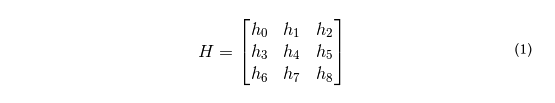Hace menos de tres años, StatsBomb revolucionó la industria de los datos en fútbol con el lanzamiento de StatsBomb Data. En marzo, lo vamos a hacer de nuevo.
En mayo de 2018, presentamos nuestro feed de datos exclusivo, con el doble de información por partido que los competidores.
Incluyendo aspectos como los eventos de presión, posicionamiento del portero y nuestros Freeze Frames con la máxima precisión. Esto supuso un salto en un campo que había carecido de innovación en los últimos años.Entre otras cosas, esto ha permitido grandes mejoras en nuestro modelo de Goles Esperados. No siendo suficiente con ser el mejor modelo disponible, recientemente le dimos una vuelta más incluyendo la altura del remate.
Además, nuestros datos incluyen una dimensión totalmente novedosa del análisis defensivo permitiendo medir aspectos defensivos nunca antes medidos y proporcionando de este modo una ventaja competitiva a nuestros clientes tanto en el mercado de traspasos como en análisis de equipos. Y por si eso no fuera suficiente, incluimos por primera vez un enfoque totalmente nuevo para evaluar a los porteros con datos avanzados.
Desde el lanzamiento en 2018, nuestros más de 80 clientes han sido capaces de mantener una ventaja competitiva respecto a sus competidores. Ellos ya saben de la calidad de nuestro producto, nuestro servicio de atención al cliente y nuestras herramientas vanguardistas que nos sitúan varios años por delante de cualquiera en la industria.Y precisamente por ello, nuestros clientes fueron los primeros en mostrar su entusiasmo al contarles el desarrollo de nuestro nuevo producto hace un par de semanas. Ahora lo podemos anunciar por fin para todo el mundo:
Presentando StatsBomb 360:
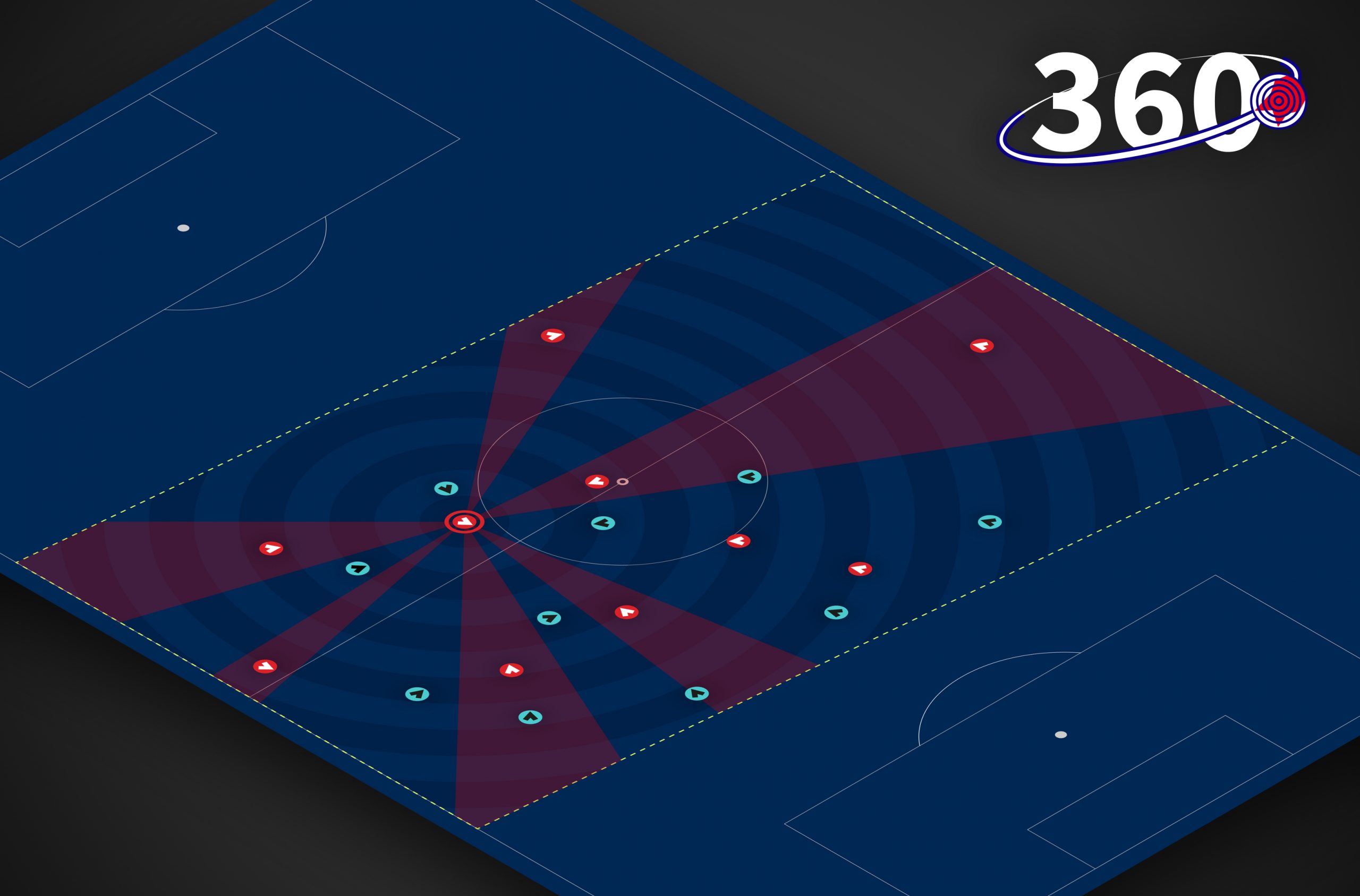
StatsBomb 360 son datos de evento contextuales. ¿Qué significa esto? Que a partir de ahora tendremos un freeze frame para cada evento que recogemos mostrando la posición de todos los jugadores en la imagen para cada evento del partido (aprox. 3300 por partido). Esto nos va a permitir descubrir un rango de información nueva que quedaba total o parcialmente oculta en los datos de eventos básicos. Entre otras cosas tendremos aspectos como:
Pases que rompen líneas
Recepciones entre líneas, al pie, o al espacio
Distancia respecto a los defensores en cada frame
Líneas de pase abiertas… ¡y cerradas!
Defensive Island Events (DIEs) - un nuevo evento que muestra dónde los equipos crean situaciones de 1v1 donde los defensores están sin coberturas/ayudas cercanas
Formación defensiva en cada evento.
Todo ello disponible a través de la API.Y lo mejor de todo, esto solo es la punta del iceberg de todo lo que será posible con StatsBomb 360. Os desvelaremos más detalles en marzo en nuestro evento online StatsBomb Evolve el 17 de Marzo. El evento es totalmente gratuito e invitamos a todo el que quiera a inscribirse.
El equipo de StatsBomb presentará nuestras novedades en todos los campos incluyendo:
StatsBomb 360 - nuestros nuevos datos
StatsBomb LIVE - los mejores datos en directo para medios, clubes
StatsBomb Analytics - nuestro nuevo modelo Goal Value Added (GVA) entre otras novedades
La Primera División de España es la liga menos goleadora de las cinco grandes de Europa, pero aún así han pasado muchas cosas interesantes en lo que va de temporada.
