Hace un par de meses, añadimos los datos del Barcelona de la temporada 2019-20 a nuestro repositorio de la carrera completa de Lionel Messi y la gente ya ha empezado a hacer cosas interesantes con ellos. Por ejemplo, Eoin O’Brien ha creado una página interactiva en la que puedes ver los redes de pases del Barça en cada partido de la temporada.
Ahora, vamos a enseñar algunas cosas que podéis hacer con estos datos en R, un programa y lenguaje de programación que solemos utilizar en nuestro trabajo de análisis. Ya hemos escrito una introducción al uso de StatsBomb Data en R y recomendamos que la leéis antes de intentar hacer las cosas incluidas en este artículo, que tiene como base un artículo en inglés por nuestro analista Euan Dewar.
Podéis hacer estas cosas con tanto los datos de Messi como los de las otras competiciones que ofrecemos de manera gratuita, incluyendo los últimos mundiales tanto masculino como femenino, la temporada de liga del mítico Arsenal de la 2003-04 y las ligas femeninas de Inglaterra y los Estados Unidos. Podéis encontrar una lista completa de las competiciones aquí.
Importar los datos
Primero, tenemos que importar los datos del Barcelona de la 2019-20:
library(tidyverse)
library(StatsBombR)
Comp <- FreeCompetitions() %>%
filter(competition_id==11 & season_name=="2019/2020")
Matches <- FreeMatches(Comp)
StatsBombData <- StatsBombFreeEvents(MatchesDF = Matches, Parallel = T)
StatsBombData = allclean(StatsBombData)
events = StatsBombData
Para crear visualizaciones es útil tener los nombres cortos de los jugadores en vez de sus nombres completos con segundo apellido, etc... Este código crea otra columna con este detalle ('player.nickname'):
lineups <- StatsBombFreeLineups(MatchesDF = Matches, Parallel = T)
lineups <- cleanlineups(lineups)
lineups <- lineups %>% mutate(player_nickname = ifelse(is.na(player_nickname), player_name, player_nickname))
lineups <- lineups %>% select(player.id = player_id, player.nickname = player_nickname) %>%
group_by(player.id) %>% slice(1) %>% ungroup()
events <- events %>% left_join(lineups)
Mapas de tiros
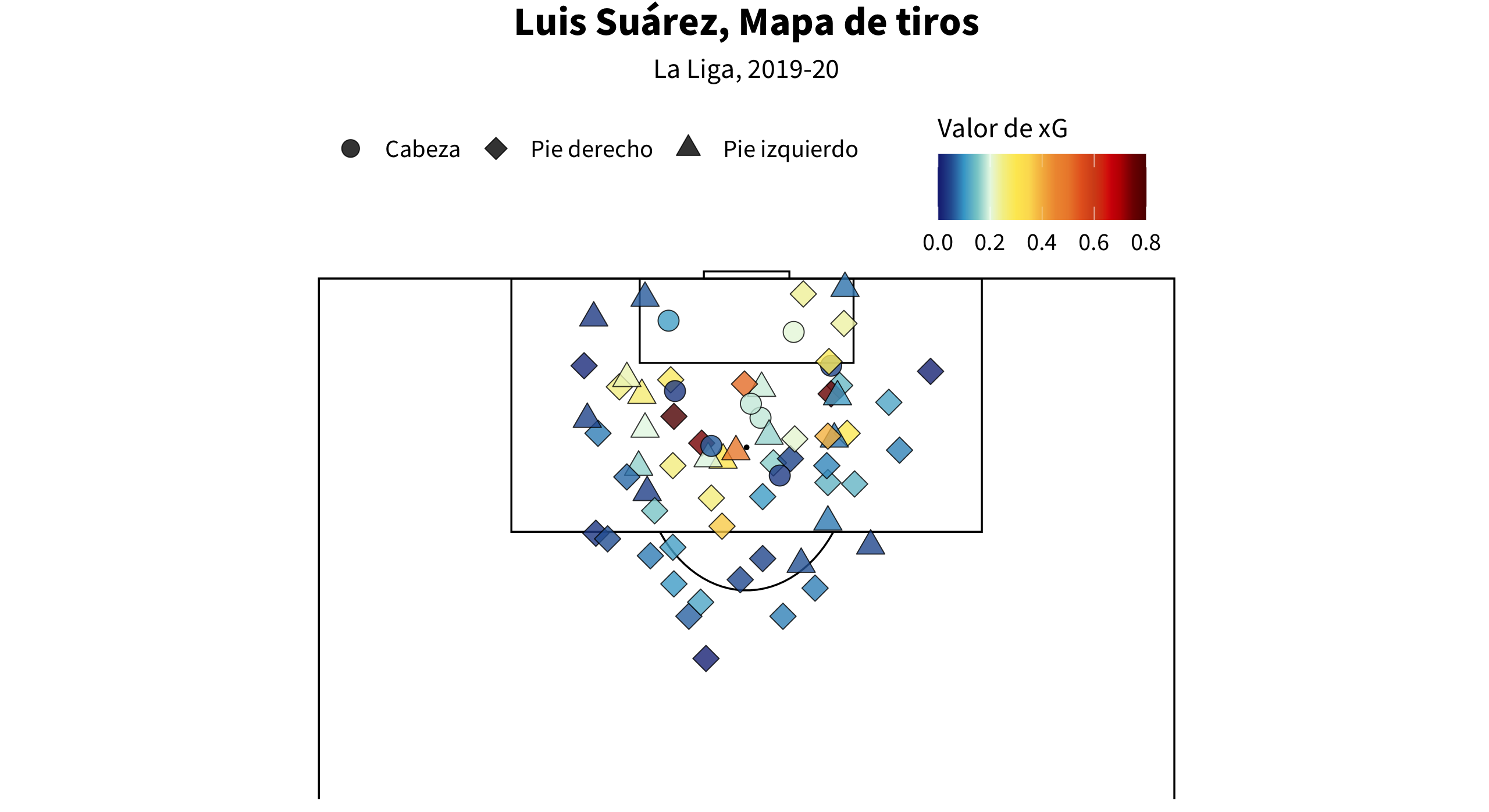
Bueno, ahora podemos crear un mapa de tiros de un jugador.
shots = events %>%
filter(type.name=="Shot" & (shot.type.name!="Penalty" | is.na(shot.type.name)) & player.nickname=="Luis Suárez") %>% #1 mutate(shot.body_part_ESP.name = recode (shot.body_part.name, "Right Foot" = "Pie derecho", "Left Foot" = "Pie izquierdo", "Head" = "Cabeza")) #2
