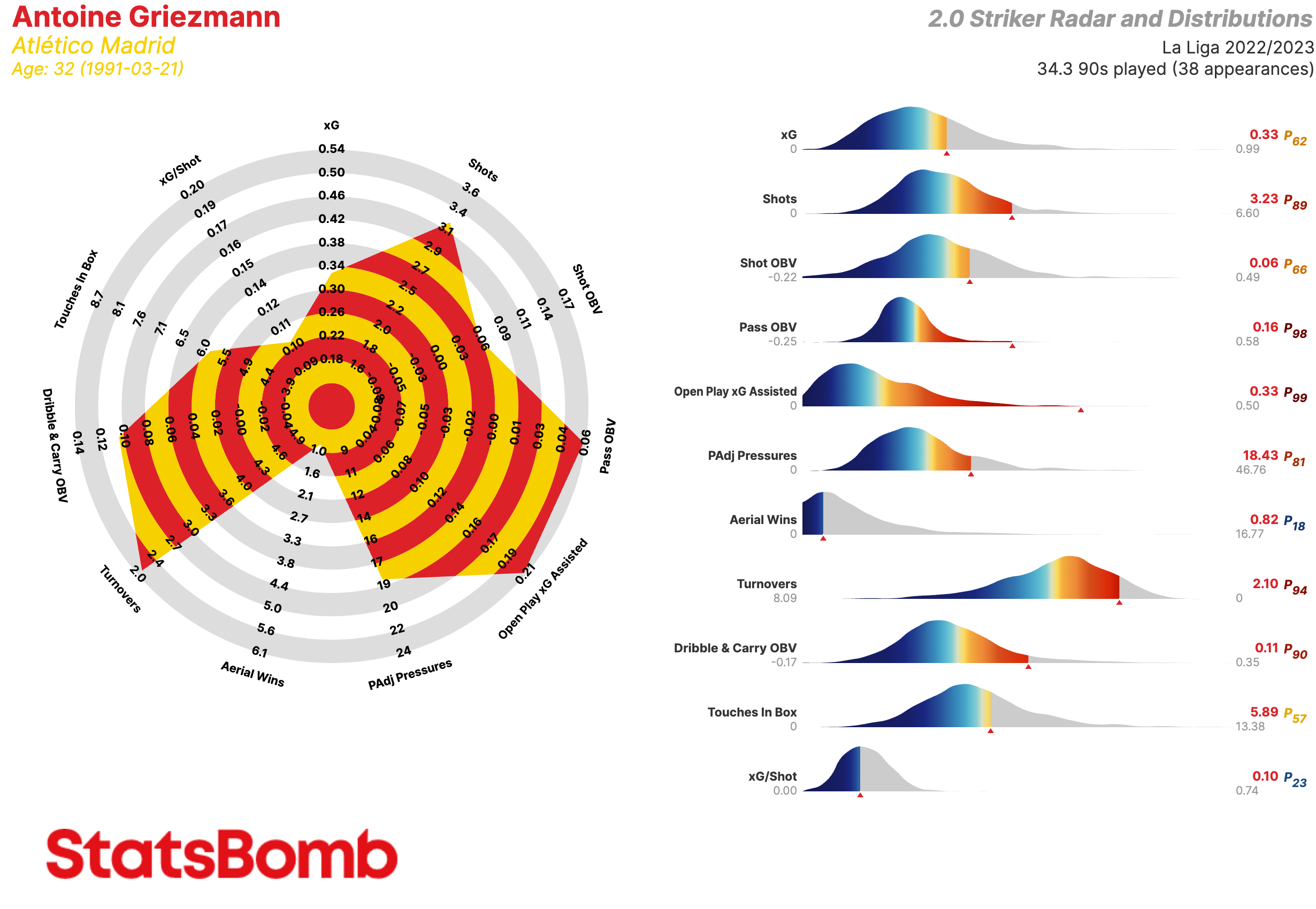
Vamos a hablar de las métricas en sí más tarde, pero existen algunas cosas que tenemos que explicar antes.
Primero, los límites interiores y exteriores de los radares representan respectivamente los percentiles 5 y 95 de la distribución posicional para cada métrica en las cinco grandes ligas de Europa durante varias temporadas.
Segundo, la gráfica de distribución que se encuentra a la derecha del radar muestra donde cae el jugador dentro de la distribución de su posición en cada métrica. La flecha indica la posición del jugador mientras la paleta de colores da una idea del percentil en el que se encuentra. El percentil y el valor de la métrica están mostrados a la derecha de la gráfica.
Las gráficas de distribución son una manera sencilla de visualizar que excepcional es un jugador como Lionel Messi.
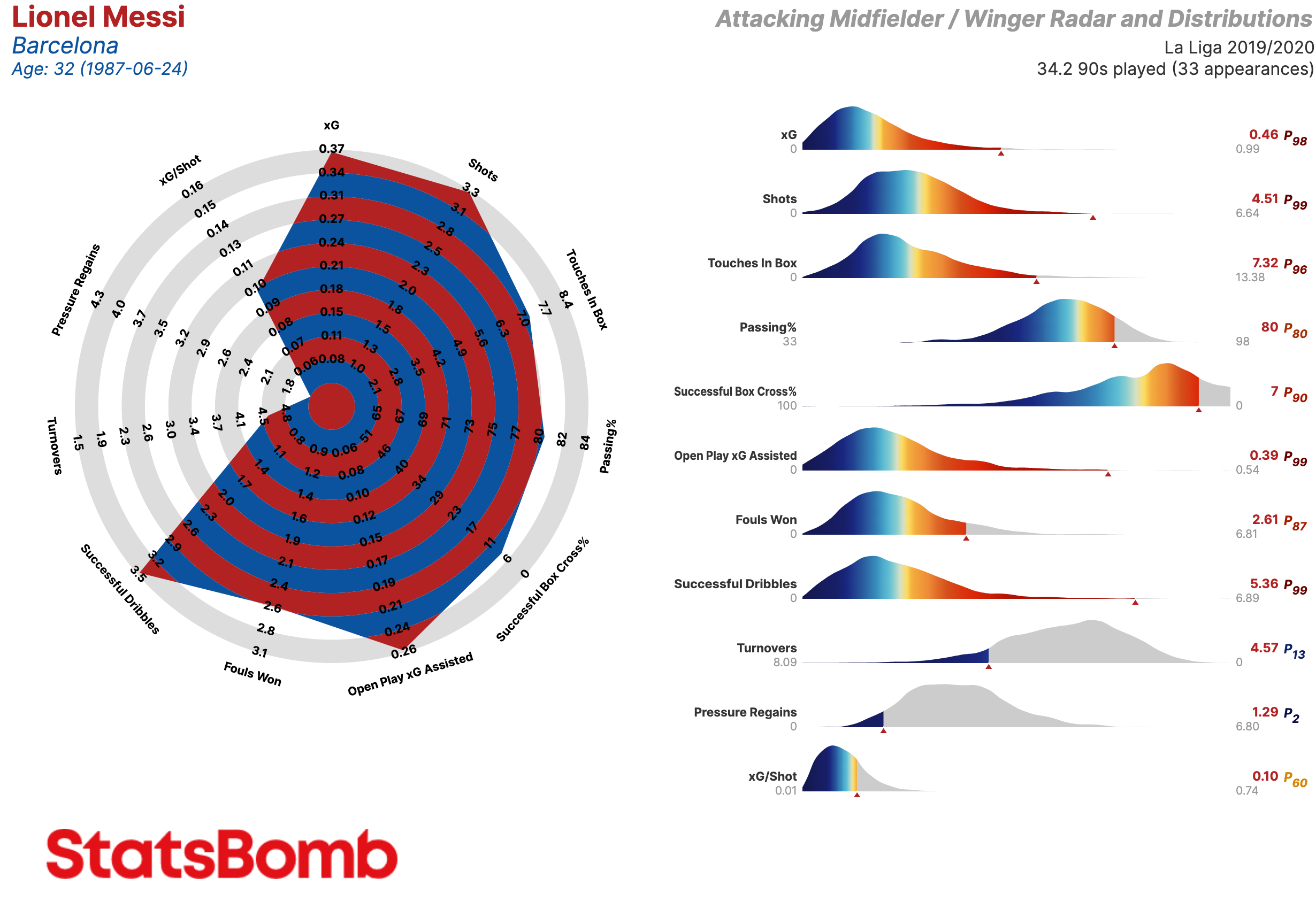
Existen más opciones. Dentro del radar, podemos visualizar los percentiles en vez de los valores de cada métrica. A veces, en lugar de la gráfica de distribución, publicamos los radares con una tabla que contiene los detalles de la producción estadística del jugador. Asimismo, nuestros clientes tienen la oportunidad de personalizar las métricas incluidas para crear sus propios radares.