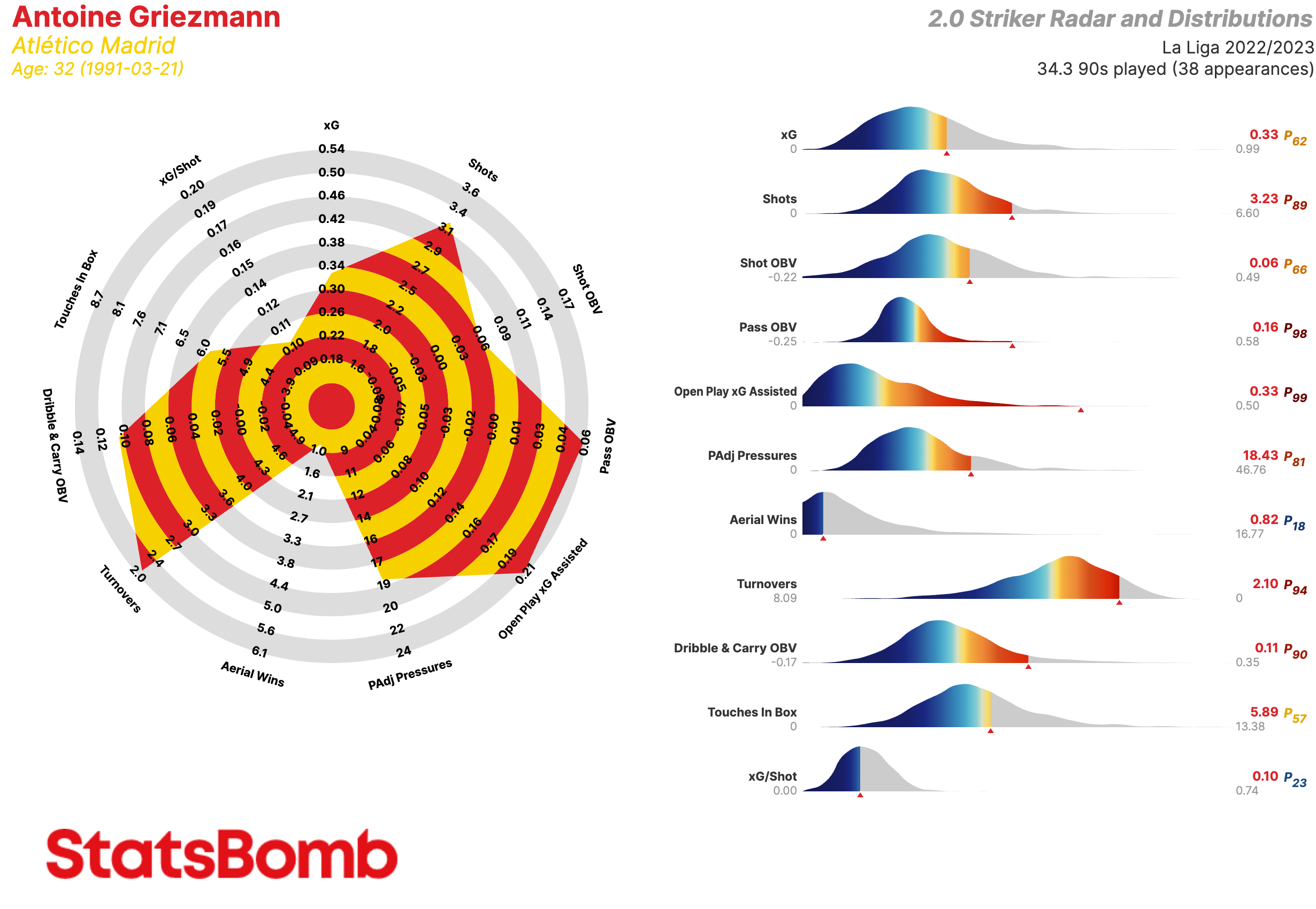
Atlético Madrid, líder arrollador
El Atlético Madrid es el único equipo aparte del Barcelona y el Real Madrid que ha ganado La Liga en las últimas 16 temporadas y el equipo de Diego Simeone tiene muchas posibilidades de volver a hacerlo en la 2020-21. Es el líder actual, con 10 puntos de ventaja y un partido menos jugado. Si es capaz de mantener su ritmo actual de 50 puntos en 19 partidos, igualará el mayor número de puntos de la historia de La Liga: 100. Lo más probable es que no lo haga.
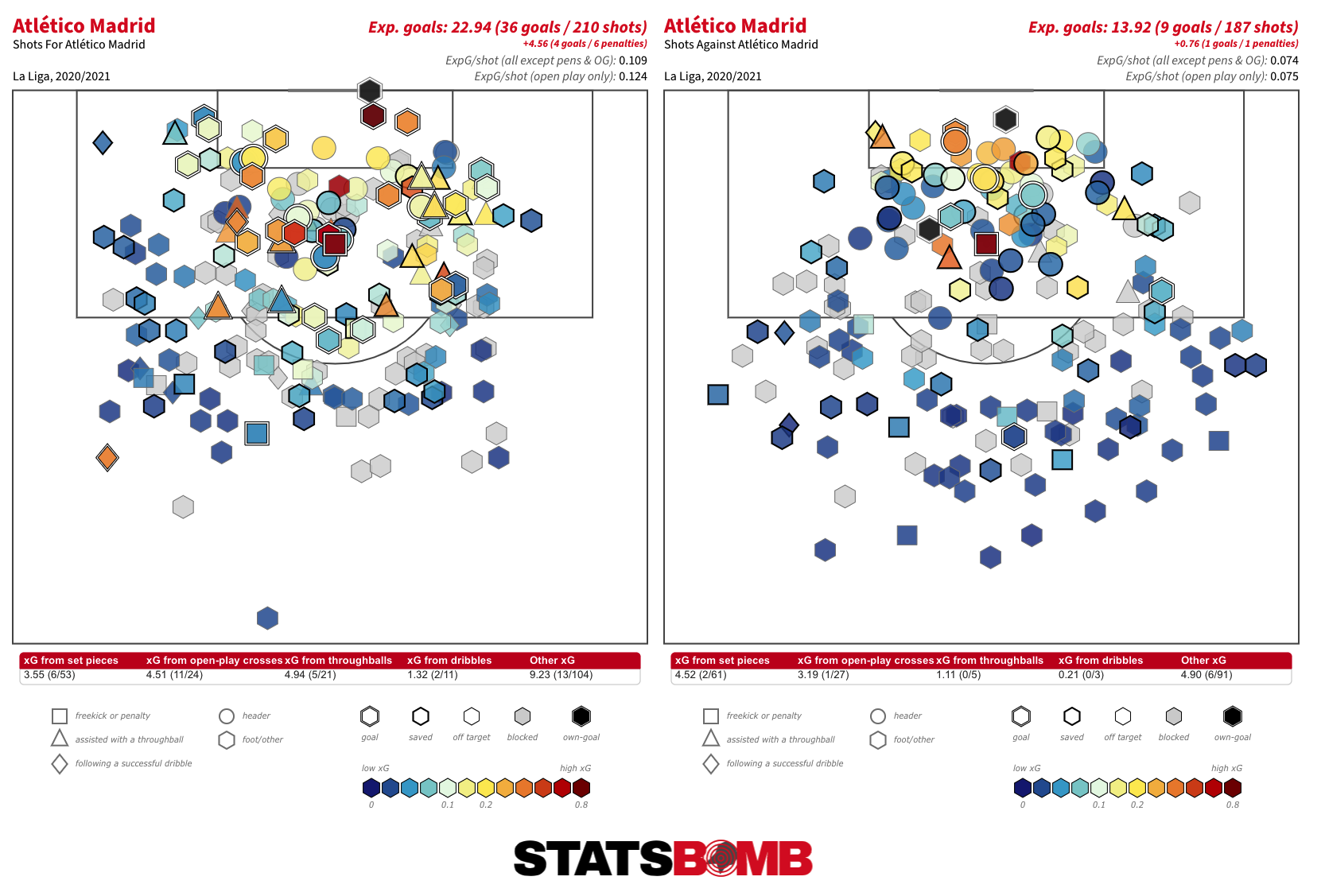
En lo que va de temporada, ningún equipo ha rendido más por encima de sus números esperados que el Atlético. Está rindiendo por encima de lo esperado en ambos extremos del campo, pero sobre todo en ataque, donde ha marcado alrededor de 13 goles más que su suma de goles esperados (xG).
Es lo contrario de lo que ocurrió la temporada pasada, cuando a esta altura de la campaña todos sus delanteros estaban rindiendo por debajo de su xG. Esta vez todos están rindiendo por encima: Luis Suárez, Marcos Llorente, João Félix, Ángel Correa, incluso Yannick Carrasco.
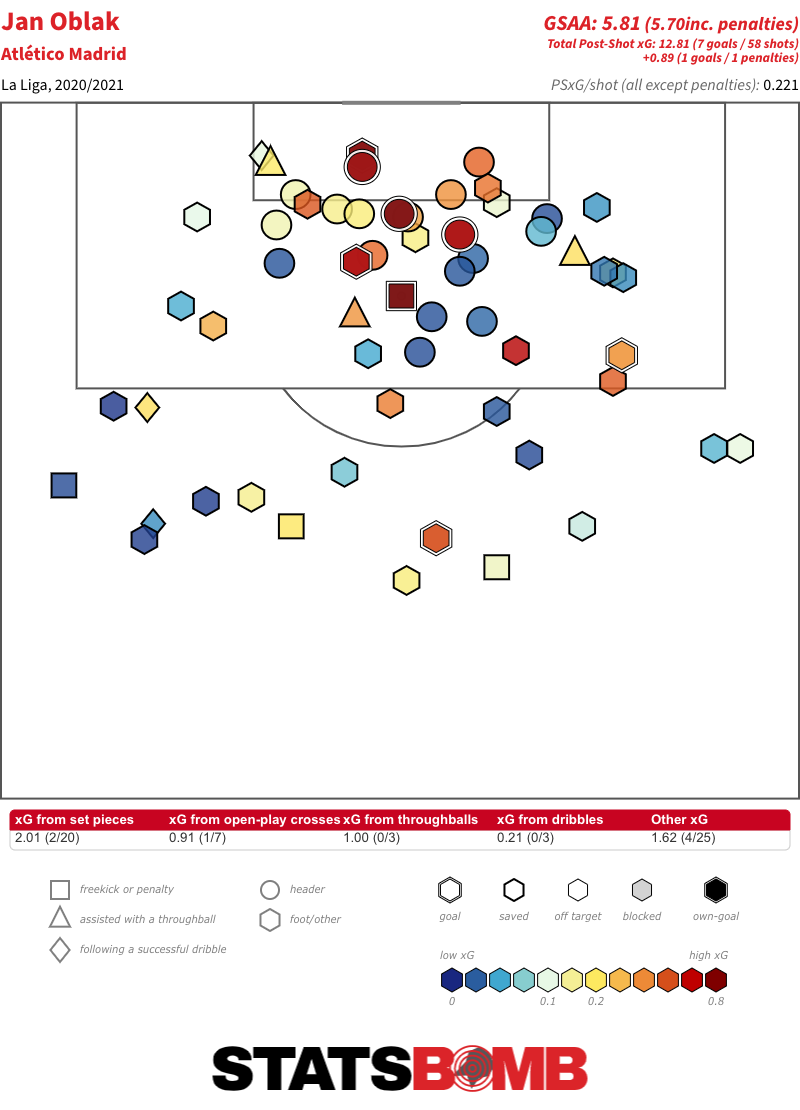
Es probable que esto se equilibre un poco en la segunda vuelta de la temporada, pero en el otro extremo del campo, el Atlético tiene un portero más que capaz de seguir rindiendo por encima de lo esperado, uno que ha demostrado año tras año su capacidad de hacerlo. Tanto en cifras absolutas como en cifras ajustadas en función de la cantidad de tiros a los que cada portero se ha enfrentado, Jan Oblak ha sido el mejor portero de La Liga esta temporada.