shotmapxgcolors <- c("#192780", "#2a5d9f", "#40a7d0", "#87cdcf", "#e7f8e6", "#f4ef95", "#FDE960", "#FCDC5F", "#F5B94D", "#F0983E", "#ED8A37", "#E66424", "#D54F1B", "#DC2608", "#BF0000", "#7F0000", "#5F0000") #3
ggplot() +
annotate("rect",xmin = 0, xmax = 120, ymin = 0, ymax = 80, fill = NA, colour = "black", size = 0.6) +
annotate("rect",xmin = 0, xmax = 60, ymin = 0, ymax = 80, fill = NA, colour = "black", size = 0.6) +
annotate("rect",xmin = 18, xmax = 0, ymin = 18, ymax = 62, fill = NA, colour = "black", size = 0.6) +
annotate("rect",xmin = 102, xmax = 120, ymin = 18, ymax = 62, fill = NA, colour = "black", size = 0.6) +
annotate("rect",xmin = 0, xmax = 6, ymin = 30, ymax = 50, fill = NA, colour = "black", size = 0.6) +
annotate("rect",xmin = 120, xmax = 114, ymin = 30, ymax = 50, fill = NA, colour = "black", size = 0.6) +
annotate("rect",xmin = 120, xmax = 120.5, ymin =36, ymax = 44, fill = NA, colour = "black", size = 0.6) +
annotate("rect",xmin = 0, xmax = -0.5, ymin =36, ymax = 44, fill = NA, colour = "black", size = 0.6) +
annotate("segment", x = 60, xend = 60, y = -0.5, yend = 80.5, colour = "black", size = 0.6)+
annotate("segment", x = 0, xend = 0, y = 0, yend = 80, colour = "black", size = 0.6)+
annotate("segment", x = 120, xend = 120, y = 0, yend = 80, colour = "black", size = 0.6)+
theme(rect = element_blank(),
line = element_blank()) +
annotate("point", x = 108 , y = 40, colour = "black", size = 1.05) +
annotate("path", colour = "black", size = 0.6, x=60+10*cos(seq(0,2*pi,length.out=2000)), y=40+10*sin(seq(0,2*pi,length.out=2000)))+
annotate("point", x = 60 , y = 40, colour = "black", size = 1.05) +
annotate("path", x=12+10*cos(seq(-0.3*pi,0.3*pi,length.out=30)), size = 0.6, y=40+10*sin(seq(-0.3*pi,0.3*pi,length.out=30)), col="black") +
annotate("path", x=107.84-10*cos(seq(-0.3*pi,0.3*pi,length.out=30)), size = 0.6, y=40-10*sin(seq(-0.3*pi,0.3*pi,length.out=30)), col="black") +
geom_point(data = shots, aes(x = location.x, y = location.y, fill = shot.statsbomb_xg, shape = shot.body_part_ESP.name), size = 6, alpha = 0.8) + #4
theme(axis.text.x=element_blank(),
axis.title.x = element_blank(),
axis.title.y = element_blank(),
plot.caption=element_text(size=13,family="Source Sans Pro", hjust=0.5, vjust=0.5),
plot.subtitle = element_text(size = 18, family="Source Sans Pro", hjust = 0.5),