Apuntes Generales
- Cuando hacemos referencia al xG, estamos hablando de los Goles Esperados, el marco general empleado en la mayoría de los análisis actuales. La explicación simplificada de esta métrica es que mide la probabilidad de que un tiro dado termine en gol. Sin embargo, va mucho más allá de eso, como explicamos en este artículo.
- Todos los datos son por cada 90 minutos. Hemos explicado antes las razones por las cuales ajustamos los datos así, pero en breve, es la forma más sencilla y práctica de hacer comparaciones entre jugadores que han disputado diferentes cantidades de minutos a lo largo de una temporada.
- Asimismo, ajustamos algunas de las métricas defensivas en función de la posesión. Este ajuste es una solución práctica para estandarizar los valores de modo que se pueden comparar entre diferentes jugadores corrigiendo aspectos relacionados con el estilo de juego de sus respectivos equipos. Damos una explicación más profunda aquí.
- Algunos de los radares incluyen la métrica On-Ball Value (OBV). En resumen, OBV es un modelo que mide el cambio en la probabilidad de un equipo de marcar/conceder como resultado de una acción dada. Esto permite identificar las acciones más relevantes en una posesión y poder otorgar más mérito a las acciones con mayor impacto en la posesión.
- Cabe mencionar que no todas las métricas miden la calidad del jugador y/o su rendimiento. Muchas de ellas son marcas estilísticas, particularmente en el caso de los defensores.
En octubre de 2023, actualizamos nuestras plantillas para cada posición para incluir algunas de nuestras nuevas métricas como OBV. Aquí están las versiones actuales:
Centrales
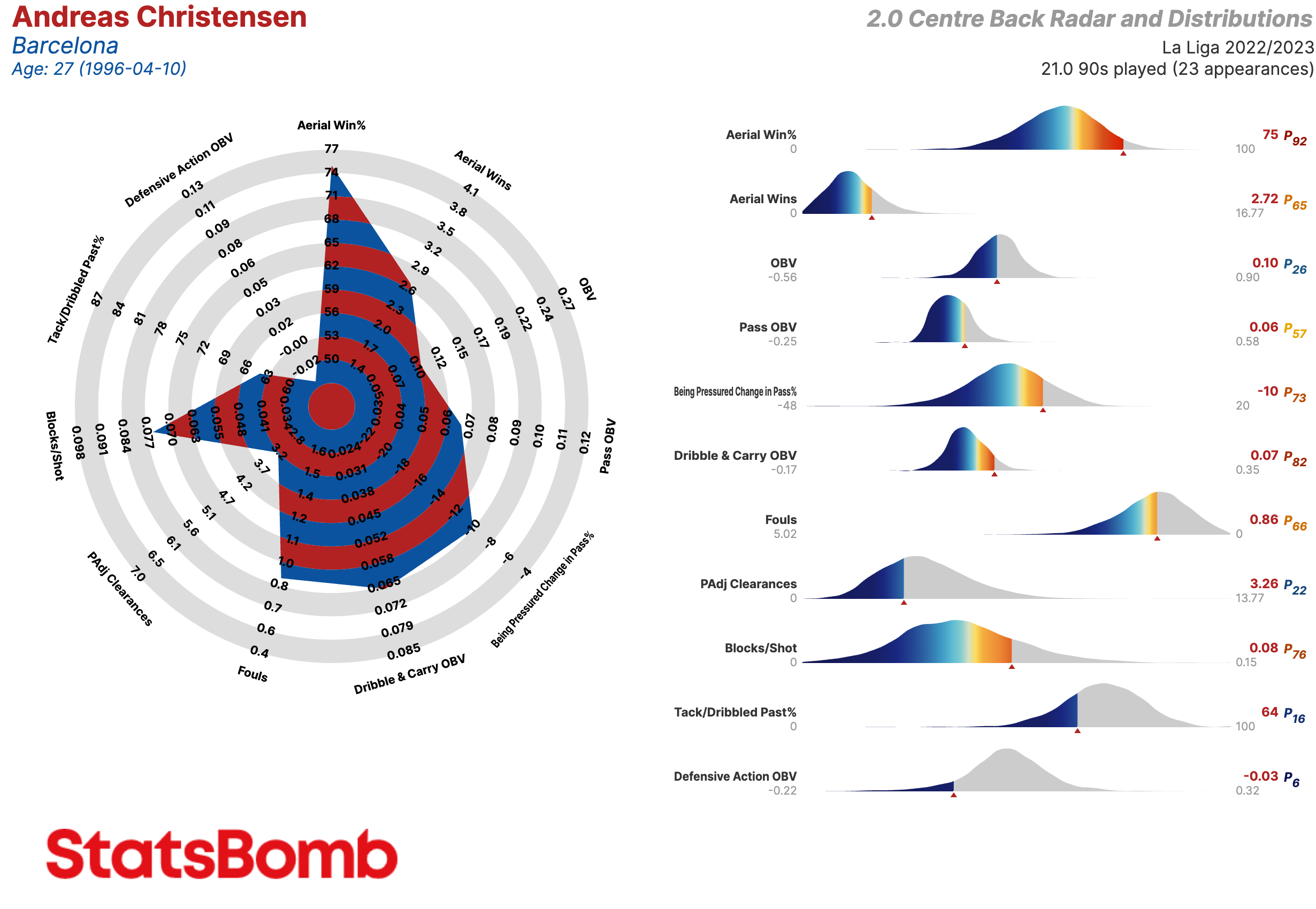
- Aerial Win%: Porcentaje de duelos aéreos ganados
- Aerial Wins: Duelos aéreos ganados
- OBV: Valor agregado en las acciones relacionadas con el balón
- Pass OBV: Valor agregado mediante pases
- Being Pressured Change in Pass %: El cambio en el porcentaje de acierto en el pase del jugador en los pases realizados bajo presión rival
- Dribble & Carry OBV: Valor agregado mediante regates y conducciones
- Fouls: Faltas
- PAdj Clearances: Despejes ajustadas en función de la posesión