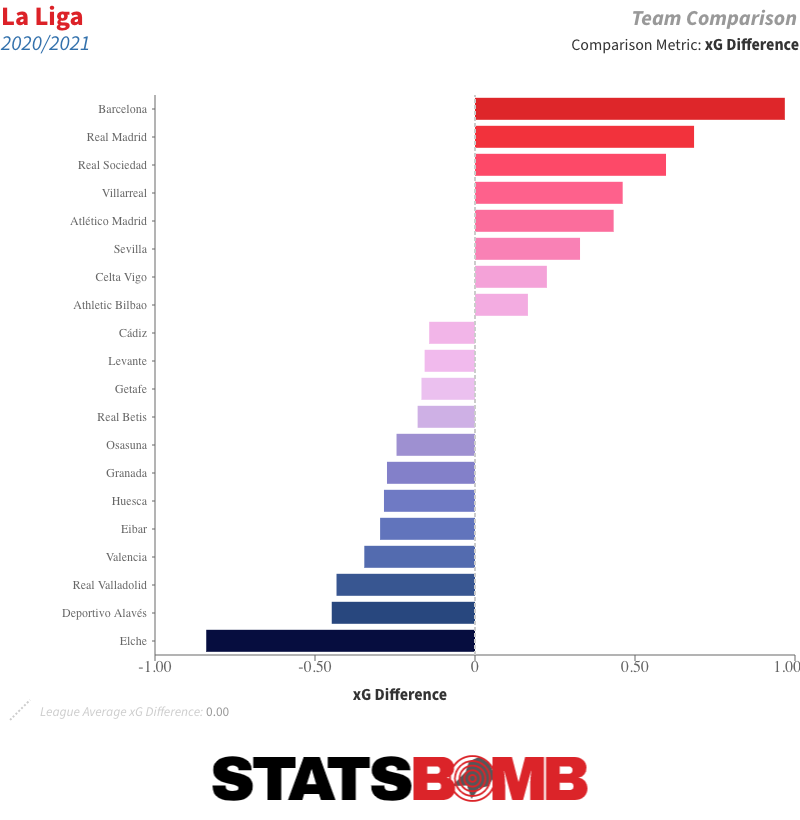
La realidad es que incluso si el ritmo de acumulación de puntos del Atlético se ralentiza un poco, probablemente tenga una ventaja lo suficientemente grande como para no ser alcanzado por sus rivales. El Barcelona está recuperándose bien después de un comienzo difícil de la temporada, al menos en cuanto a resultados, bajo la dirección de Ronald Koeman. Tiene los mejores números subyacentes de La Liga...
...pero tendría que mantener un ritmo casi insoportable para alcanzar al Atlético. El Real Madrid también tiene mejores números que el líder actual, pero ha sufrido demasiados vaivenes. Aunque queda casi media temporada por delante y no se puede cantar el alirón antes de tiempo, el Atlético ya parece medio campeón.
Una cuestión de presión
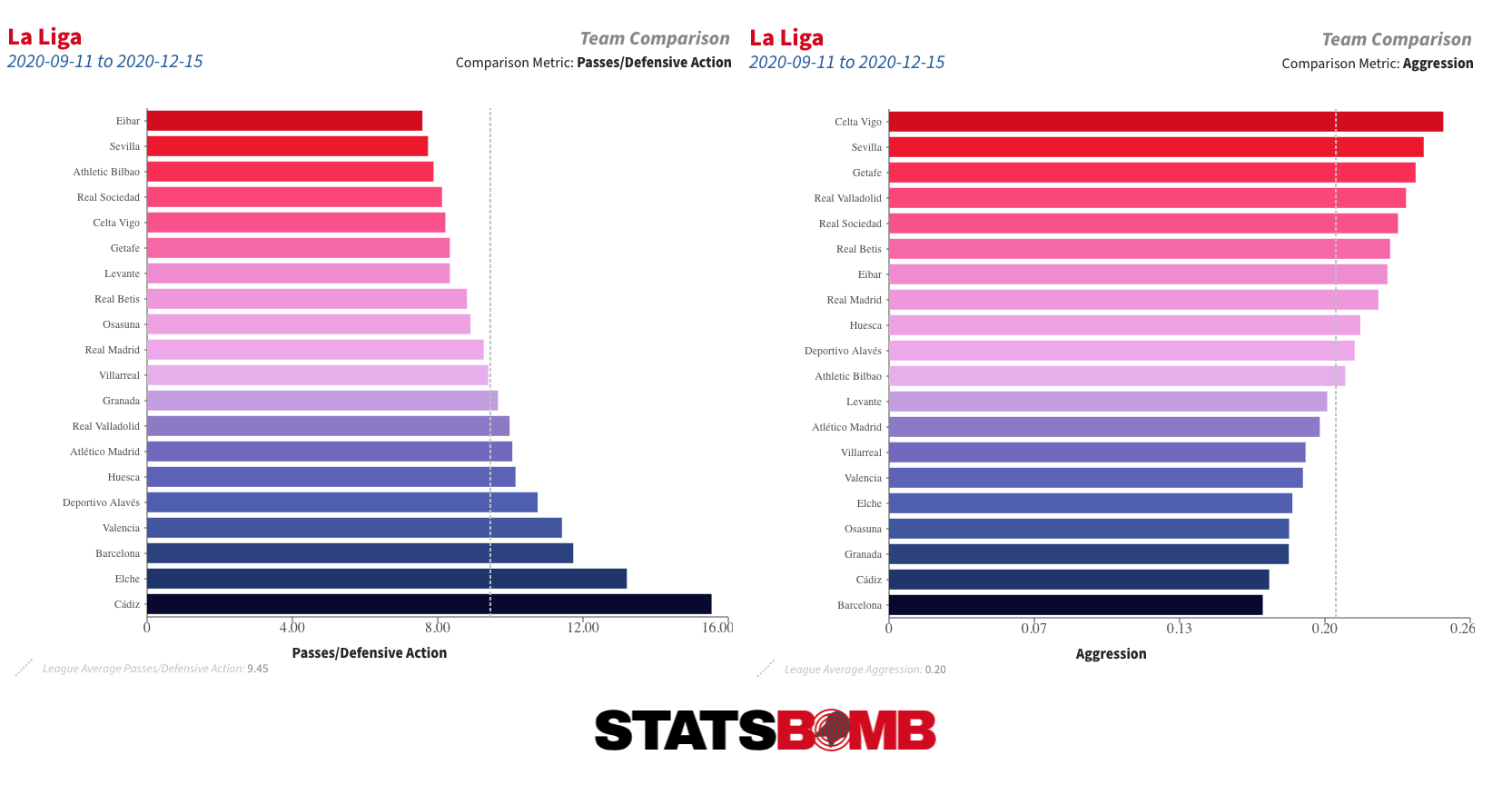
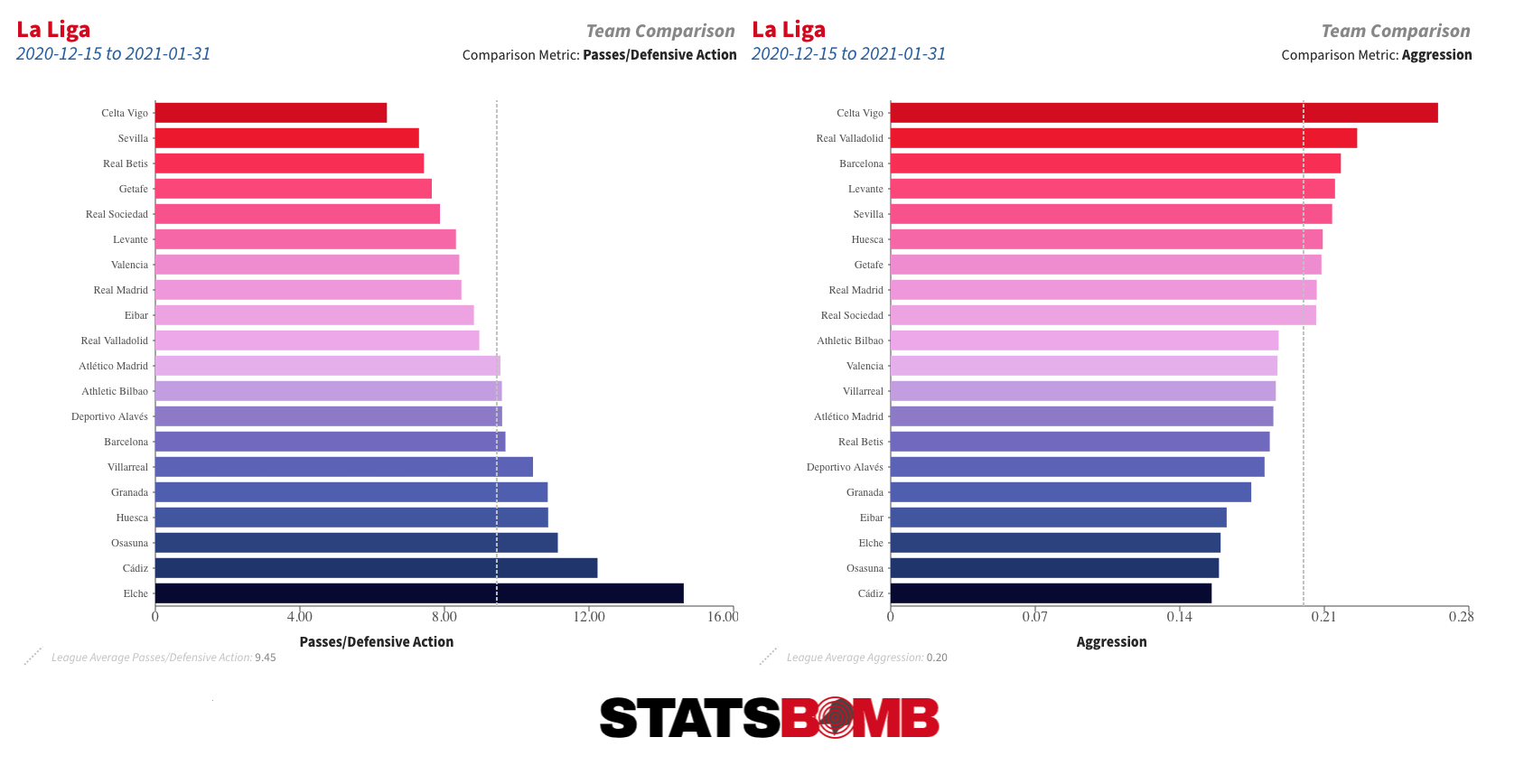
Uno de los cambios más evidentes tras la llegada de Koeman al banquillo del Barça fue que el equipo inmediatamente empezó a disputar la posesión del balón con menos frecuencia, sobre todo en campo contrario. Ya sea por PPDA (Pases por acción defensiva) o por Agresividad (el porcentaje de recepciones de rivales que reciben presión en los dos segundos posteriores) fue uno de los equipos más pasivos de La Liga durante los primeros meses de la temporada.