axis.text.y=element_blank(), legend.position = "top",
legend.title=element_text(size=18,family="Source Sans Pro"),
legend.text=element_text(size=16,family="Source Sans Pro"),
legend.margin = margin(c(15, 30, -60, 10)), legend.key.size = unit(1.5, "cm"),
legend.key.width = unit(0.95, "cm"),
plot.title = element_text(margin = margin(r = 10, b = 10), face="bold",size = 26, family="Source Sans Pro", colour = "black", hjust = 0.5),
legend.direction = "horizontal",
axis.ticks=element_blank(),
aspect.ratio = c(65/100),
plot.background = element_rect(fill = "white"),
strip.text.x = element_text(size=13,family="Source Sans Pro")) +
labs(title = "Luis Suárez, Mapa de tiros", subtitle = "La Liga, 2019-20") + #5
scale_fill_gradientn(colours = shotmapxgcolors, limit = c(0,0.8), oob=scales::squish, name = "Valor de xG") + #6
scale_shape_manual(values = c("Cabeza" = 21, "Pie derecho" = 23, "Pie izquierdo" = 24), name ="") + #7
guides(fill = guide_colourbar(title.position = "top"),
shape = guide_legend(override.aes = list(size = 5, fill = "black"))) + #8
coord_flip(xlim = c(85, 125)) #9
1. Un filtro básico para eliminar los penaltis y elegir el jugador que quieras.
2. Para asignar los nombres castellanos a las partes del cuerpo.
3. Los colores para los valores de xG.
4. Empezamos a trazar los tiros con geom_point. Elegimos el valor de xG como la fill y la parte del cuerpo como la shape (forma) de los puntos. Se pueden cambiarlos por otros valores, como el tipo de asistencia, el resultado del tiro (gol, a puerta, bloqueado...), etc...
5. Para poner el título y subtítulo a la visualización.
6. Los parámetros para la fill de los tiros. En el parámetro colours, hacemos referencia a los colores que elegimos antes.
7. Para elegir las formas para cada parte del cuerpo. Los números son los números asignados a las formas estándares de ggplot. Una lista aquí. Las formas de 21 en adelante son los que tienen colores interiores (controlados por fill).
8. Con guides() podemos ajustar la forma, el color y otras cosas de la leyenda. En este ejemplo, estamos cambiando la posición del título de la fill para situarlo por encima de la leyenda. Asimismo, estamos cambiando el tamaño y color de las formas.
9. coord_flip() cambia los ejes para mostrar el campo de juego de forma vertical. Con xlim podemos poner un límite al eje x para mostrar sólo una parte del campo.