- Blocks/Shot: Proporción de los tiros enfrentados que fueron bloqueados
- Tack/Dribbled Past%: La proporción de entradas exitosas a ocasiones en que el oponente le/la regateó
- PAdj Tackles: Entradas exitosas ajustadas en función de la posesión
- Defensive Action OBV: Valor agregado mediante acciones defensivas
Laterales
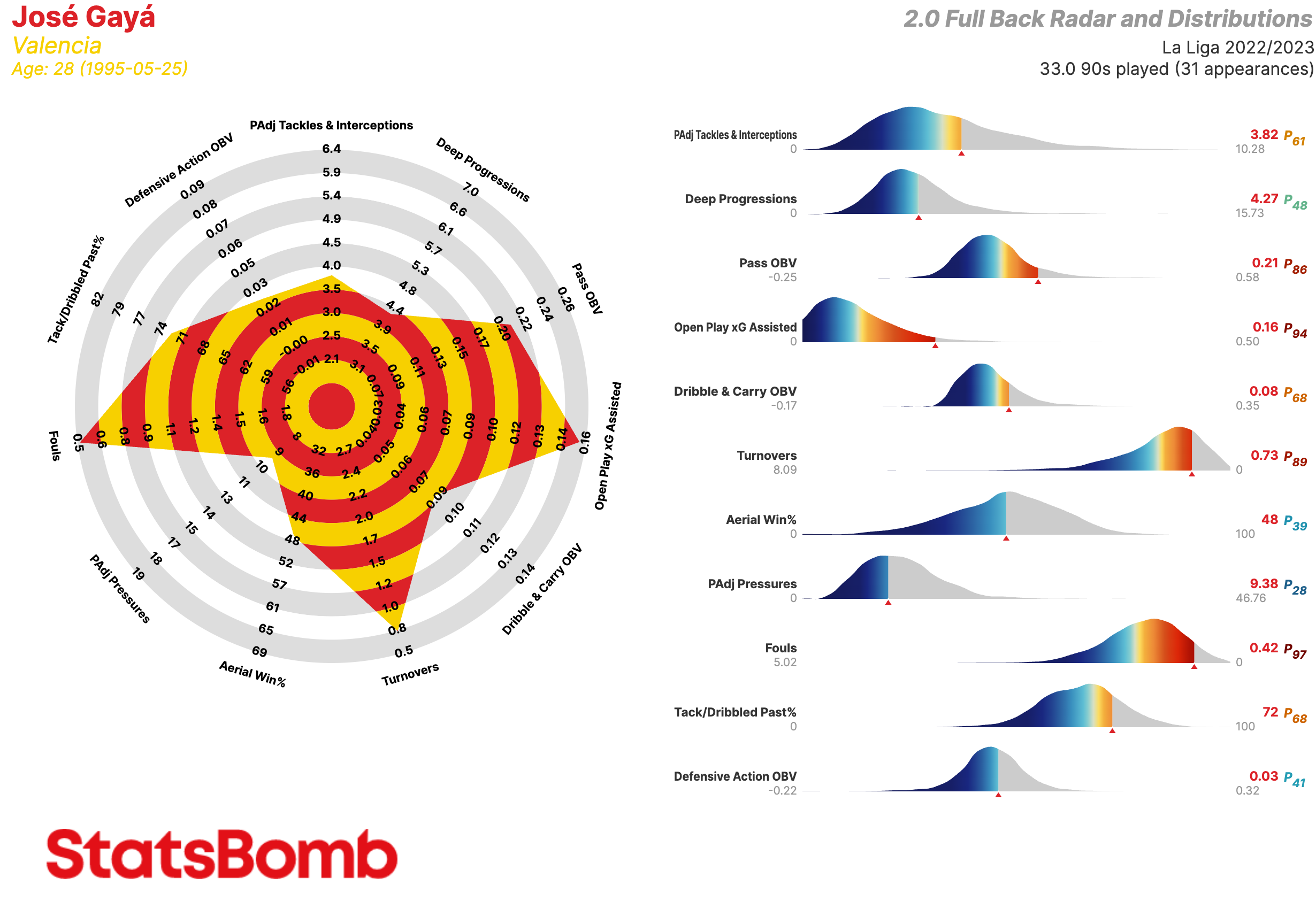
- PAdj Tackles & Interceptions: Entradas y interceptaciones ajustadas en función de la posesión
- Deep Progressions: Incursiones en el último tercio a través de pases, regates o conducciones
- Pass OBV: Valor agregado mediante pases
- Open Play xG Assisted: Goles esperados asistidos en juego abierto (es decir, sin contar los que provienen de las acciones a balón parado)
- Dribble & Carry OBV: Valor agregado mediante regates y conducciones
- Turnovers: Perdidas de posesión a través de fallos en el control del balón o regates fallidos
- Aerial Win%: Porcentaje de duelos aéreos ganados
- PAdj Pressures: Presiones ajustadas en función de la posesión
- Fouls: Faltas
- Tack/Dribbled Past%: La proporción de entradas exitosas a ocasiones en que el oponente le/la regateó
- Defensive Action OBV: Valor agregado mediante acciones defensivas
Centrocampistas / Mediocampistas
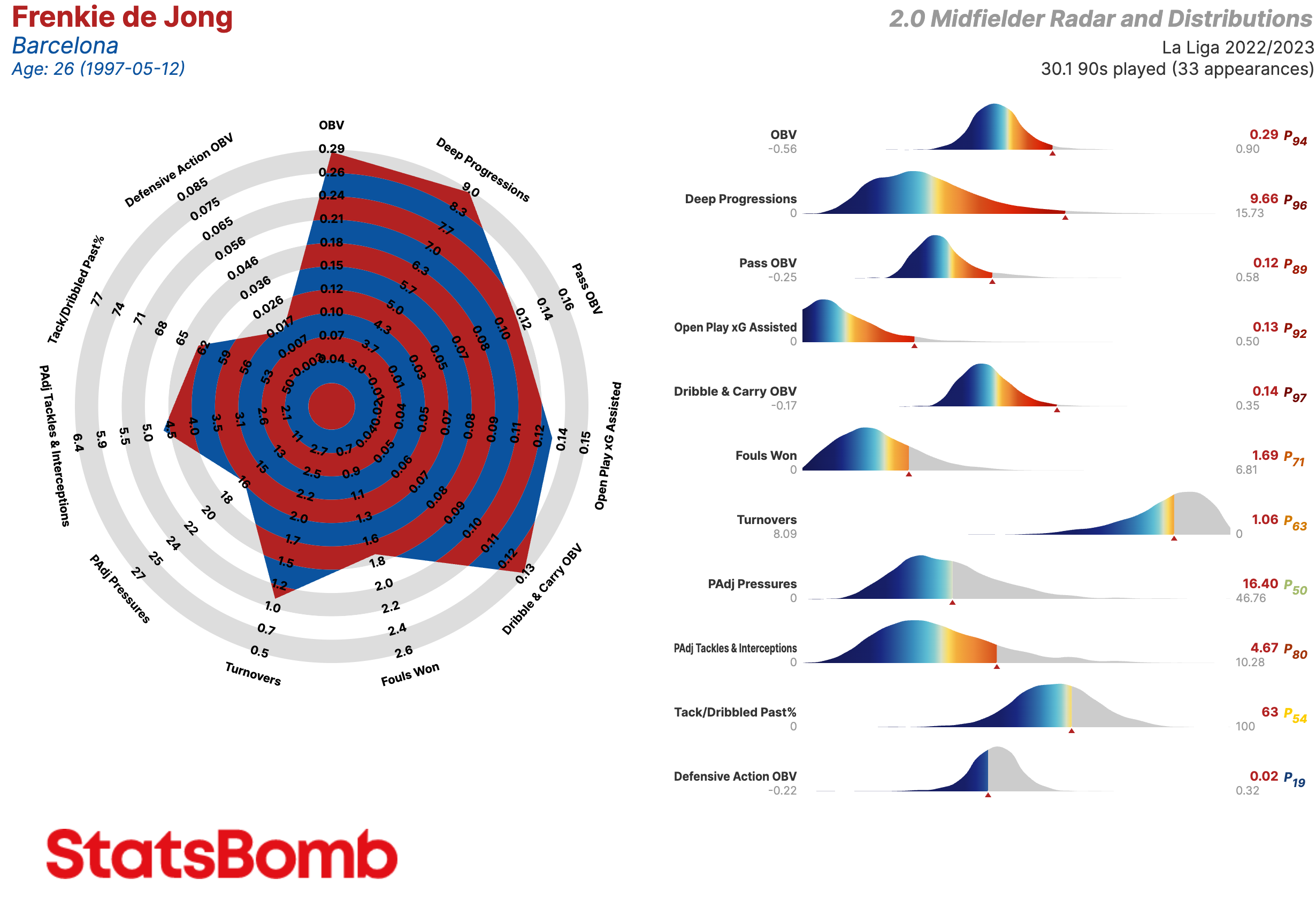
- OBV: Valor agregado en las acciones relacionadas con el balón
- Deep Progressions: Incursiones en el último tercio a través de pases, regates o conducciones
- Pass OBV: Valor agregado mediante pases
- Open Play xG Assisted: Goles esperados asistidos en juego abierto (es decir, sin contar los que provienen de las acciones a balón parado)
- Dribble & Carry OBV: Valor agregado mediante regates y conducciones
- Fouls Won: Faltas recibidas
- Turnovers: Perdidas de posesión a través de fallos en el control del balón o regates fallidos
- PAdj Pressures: Presiones ajustadas en función de la posesión
- PAdj Tackles & Interceptions: Entradas y interceptaciones ajustadas en función de la posesión
- Tack/Dribbled Past%: La proporción de entradas exitosas a ocasiones en que el oponente le/la regateó
- Defensive Action OBV: Valor agregado mediante acciones defensivas
Extremos / Mediapuntas