De hecho, según el PPDA, el Barcelona de Koeman en eso primeros 10 u 11 partidos fue la más pasiva de todas las versiones del Barça en nuestra base de datos, que empieza en 2004. Sin embargo, desde entonces, parece que ha habido un cambio a un planteamiento ligeramente más proactivo, más en línea con el estilo de juego durante tramos de la etapa de Ernesto Valverde.
En parte, esto podría deberse simplemente al calendario. El Barcelona tenía partidos de Champions durante la mayor parte de los primeros tres meses de la temporada, lo que tal vez hizo necesario un planteamiento menos intensivo en ese tramo de la campaña. Habrá que esperar a una muestra más grande para ver si este cambio se mantiene durante el resto de la temporada.
En el extremo opuesto se encuentra un Celta Vigo que se ha vuelto notablemente más proactivo sin balón esta temporada, y particularmente desde que Eduardo Coudet reemplazó a Óscar García como entrenador en noviembre. El equipo está defendiendo más arriba que antes y ha registrado el mayor porcentaje de acciones agresivas de La Liga.
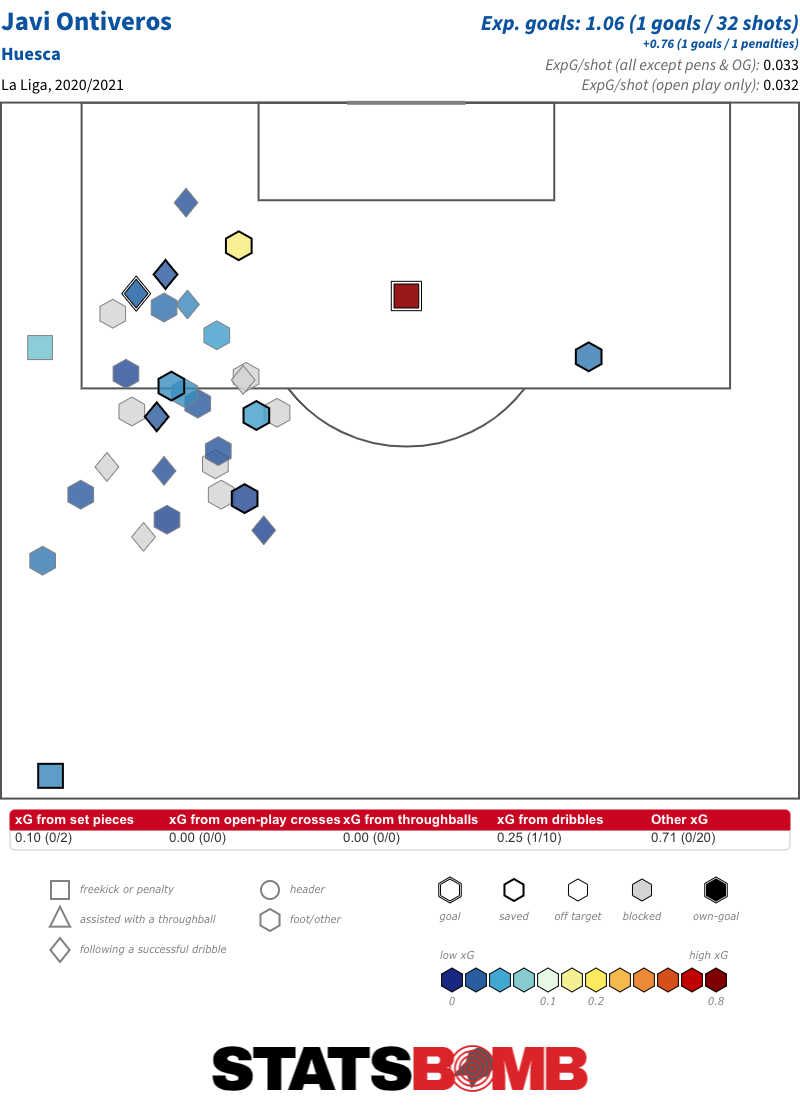
El positivismo implacable de Javi Ontiveros
El Huesca ha estado en la zona de descenso desde la séptima jornada, pero está todo tan apretado ahí abajo, con sólo seis puntos entre el Huesca, colista, y el Eibar, decimoquinto, que aún tiene posibilidades de evitar el descenso en la segunda vuelta de la temporada. Si consigue evitarlo, es probable que Javi Ontiveros tenga un papel protagonista. Ya sea como titular o desde el banquillo, el marbellí es un jugador intensamente positivo. Ya sea mediante pases o conducciones, es implacable en el avance del balón...y mientras la localización de sus tiros deja mucho que desear...
...tiene un estilo de juego tan divertido que casi se le puede perdonar eso. No sólo genera muchos más tiros tras una conducción de diez metros o más por cada 90 minutos en el campo (1.47) que cualquier otro jugador de La Liga, sino que también lidera la división en cuanto a caños (por delante de Alberto Perea y Bryan Gil) y se sitúa entre los tres primeros en cuanto a regates completados. Ontiveros es quizás el jugador más entretenido de La Liga.
Otros datos
Nabil Fekir del Real Betis es el jugador que más tiros ha realizado sin marcar en las cinco grandes ligas: 53. Además, sólo ha convertido uno de sus tres penaltis.
Una de las numerosas ventajas de los datos de StatsBomb es que recogemos el pie con el que se ejecuta cada pase. Con esta información, podemos ver que, por segunda temporada consecutiva, Tomás Pina del Alavés es el jugador más ambidiestro de La Liga. La temporada pasada, ejecutó un 50% de sus pases con cada pie. Este vez, ha realizado un 51% con el pie izquierdo y un 49% en el pie derecho. Pedro Bigas es otro jugador que siempre figura entre los más ambidiestros de La Liga y ahí está otra vez al lado de Pina.
En StatsBomb ya tenemos los datos más precisos y detallados que existen, pero seguimos innovando y por ello vamos a revolucionar la industria (una vez más). Únete a nosotros el 17 de marzo para conocer el próximo avance de los datos en fútbol: StatsBomb Evolve.
Hace un par de meses, añadimos los datos del Barcelona de la temporada 2019-20 a nuestro repositorio de la carrera completa de Lionel Messi y la gente ya ha empezado a hacer cosas interesantes con ellos. Por ejemplo, Eoin O’Brien ha creado una página interactiva en la que puedes ver los redes de pases del Barça en cada partido de la temporada.
Ahora, vamos a enseñar algunas cosas que podéis hacer con estos datos en R, un programa y lenguaje de programación que solemos utilizar en nuestro trabajo de análisis. Ya hemos escrito una introducción al uso de StatsBomb Data en R y recomendamos que la leéis antes de intentar hacer las cosas incluidas en este artículo, que tiene como base un artículo en inglés por nuestro analista Euan Dewar.
Podéis hacer estas cosas con tanto los datos de Messi como los de las otras competiciones que ofrecemos de manera gratuita, incluyendo los últimos mundiales tanto masculino como femenino, la temporada de liga del mítico Arsenal de la 2003-04 y las ligas femeninas de Inglaterra y los Estados Unidos. Podéis encontrar una lista completa de las competiciones aquí.