El resultado será esta visualización:
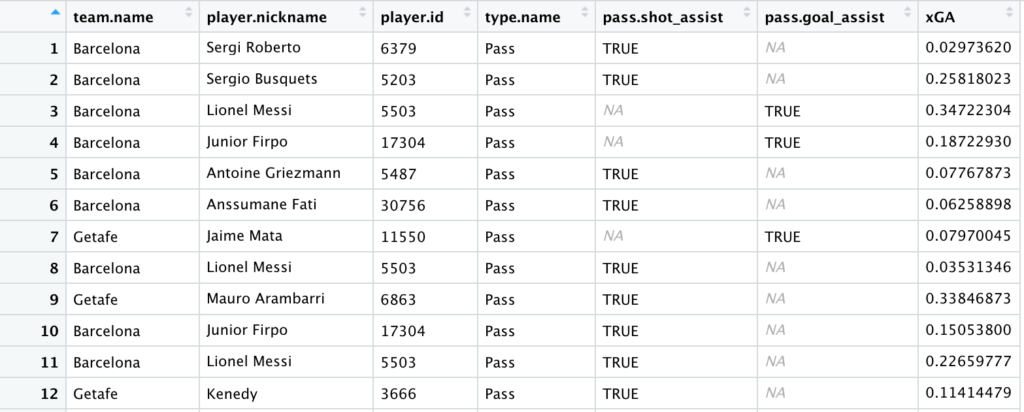
xG + xG Asistido
No existe una columna para los valores de xG asistido en nuestros datos pero es algo que podemos generar si conectamos el valor de xG de un tiro a la pase que creó la ocasión usando la función join.
Aquí está el código:
xGA = events %>%
filter(type.name=="Shot") %>% #1
select(shot.key_pass_id, xGA = shot.statsbomb_xg) #2
shot_assists = left_join(events, xGA, by = c("id" = "shot.key_pass_id")) %>% #3
select(team.name, player.nickname, player.id, type.name, pass.shot_assist, pass.goal_assist, xGA ) %>%
filter(pass.shot_assist==TRUE | pass.goal_assist==TRUE) #4
1. Filtrando a los tiros, los únicos eventos que tienen valores de xG.
2. Con Select() podemos elegir las columnas que queremos incluir en el Data Frame. Elegimos la columna 'shot.key_pass_id', una variable de los tiros que da la ID de la pase que creó el tiro. Asimismo, renombramos la columna 'shot.statsbomb_xg' a 'xGA' para que ya tenga el nombre correcto cuando la juntamos con las pases.
3. left_join() es una función para combinar las columnas de dos Data Frames diferentes. En este ejemplo, estamos juntado nuestro Data Frame inicial (‘events’) y el que hemos creado (‘xGA’). La clave es la parte by = c(“id” = “shot.key+pass_id) que junta los dos Data Frames cuando la columna de ID en ‘events’ coincide con la columna ‘shot.key_pass_id’ en ‘xGA’. Ahora, la columna ‘xGA’ muestra el valor de xG de cada pase clave y asistencia.
4. Filtrando los datos a las pases claves y asistencias. El resultado debería ser algo así:
Todo bien hasta ahora. ¿Pero qué tenemos que hacer para crear un gráfico de estos datos? Por ejemplo, un ranking de jugadores que incluye tanto el xG como el xGA.
player_xGA = shot_assists %>%
group_by(player.nickname, player.id, team.name) %>%
summarise(xGA = sum(xGA, na.rm = TRUE)) #1
player_xG = events %>%
filter(type.name=="Shot") %>%
filter(shot.type.name!="Penalty" | is.na(shot.type.name)) %>%
group_by(player.nickname, player.id, team.name) %>%
summarise(xG = sum(shot.statsbomb_xg, na.rm = TRUE)) %>%
left_join(player_xGA) %>%
mutate(xG_xGA = sum(xG+xGA, na.rm =TRUE) ) #2
player_minutes = get.minutesplayed(events)
player_minutes = player_minutes %>%
group_by(player.id) %>%
summarise(minutes = sum(MinutesPlayed)) #3
player_xG_xGA = left_join(player_xG, player_minutes) %>%
mutate(nineties = minutes/90,
xG_90 = round(xG/nineties, 2),
xGA_90 = round(xGA/nineties,2),
xG_xGA90 = round(xG_xGA/nineties,2) ) #4
chart = player_xG_xGA %>%
filter(minutes>=900)