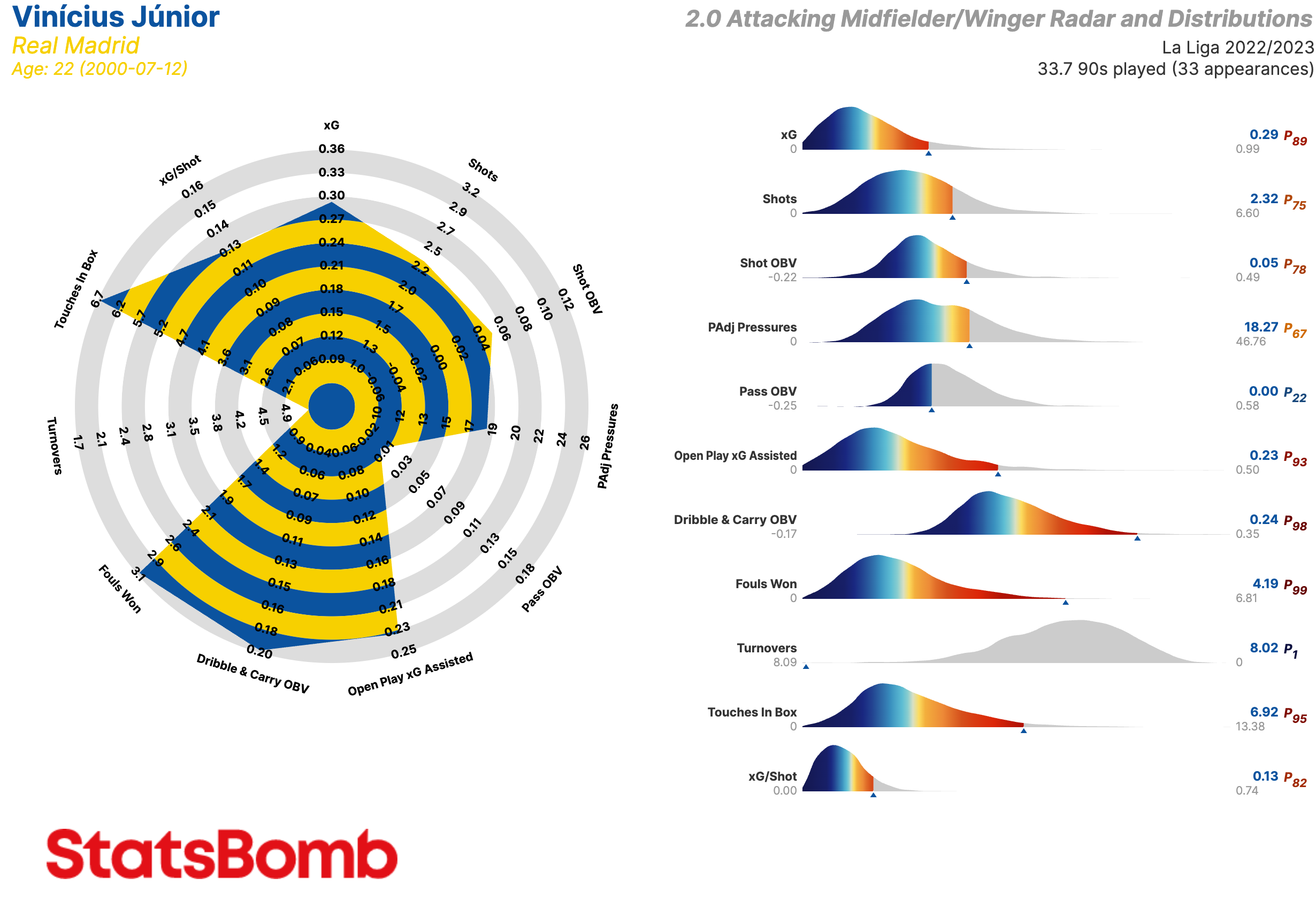
- xG: Goles esperados
- Shots: Tiros
- Shot OBV: Valor agregado en la ejecución de los tiros
- PAdj Pressures: Presiones ajustadas en función de la posesión
- Pass OBV: Valor agregado mediante pases
- Open Play xG Assisted: Goles esperados asistidos en juego normal (es decir, sin contar los que provienen de las acciones a balón parado)
- Dribble & Carry OBV: Valor agregado mediante regates y conducciones
- Fouls Won: Faltas recibidas
- Turnovers: Perdidas de posesión a través de fallos en el control del balón o regates fallidos
- Touches in Box: Toques del balón dentro del área de penalti
- xG/Shot: Goles esperados por tiro. Es decir, la calidad media de sus tiros
Delanteros Centros
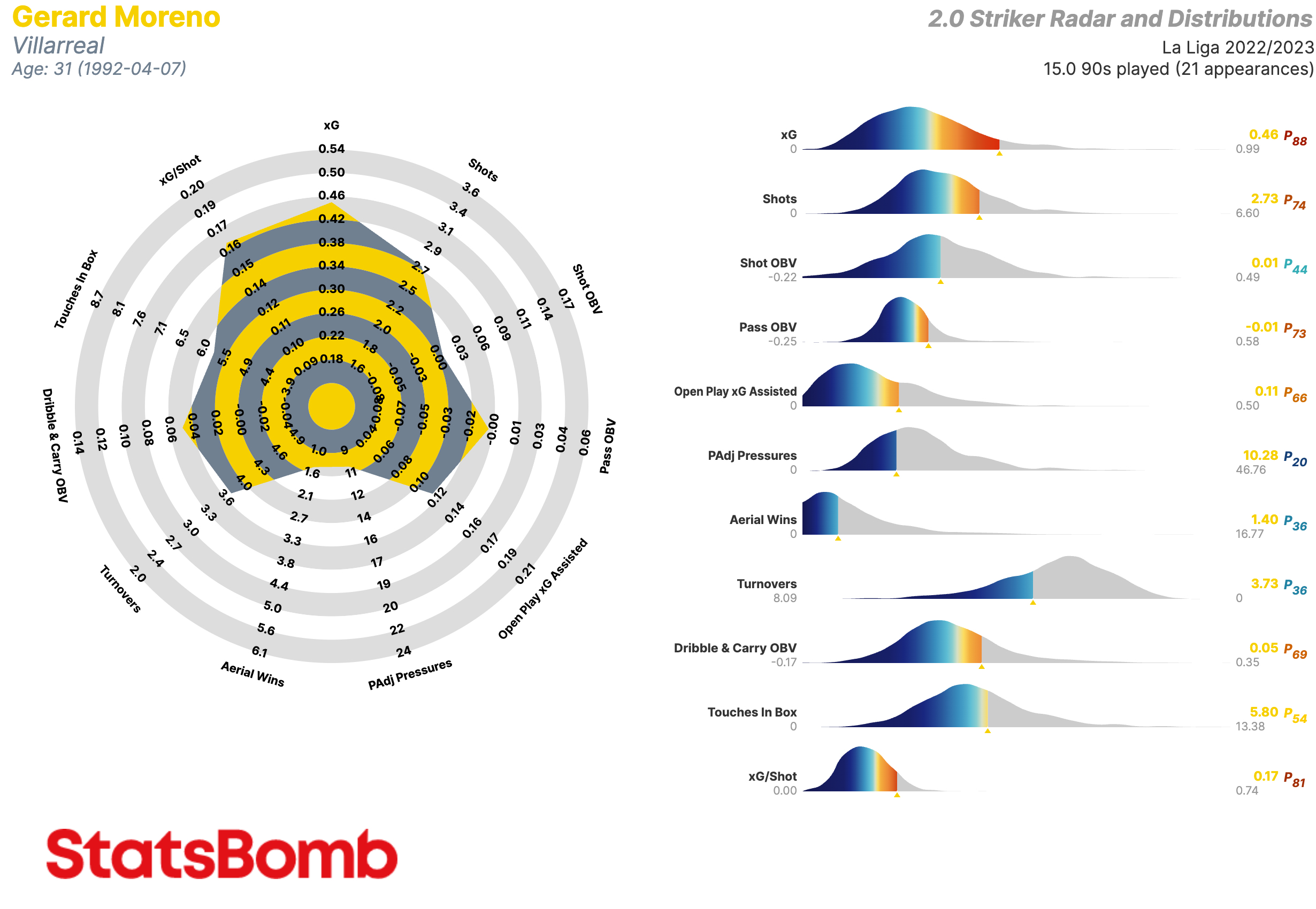
- xG: Goles esperados
- Shots: Tiros
- Shot OBV: Valor agregado en la ejecución de los tiros
- Pass OBV: Valor agregado mediante pases
- Open Play xG Assisted: Goles esperados asistidos en juego normal (es decir, sin contar los que provienen de las acciones a balón parado)
- PAdj Pressures: Presiones ajustadas en función de la posesión
- Aerial Wins: Duelos aéreos ganados
- Turnovers: Perdidas de posesión a través de fallos en el control del balón o regates fallidos
- Dribble & Carry OBV: Valor agregado mediante regates y conducciones
- Touches in Box: Toques del balón dentro del área de penalti
- xG/Shot: Goles esperados por tiro. Es decir, la calidad media de sus tiros
¿Quieres saber más sobre las métricas que se están generalizando en el fútbol? Nuestro curso online Introducción al Análisis de Datos en Fútbol Profesional ya está disponible. Los goles esperados (xG), táctica ofensiva y defensiva, acciones a balón parado, análisis de equipos y más... Apúntate >> https://cursos.statsbomb.com/
Hace tres semanas publicamos nuestra introducción al uso de StatsBomb Data con R que abarcó los fundamentos de cómo organizar y utilizar nuestros datos gratuitos. Sin embargo, creemos que puede ser útil aportar otros ejemplos de cómo utilizar los datos. Existe una comunidad trabajando con nuestros datos y aportando el código para hacer cosas como mapas de pases, mapas de tiros o de acciones defensivas.