Importar los datos
Primero, tenemos que importar los datos del Barcelona de la 2019-20:
Para crear visualizaciones es útil tener los nombres cortos de los jugadores en vez de sus nombres completos con segundo apellido, etc... Este código crea otra columna con este detalle ('player.nickname'):
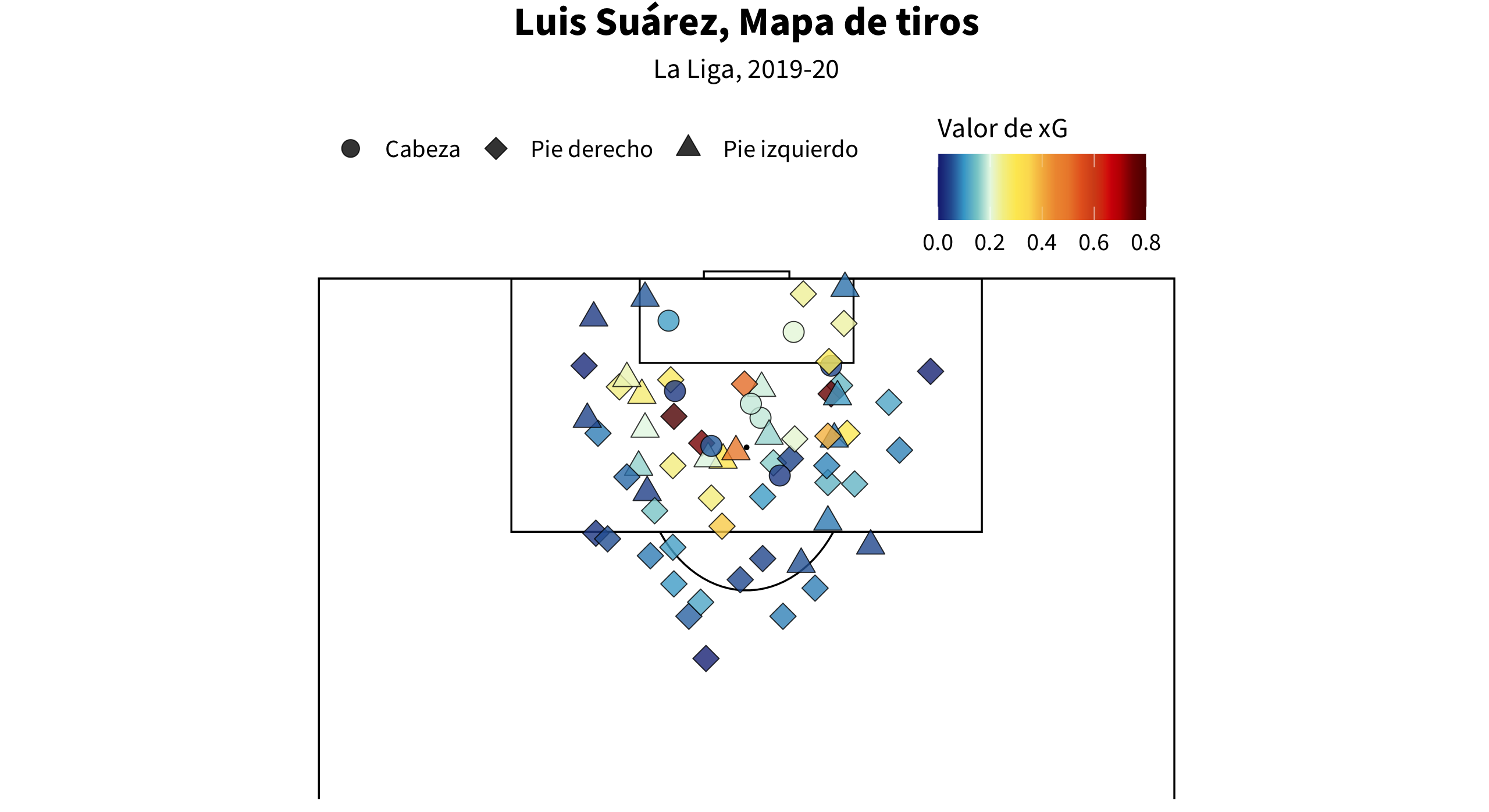
1. Un filtro básico para eliminar los penaltis y elegir el jugador que quieras.
2. Para asignar los nombres castellanos a las partes del cuerpo.
3. Los colores para los valores de xG.
4. Empezamos a trazar los tiros con geom_point. Elegimos el valor de xG como la fill y la parte del cuerpo como la shape (forma) de los puntos. Se pueden cambiarlos por otros valores, como el tipo de asistencia, el resultado del tiro (gol, a puerta, bloqueado...), etc...
5. Para poner el título y subtítulo a la visualización.
6. Los parámetros para la fill de los tiros. En el parámetro colours, hacemos referencia a los colores que elegimos antes.
7. Para elegir las formas para cada parte del cuerpo. Los números son los números asignados a las formas estándares de ggplot. Una lista aquí. Las formas de 21 en adelante son los que tienen colores interiores (controlados por fill).
8. Con guides() podemos ajustar la forma, el color y otras cosas de la leyenda. En este ejemplo, estamos cambiando la posición del título de la fill para situarlo por encima de la leyenda. Asimismo, estamos cambiando el tamaño y color de las formas.
9. coord_flip() cambia los ejes para mostrar el campo de juego de forma vertical. Con xlim podemos poner un límite al eje x para mostrar sólo una parte del campo.
El resultado será esta visualización:
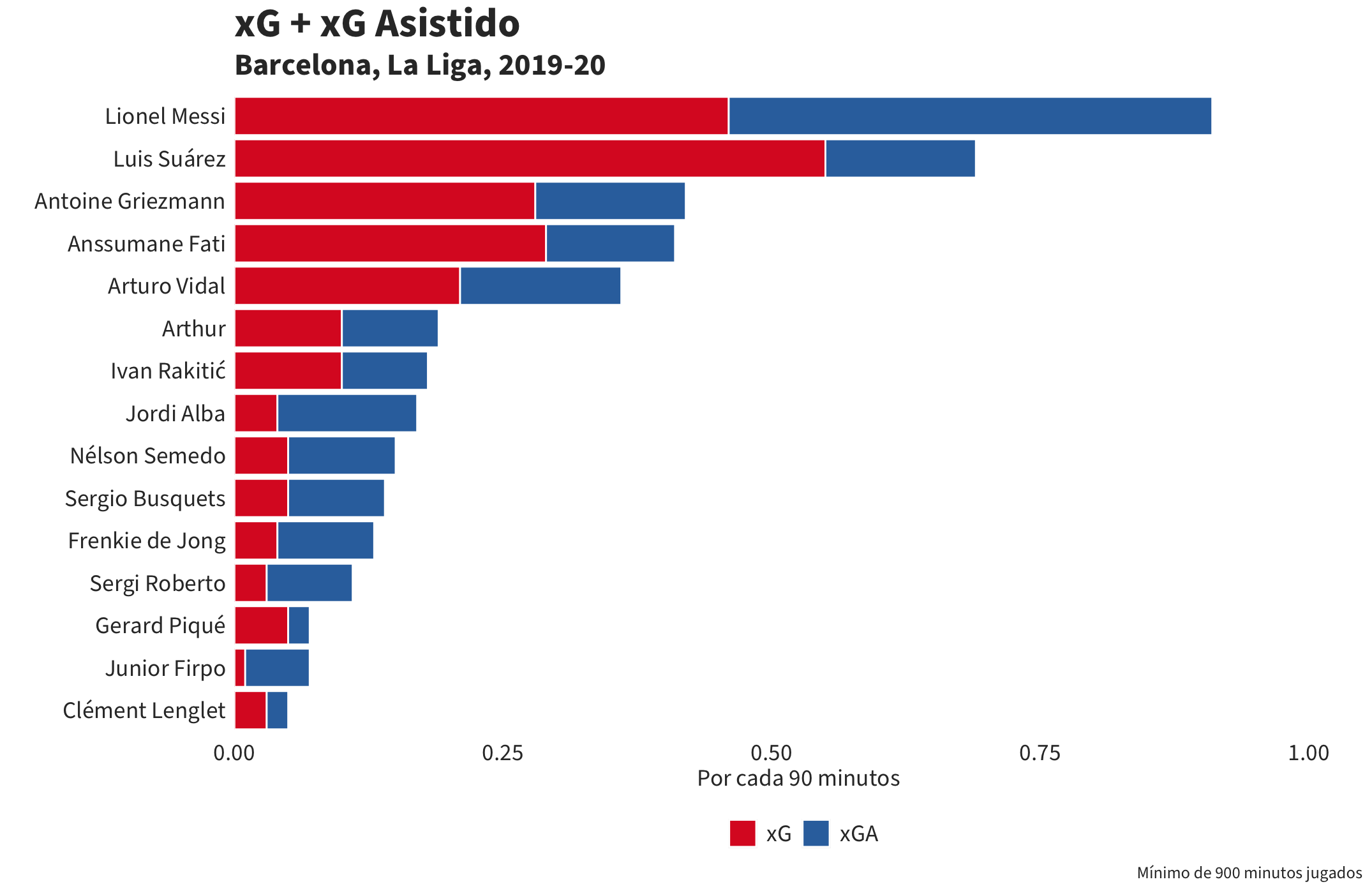
xG + xG Asistido
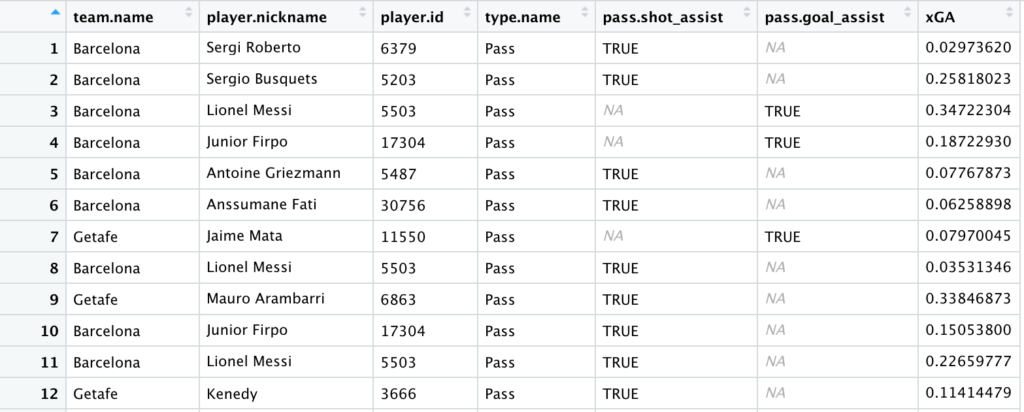
No existe una columna para los valores de xG asistido en nuestros datos pero es algo que podemos generar si conectamos el valor de xG de un tiro a la pase que creó la ocasión usando la función join.