chart<-chart %>%
select(1, 9:10)%>%
pivot_longer(-player.nickname, names_to = "variable", values_to = "value") %>%
filter(variable=="xG_90" | variable=="xGA_90") #6
1. Agrupando los datos por jugador y calculando sus totales de xGA para la temporada.
2. Eliminando los penaltis, calculando los totales de xG para cada jugador y sumando el xG y xGA para crear una nueva columna con la suma de los dos.
3. Una función para importar los minutos disputados de cada jugador.
4. Juntando el xG y xGA a los minutos y calculando las cifras por cada 90 minutos en el campo.
5. Aquí creamos un Data Frame para el gráfico, con un filtro para incluir sólo a jugadores con 900 o más minutos disputados.
6. La función pivot_longer() aplana los datos para crear filas individuales para cada variable y valor relacionada a un jugador. Es más fácil visualizarlo:
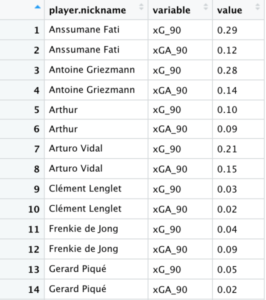
Tenemos los datos preparados para crear el gráfico.
ggplot(chart, aes(x =reorder(player.nickname, value), y = value, fill=fct_rev(variable))) + #1
geom_bar(stat="identity", colour="white")+
labs(title = "xG + xG Asistido", subtitle = "Barcelona, La Liga, 2019-20", x="", y="Por cada 90 minutos", caption ="Mínimo de 900 minutos jugados")+
theme(axis.text.y = element_text(size=14, color="#333333", family="Source Sans Pro"),
axis.title = element_text(size=14, color="#333333", family="Source Sans Pro"),
axis.text.x = element_text(size=14, color="#333333", family="Source Sans Pro"),
axis.ticks = element_blank(),
panel.background = element_rect(fill = "white", colour = "white"),
plot.background = element_rect(fill = "white", colour ="white"),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
plot.title=element_text(size=24, color="#333333", family="Source Sans Pro" , face="bold"),
plot.subtitle=element_text(size=18, color="#333333", family="Source Sans Pro", face="bold"),
plot.caption=element_text(color="#333333", family="Source Sans Pro", size =10),
text=element_text(family="Source Sans Pro"),
legend.title=element_blank(),
legend.text = element_text(size=14, color="#333333", family="Source Sans Pro"),
legend.position = "bottom") + #2
scale_fill_manual(values=c("#3371AC", "#DC2228"), labels = c( "xGA","xG")) + #3
scale_y_continuous(expand = c(0, 0), limits= c(0,max(chart$value) + 0.5)) + #4
coord_flip()+ #5
guides(fill = guide_legend(reverse = TRUE)) #6
1. Usamos reorder() para poner los jugadores en orden de su suma de xG y xGA. Hemos puesto el ‘variable’ como la fill de la barra. Así podemos poner los dos datos juntos en la misma barra con un color distinto para cada uno de los dos.
2. La función labs() controla el título, el subtítulo y las etiquetas de los ejes. La función theme() controla la tipografía, el color del fondo y cosas así.