Para demostrar que no es tan difícil utilizar y modificar este código, los he comprobado por mí mismo. Soy novato total en R o cualquier otro lenguaje de programación, entonces si yo puedo hacerlo, estoy seguro de que vosotros no tendréis ningún problema a la hora de seguir estos ejemplos.
Mapa de Pases
En su blog BiscuitChaserFC, Mark Wilkins tiene un ejemplo, en inglés, de cómo crear un mapa de pases tanto de un equipo como de un jugador.
Puedes seguir el proceso paso a paso en el blog, pero este es el resultado final:

Y aquí el código:
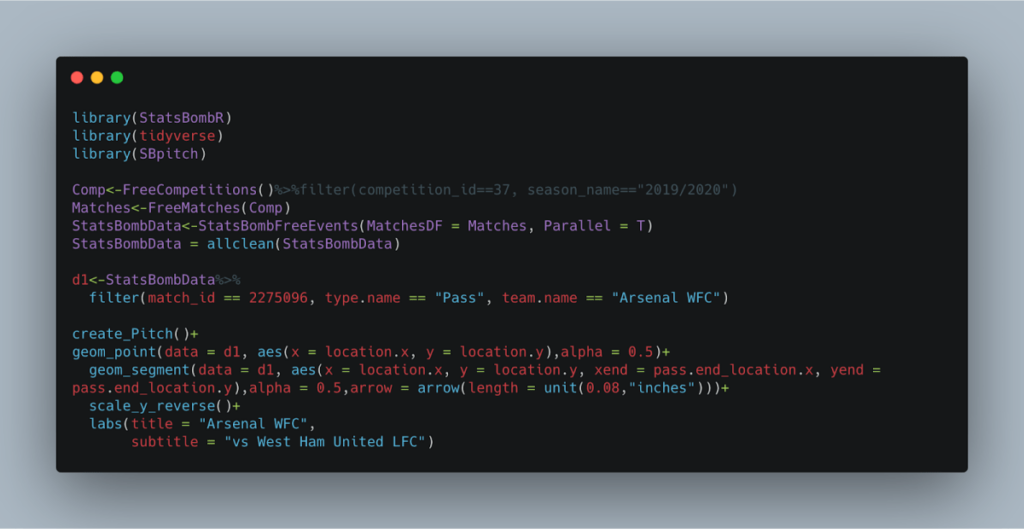
Este código representa una buena base para crear mapas de pases de otros equipos y jugadores. Sólo tenemos que cambiar los detalles de la competición y el partido para recrearlo con otros equipos. Puedes ver aquí una lista de todas las competiciones disponibles y el 'competition_id' de cada una.
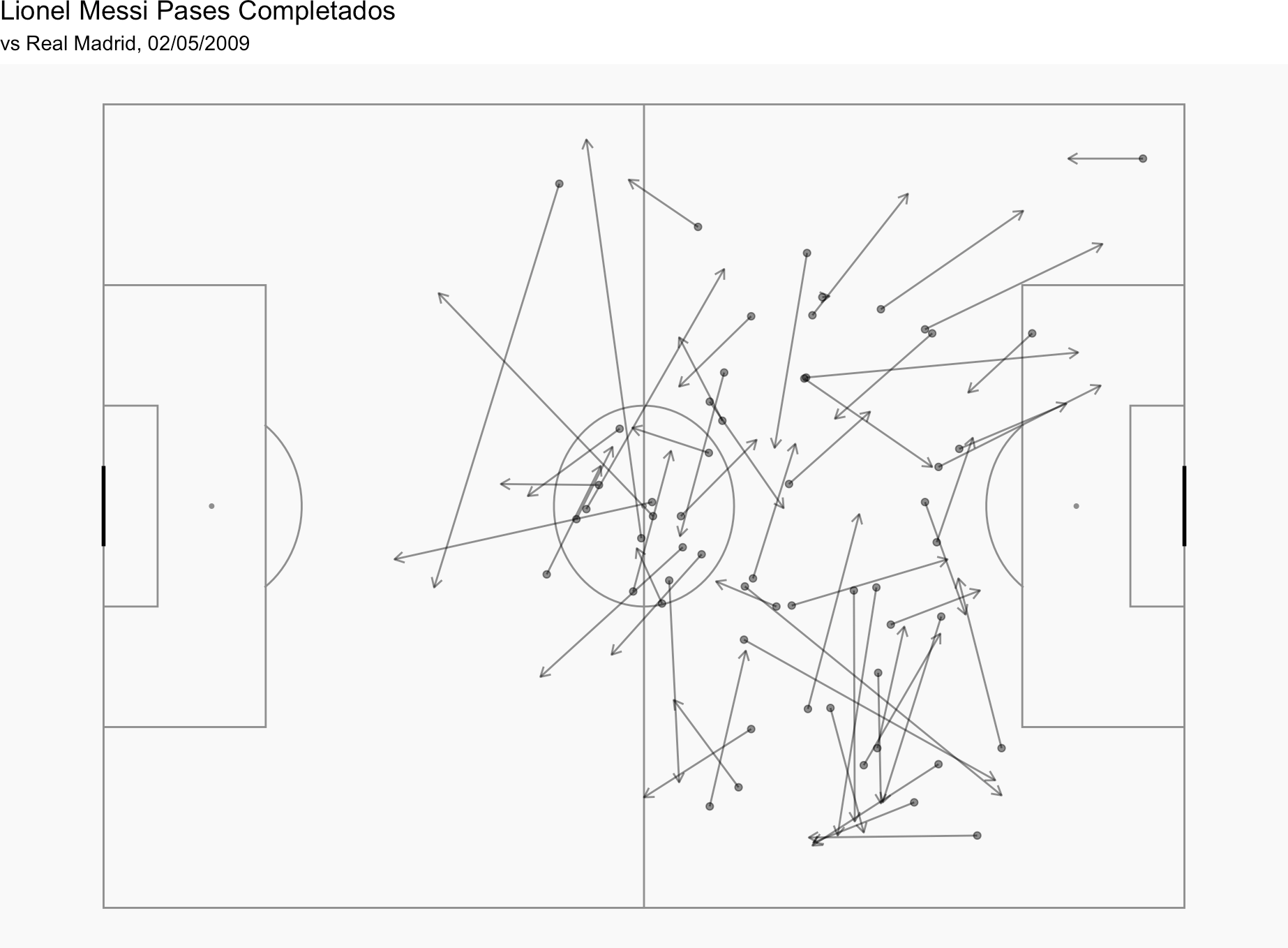
Por ejemplo, podemos utilizar este código para tener los datos de todos los partidos de la temporada 2008/09 de La Liga en que jugó Lionel Messi.