1. Filtrando a los tiros, los únicos eventos que tienen valores de xG.
2. Con Select() podemos elegir las columnas que queremos incluir en el Data Frame. Elegimos la columna 'shot.key_pass_id', una variable de los tiros que da la ID de la pase que creó el tiro. Asimismo, renombramos la columna 'shot.statsbomb_xg' a 'xGA' para que ya tenga el nombre correcto cuando la juntamos con las pases.
3. left_join() es una función para combinar las columnas de dos Data Frames diferentes. En este ejemplo, estamos juntado nuestro Data Frame inicial (‘events’) y el que hemos creado (‘xGA’). La clave es la parte by = c(“id” = “shot.key+pass_id) que junta los dos Data Frames cuando la columna de ID en ‘events’ coincide con la columna ‘shot.key_pass_id’ en ‘xGA’. Ahora, la columna ‘xGA’ muestra el valor de xG de cada pase clave y asistencia.
4. Filtrando los datos a las pases claves y asistencias. El resultado debería ser algo así:
Todo bien hasta ahora. ¿Pero qué tenemos que hacer para crear un gráfico de estos datos? Por ejemplo, un ranking de jugadores que incluye tanto el xG como el xGA.
1. Agrupando los datos por jugador y calculando sus totales de xGA para la temporada.
2. Eliminando los penaltis, calculando los totales de xG para cada jugador y sumando el xG y xGA para crear una nueva columna con la suma de los dos.
3. Una función para importar los minutos disputados de cada jugador.
4. Juntando el xG y xGA a los minutos y calculando las cifras por cada 90 minutos en el campo.
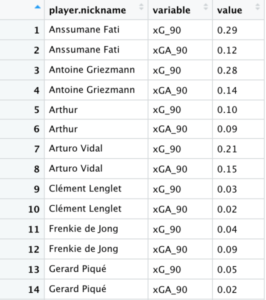
5. Aquí creamos un Data Frame para el gráfico, con un filtro para incluir sólo a jugadores con 900 o más minutos disputados.
6. La función pivot_longer() aplana los datos para crear filas individuales para cada variable y valor relacionada a un jugador. Es más fácil visualizarlo:
Tenemos los datos preparados para crear el gráfico.
1. Usamos reorder() para poner los jugadores en orden de su suma de xG y xGA. Hemos puesto el ‘variable’ como la fill de la barra. Así podemos poner los dos datos juntos en la misma barra con un color distinto para cada uno de los dos.
2. La función labs() controla el título, el subtítulo y las etiquetas de los ejes. La función theme() controla la tipografía, el color del fondo y cosas así.
3. Aquí estamos eligiendo los colores para cada dato (xG = rojo; xGA = azul) y creando la etiqueta.