3. Aquí estamos eligiendo los colores para cada dato (xG = rojo; xGA = azul) y creando la etiqueta.
4. Poniendo un límite al eje y. En este caso hemos usado el valor máximo + 0.3.
5. Cambiando los ejes para tener un diagrama de barras horizontal en vez de vertical.
6. Tenemos que invertir la leyenda para que muestre los datos en el mismo orden que el diagrama. El resultado final será esta visualización:
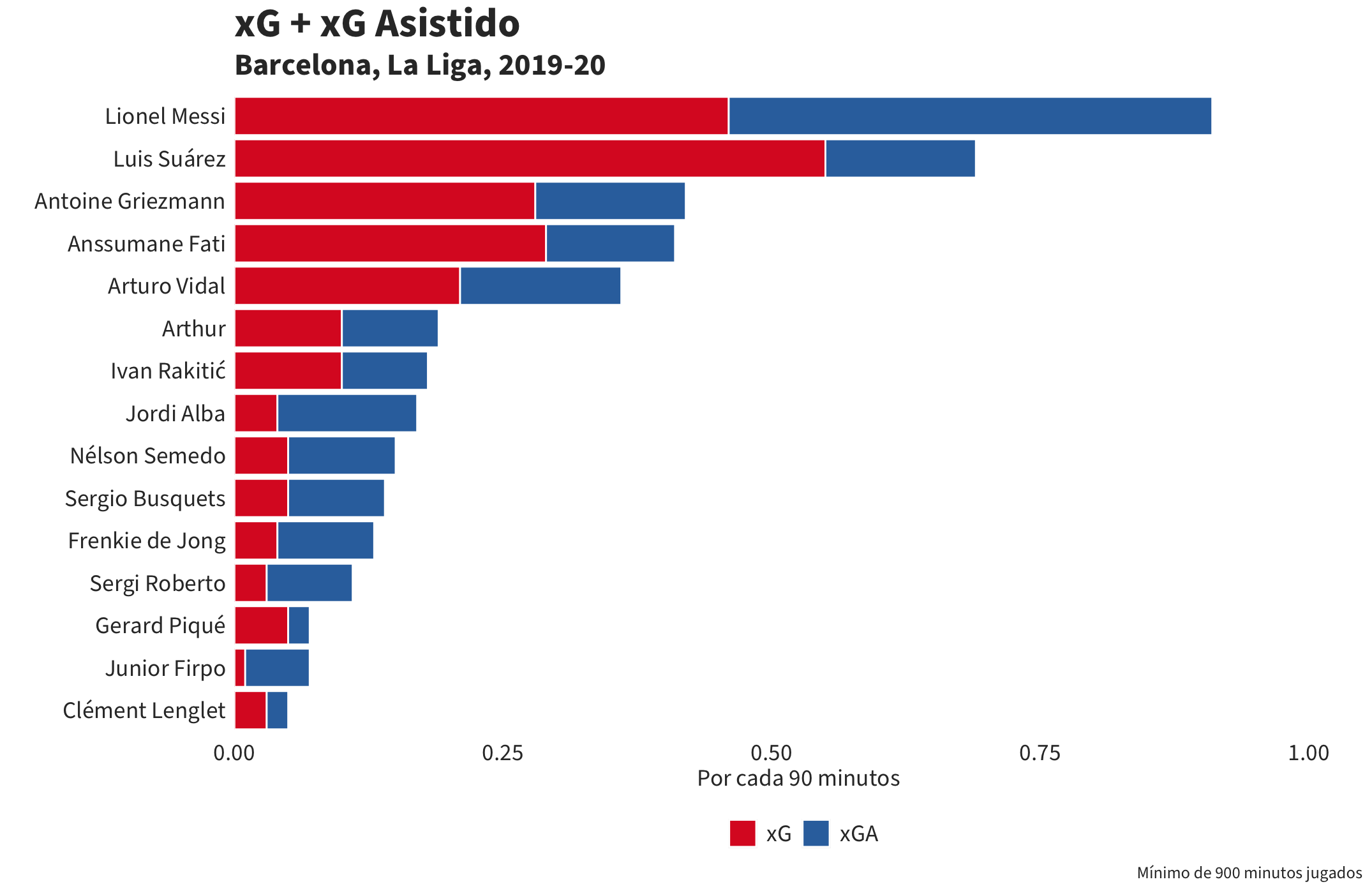
Existen muchas variaciones que podéis hacer con un diagrama de barras así: presiones, dividido entre campo propio y campo contrario; incursiones al área, dividido entre pases y conducciones; pases, dividido entre los dos pies. Nuestra especificación de datos incluye los nombres de todos los variables que podéis utilizar.
Ahora es el turno de vosotros. Podéis compartir sus resultados con nosotros: @statsbombes en Twitter. Cabe mencionar que además del nuestro paquete de R, tenemos uno de Python, StatsBombPy. Podéis encontrar todos los detalles en nuestro Github.