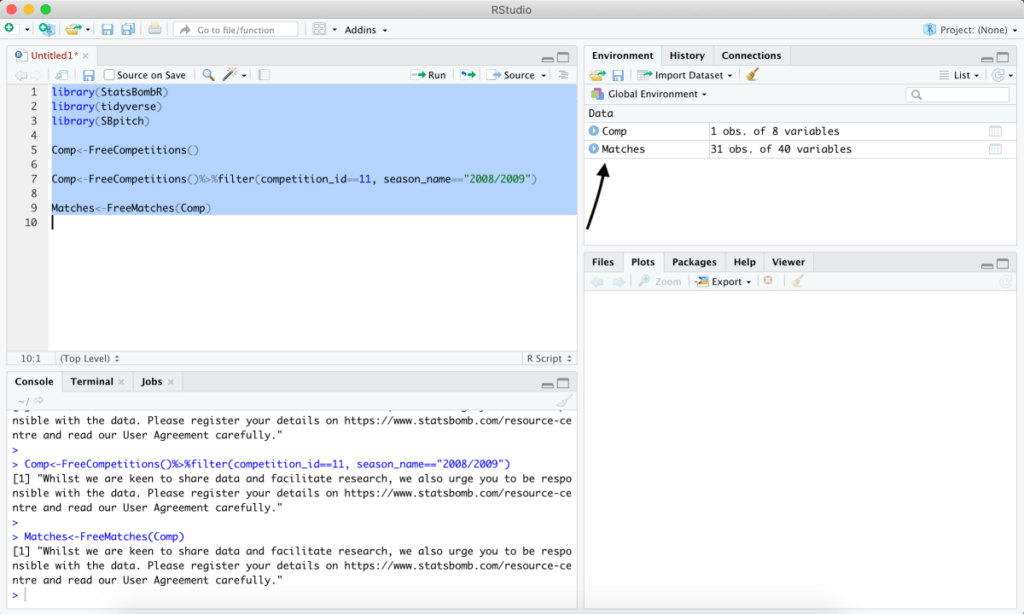
Comp<-FreeCompetitions()%>%filter(competition_id==11, season_name=="2008/09")
Matches<-FreeMatches(Comp)
Dentro de la pestaña 'Environment', en la categoría de 'Data', puedes hacer click en 'Matches' para ver una tabla de todos los partidos disponibles y el 'match_id' de cada uno.
Vamos a seleccionar el partido entre el Barcelona y el Real Madrid del 2 de mayo de 2009, que tiene un 'match_id' de 69249.
Si seguimos el resto de los pasos del código original, creamos esto:

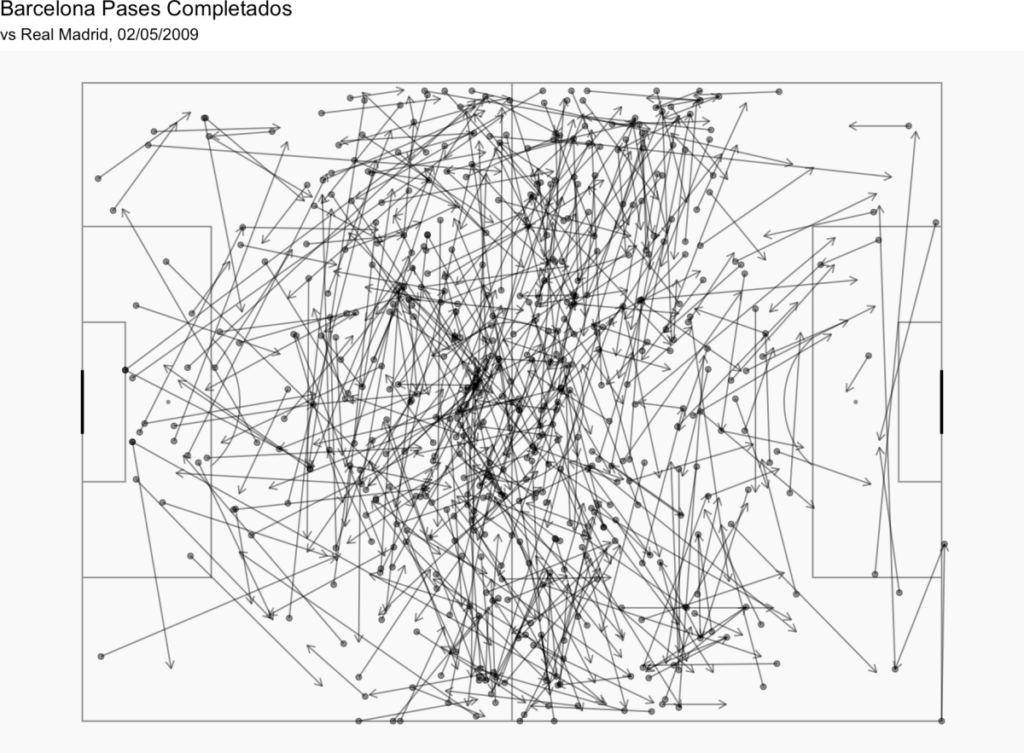
Podemos hacer un par de cosas más. Si añadimos is.na(pass.outcome.name) a nuestro filtro, tendremos sólo los pases completados:
d1<-StatsBombData%>%
filter(match_id == 69249, type.name == "Pass" & is.na(pass.outcome.name), team.name == "Barcelona")
Con este resultado:
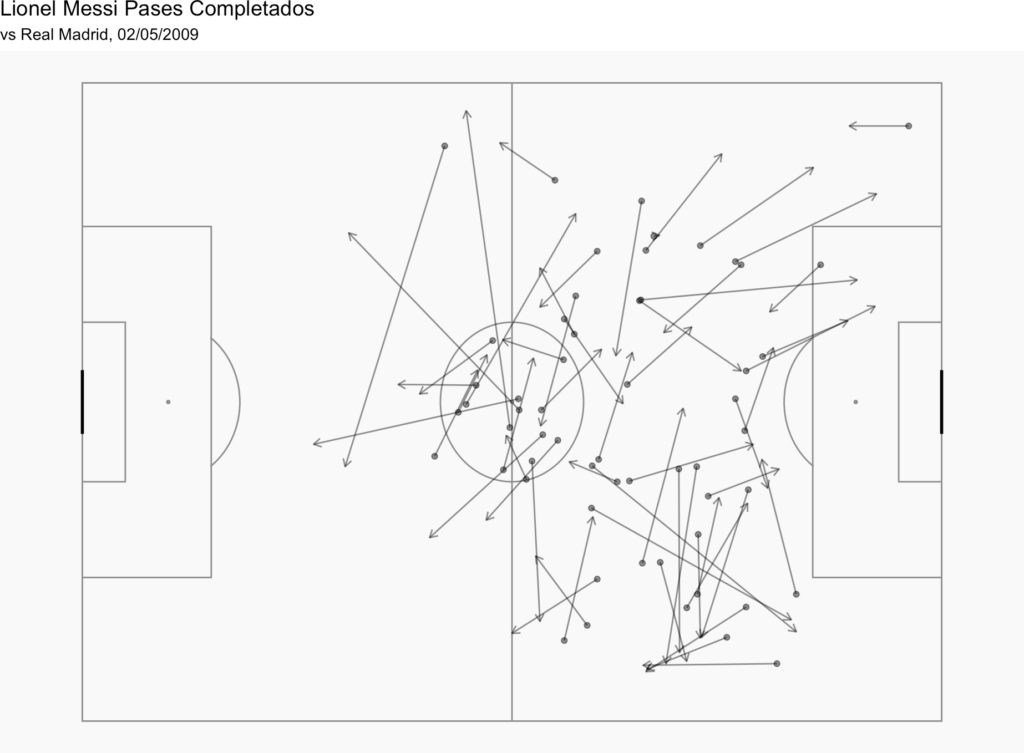
Si queremos el mapa de pases de un jugador en concreto, por ejemplo de Lionel Messi, podemos hacer esto:
d1<-StatsBombData%>% filter(match_id == 69249, type.name == "Pass" & is.na(pass.outcome.name), team.name == "Barcelona", player.name == "Lionel Andrés Messi Cuccittini")
Con este resultado:
Y si queremos añadir otro elemento, podemos hacer esto para crear un mapa de los pases de Messi a Xavi.