4. Poniendo un límite al eje y. En este caso hemos usado el valor máximo + 0.3.
5. Cambiando los ejes para tener un diagrama de barras horizontal en vez de vertical.
6. Tenemos que invertir la leyenda para que muestre los datos en el mismo orden que el diagrama. El resultado final será esta visualización:
Existen muchas variaciones que podéis hacer con un diagrama de barras así: presiones, dividido entre campo propio y campo contrario; incursiones al área, dividido entre pases y conducciones; pases, dividido entre los dos pies. Nuestra especificación de datos incluye los nombres de todos los variables que podéis utilizar.
Ahora es el turno de vosotros. Podéis compartir sus resultados con nosotros: @statsbombes en Twitter. Cabe mencionar que además del nuestro paquete de R, tenemos uno de Python, StatsBombPy. Podéis encontrar todos los detalles en nuestro Github.
¡Esperamos que estéis disfrutando de nuestras previas de la nueva temporada de La Liga! Hemos hecho previas de los equipos de la Premier League en nuestra web inglés durante muchos años, pero este es el primer año en el que las estamos haciendo también para la liga española.
Hay diez previas esta temporada. Si existe suficiente interés, las haremos para toda La Liga el año que viene.
Si queréis leer más sobre las métricas y los conceptos incluidas en las previas, hemos escrito una serie de artículos en los que tratamos de explicar las nociones básicas del análisis de datos en el fútbol:
Asimismo, nuestro curso online Introducción al Análisis de Datos en Fútbol Profesional ya está disponible. Los goles esperados (xG), táctica ofensiva y defensiva, acciones a balón parado, análisis de equipos y más:
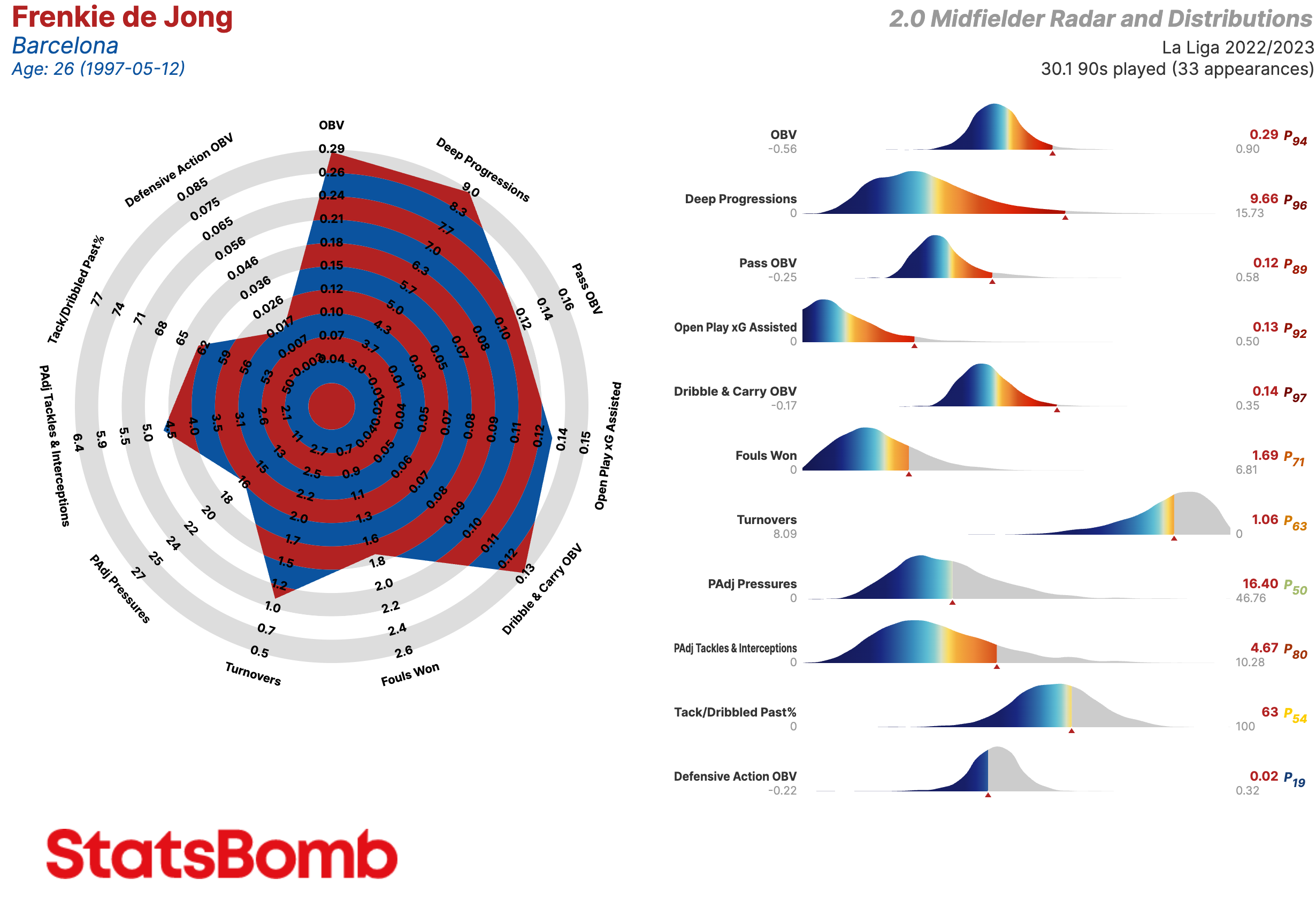
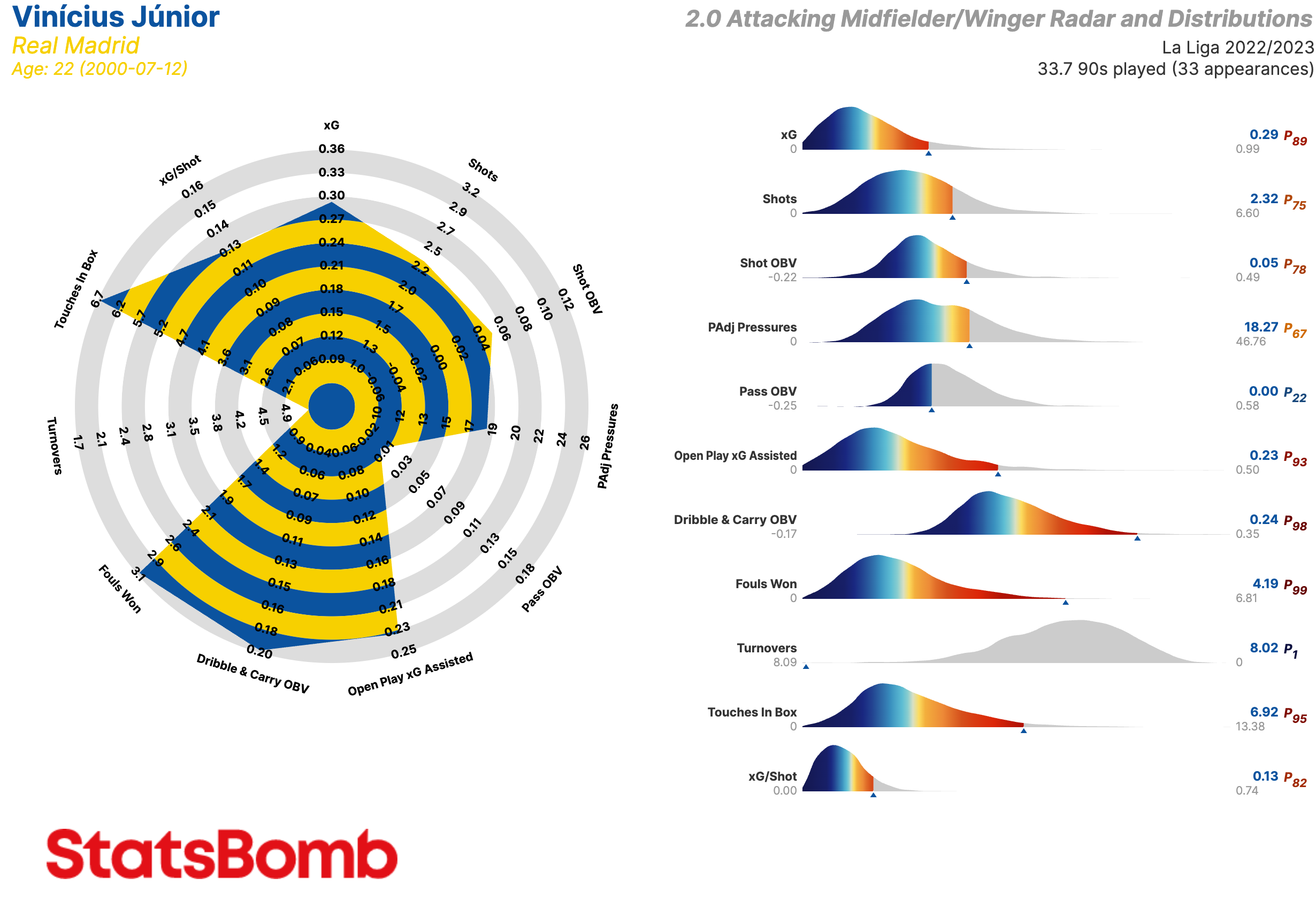
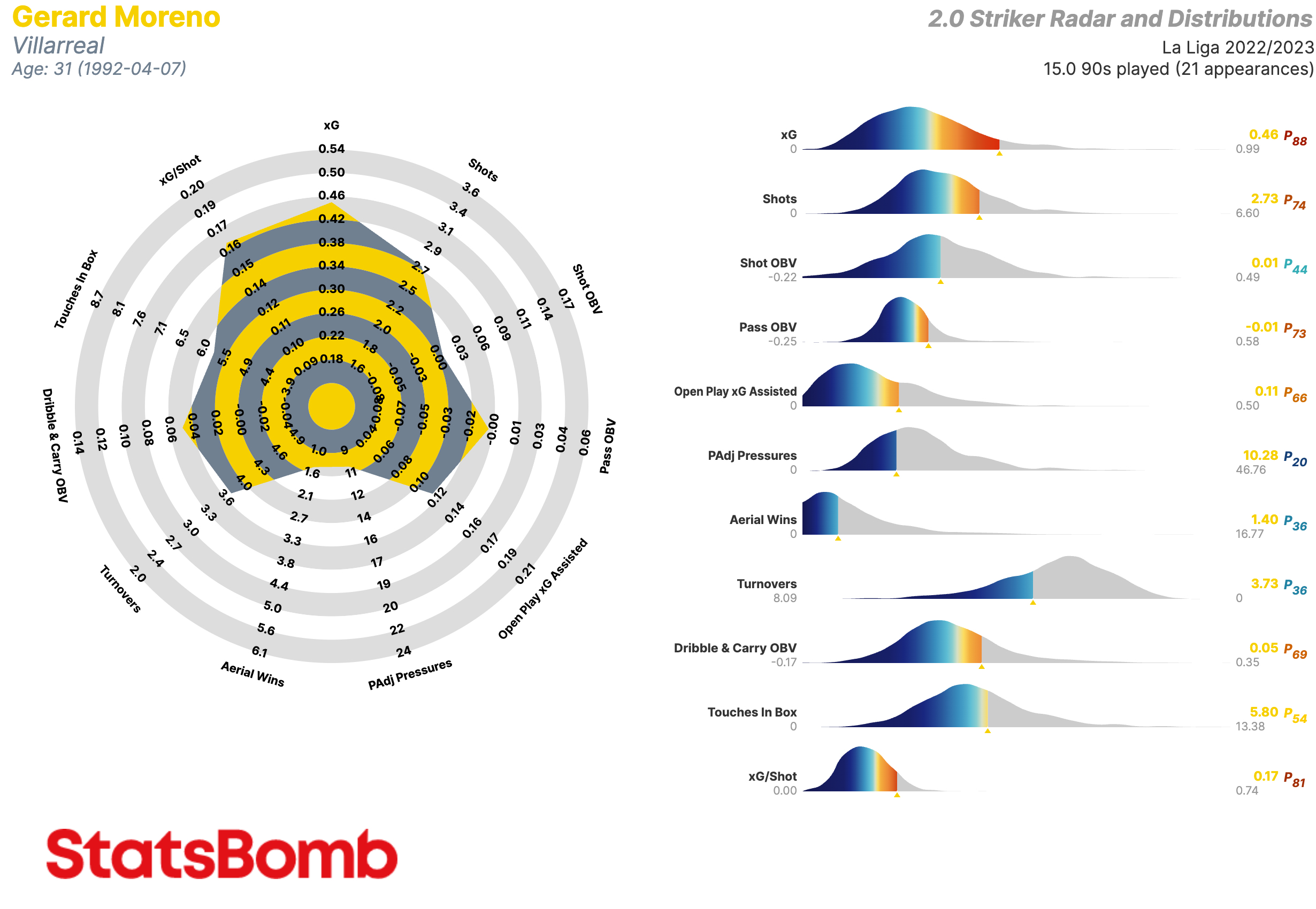
Los radares son el símbolo de StatsBomb, una manera original y práctica de visualizar datos tanto de jugadores como equipos. A pesar de que hoy en día parecen omnipresentes en los círculos de análisis de datos en el fútbol, siguen siendo una de las marcas distintivas de StatsBomb, puesto que estos fueron creados y popularizados aquí.
Sin embargo, hasta ahora no habíamos escrito algo en Castellano para ayudaros a interpretar los radares que utilizamos tanto en nuestros análisis como en las redes sociales.