d1<-StatsBombData%>% filter(match_id == 69249, type.name == "Pass" & is.na(pass.outcome.name), team.name == "Barcelona", player.name == "Lionel Andrés Messi Cuccittini", pass.recipient.name == "Xavier Hernández Creus")
Con este resultado:
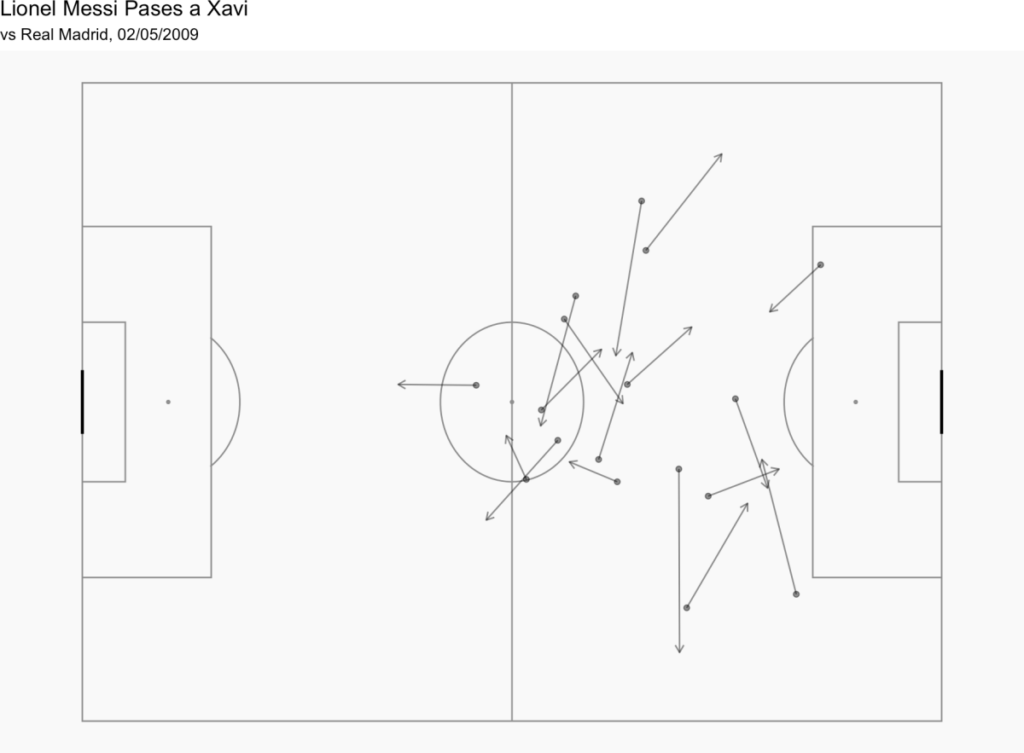
Con la ayuda de nuestra especificación de datos para ver los nombres de los variables, puedes hacer más cambios así para crear mapas de pases más especializados.
Mapa de Tiros
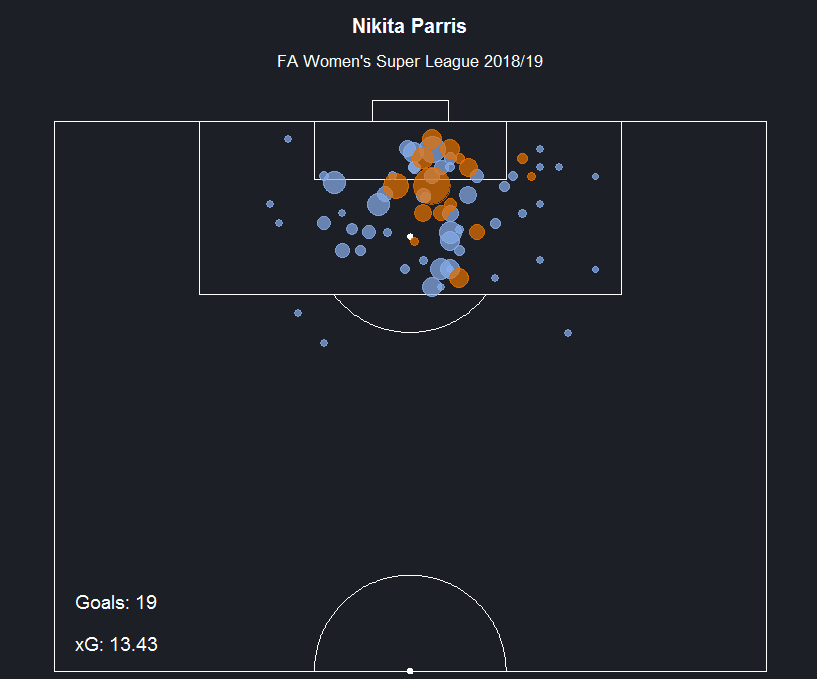
En su blog de medium, Ismael Gómez Schmidt tiene un ejemplo de cómo crear un mapa de tiros de un jugador con la ayuda de un paquete de R llamado 'soccermatics'.
Él utilizó los datos de la FA Women’s Super League para crear un mapa de tiros de Nikita Parris, la delantera del Manchester City.
Ismael recomienda el uso de la función source para cargar tres elementos del paquete 'soccermatics' ya que a veces se encuentran problemas en instalar el paquete en sí. No funcionó para mí la primera vez, pero después de instalar, por separado, los paquetes 'ggrepel' y 'xts', he podido instalar 'soccermatics'.
Si puedes instalarlo, ignoras la parte del código que se refiere a la función source y simplemente cargas el paquete 'soccermatics' al mismo tiempo que cargas los otros paquetes, usando:
library (soccermatics)
Además, existe un pequeño error en el código. Cuando se utiliza la función soccertransform para escalar las coordenadas para que se visualicen correctamente, debería ser escrito así:
data <- StatsBombData %>% soccerTransform(method = "statsbomb")
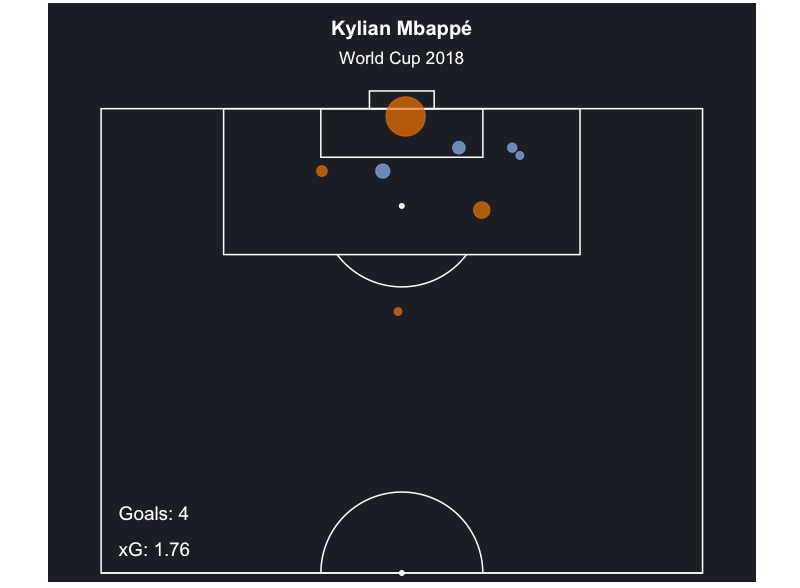
Cuando estés cómodo con el funcionamiento del código, puedes hacer pequeñas alteraciones para conseguir los mapas de tiros de otros jugadores en otras competiciones. Por ejemplo, he utilizado su código para hacer lo mismo para Kylian Mbappe en el Mundial de 2018.
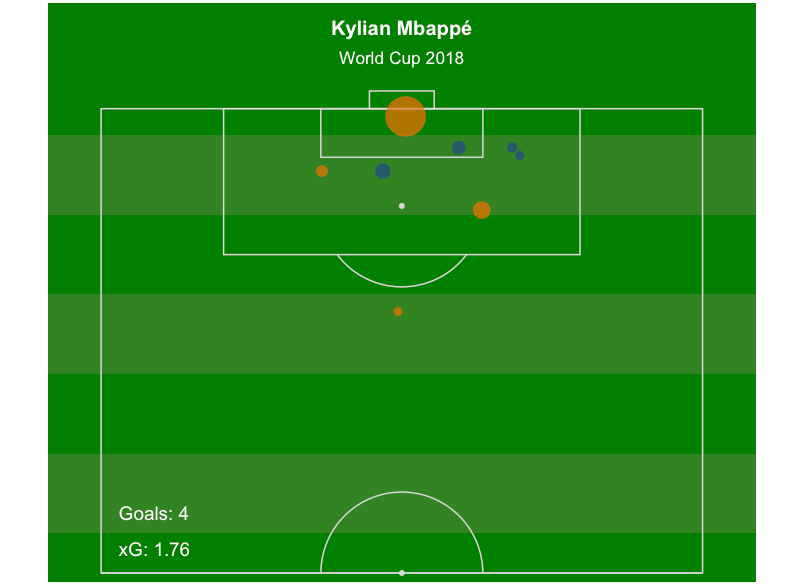
La función soccerShotmap incluye cuatro plantillas diferentes que cambian el color del fondo. Por ejemplo, en vez de “dark,” se puede utilizar “grass”:
Mapa de acciones defensivas
Más allá de los mapas de tiros, hay varias funciones interesantes dentro del paquete 'soccermatics'. Su página de Github explica cómo utilizarlo para crear un abanico de visualizaciones diferentes.
StatsBomb es el único proveedor de datos que recoge las acciones de presión. Entonces, tiene sentido aportar un ejemplo que utiliza estos datos. Vamos a hacer un mapa de algunas de las acciones defensivas de un equipo y luego, sólo las acciones de presión del mismo.
El ejemplo en la página de ‘soccermatics’ (dentro de la sección 'Custom plots') es el partido entre Francia y Argentina en el Mundial de 2018:
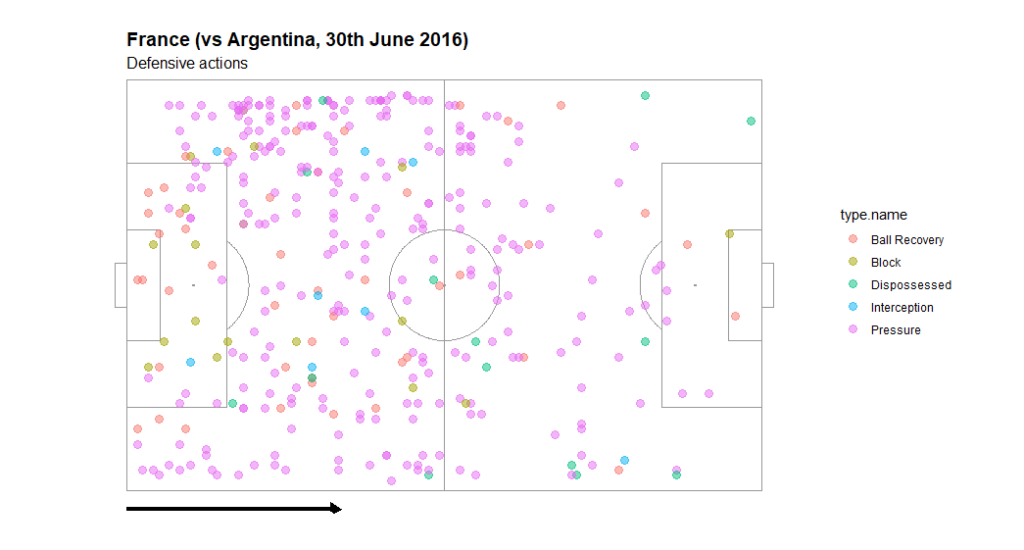
El proceso es muy parecido a lo de los mapas de tiros. Cargas los datos de la competición y sus partidos, creas un data frame para el partido específico:
statsbomb<-data%>%filter(match_id == 7580)
Y luego creas el gráfico con el código de la pagina de ‘Soccermatics’:
d2 <- statsbomb %>% filter(type.name %in% c("Pressure", "Interception", "Block", "Dispossessed", "Ball Recovery") & team.name == "France")
soccerPitch(arrow = "r", title = "France (vs Argentina, 30th June 2018)”, subtitle = "Defensive actions") + geom_point(data = d2, aes(x = location.x, y = location.y, col = type.name), size = 3, alpha = 0.5)
Vamos a hacer lo mismo gráfico para otro partido de ese mundial, en este caso el octavo de final entre España y Rusia. Este partido tiene el ‘match_id’ de 7582. Aquí está el resultado:
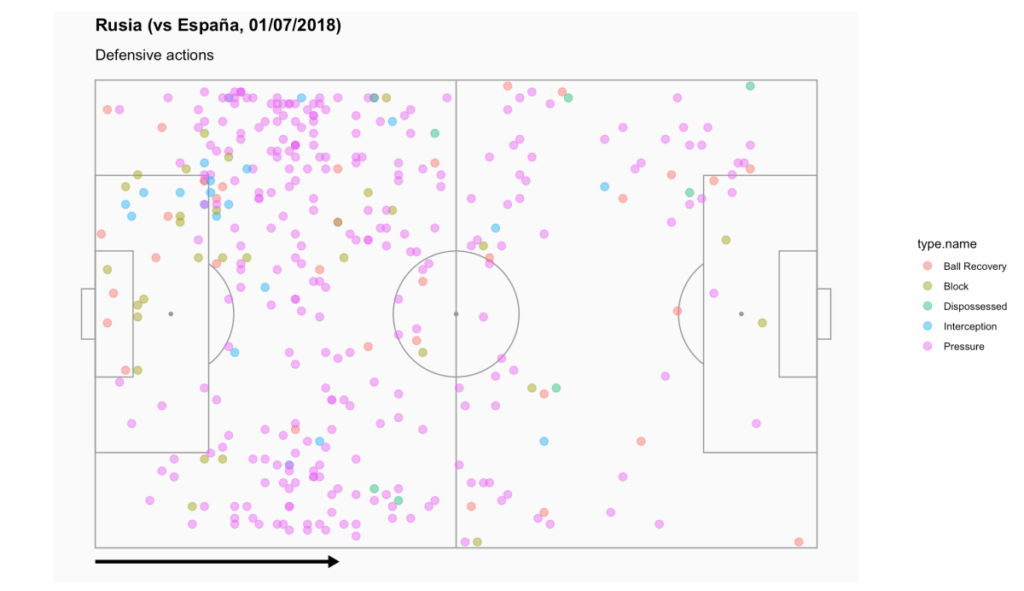
Ahora, vamos a cambiarlo un poco para incluir sólo las acciones de presión:
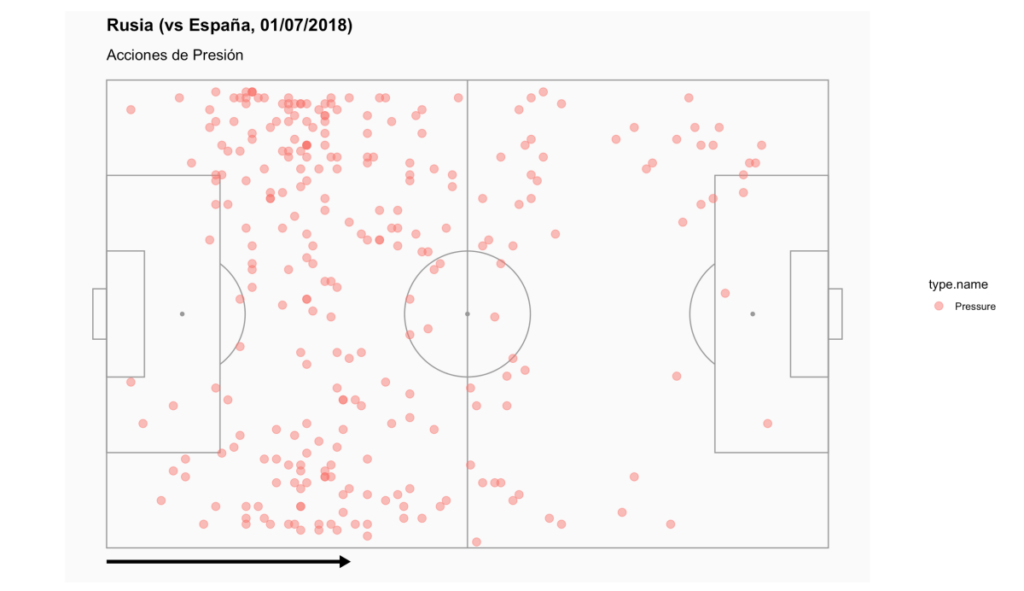
d2 <- statsbomb %>% filter(type.name %in% c("Pressure") & team.name == “Russia”)
soccerPitch(arrow = "r", title = “Rusia (vs España, 01/07/2018)”, subtitle = “Acciones de Presión”) + geom_point(data = d2, aes(x = location.x, y = location.y, col = type.name), size = 3, alpha = 0.5)
Con este resultado:
Conclusión
Ojalá que sean útiles estes ejemplos. Son básicos, pero aportan una base para alteraciones y exploraciones adicionales. Puedo decir que he aprendido mucho de seguir y modificar el código de cada uno. Ahora es tu turno. Puedes compartir tus resultados con nosotros: @statsbombes en Twitter.