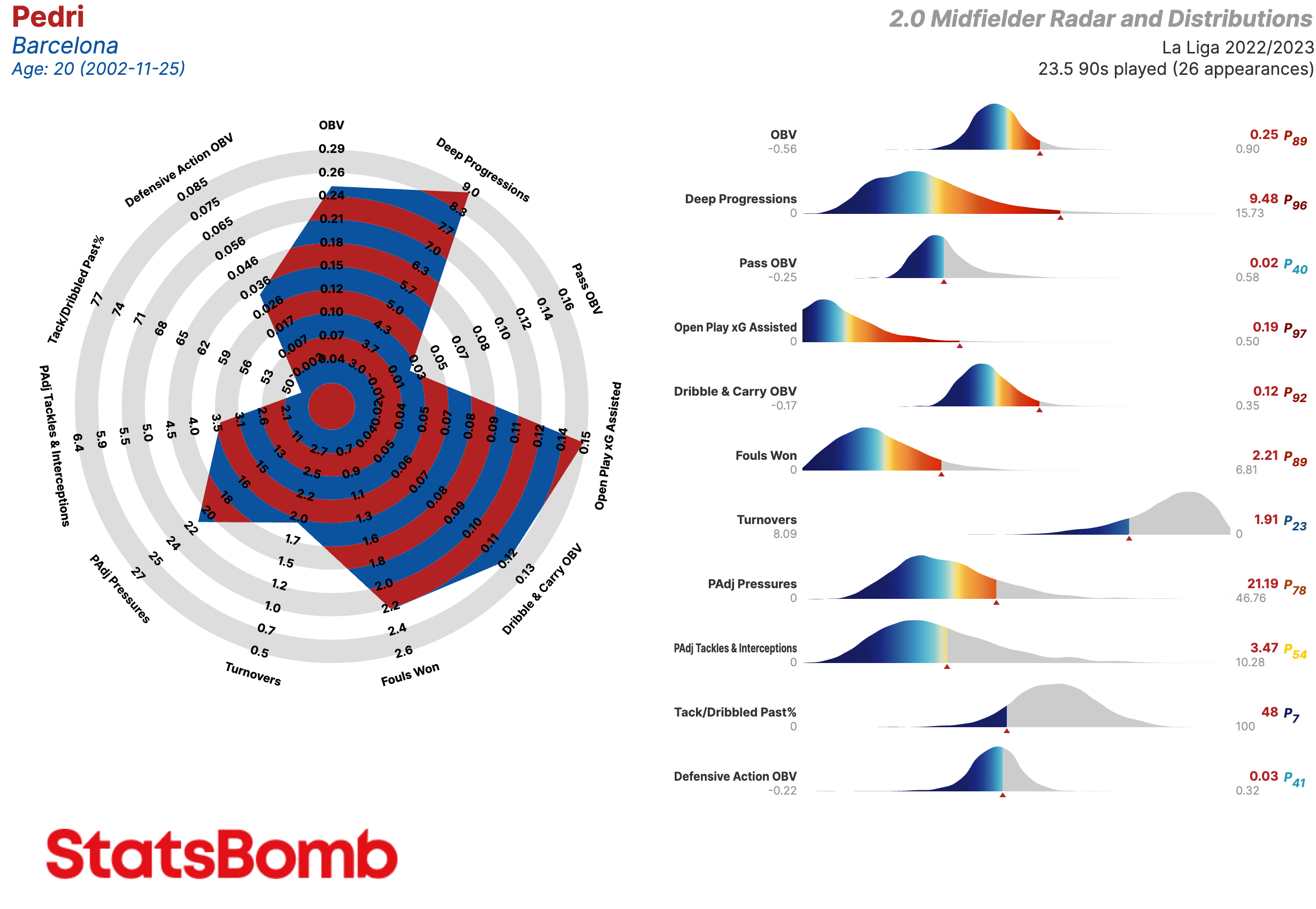
¿De qué estamos hablando? Aquí está un ejemplo de uno de nuestros radares.
Vamos a hablar de las métricas en sí más tarde, pero existen algunas cosas que tenemos que explicar antes.
Primero, los límites interiores y exteriores de los radares representan respectivamente los percentiles 5 y 95 de la distribución posicional para cada métrica en las cinco grandes ligas de Europa durante varias temporadas.
Segundo, la gráfica de distribución que se encuentra a la derecha del radar muestra donde cae el jugador dentro de la distribución de su posición en cada métrica. La flecha indica la posición del jugador mientras la paleta de colores da una idea del percentil en el que se encuentra. El percentil y el valor de la métrica están mostrados a la derecha de la gráfica.
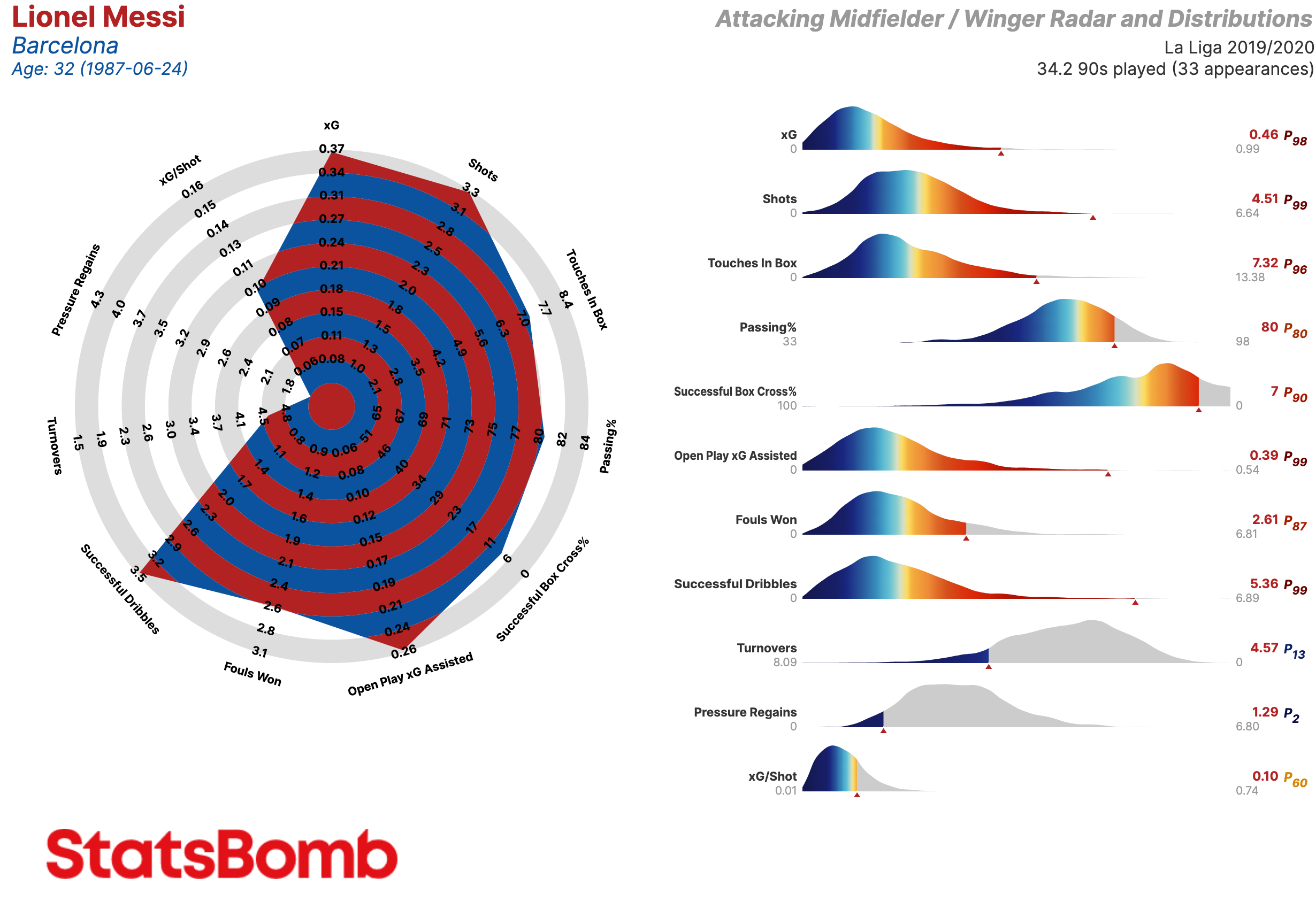
Las gráficas de distribución son una manera sencilla de visualizar que excepcional es un jugador como Lionel Messi.
Existen más opciones. Dentro del radar, podemos visualizar los percentiles en vez de los valores de cada métrica. A veces, en lugar de la gráfica de distribución, publicamos los radares con una tabla que contiene los detalles de la producción estadística del jugador. Asimismo, nuestros clientes tienen la oportunidad de personalizar las métricas incluidas para crear sus propios radares.
Apuntes Generales
Cuando hacemos referencia al xG, estamos hablando de los Goles Esperados, el marco general empleado en la mayoría de los análisis actuales. La explicación simplificada de esta métrica es que mide la probabilidad de que un tiro dado termine en gol. Sin embargo, va mucho más allá de eso, como explicamos en este artículo.
Todos los datos son por cada 90 minutos. Hemos explicado antes las razones por las cuales ajustamos los datos así, pero en breve, es la forma más sencilla y práctica de hacer comparaciones entre jugadores que han disputado diferentes cantidades de minutos a lo largo de una temporada.
Asimismo, ajustamos algunas de las métricas defensivas en función de la posesión. Este ajuste es una solución práctica para estandarizar los valores de modo que se pueden comparar entre diferentes jugadores corrigiendo aspectos relacionados con el estilo de juego de sus respectivos equipos. Damos una explicación más profunda aquí.
Algunos de los radares incluyen la métrica On-Ball Value (OBV). En resumen, OBV es un modelo que mide el cambio en la probabilidad de un equipo de marcar/conceder como resultado de una acción dada. Esto permite identificar las acciones más relevantes en una posesión y poder otorgar más mérito a las acciones con mayor impacto en la posesión.
Cabe mencionar que no todas las métricas miden la calidad del jugador y/o su rendimiento. Muchas de ellas son marcas estilísticas, particularmente en el caso de los defensores.
En octubre de 2023, actualizamos nuestras plantillas para cada posición para incluir algunas de nuestras nuevas métricas como OBV. Aquí están las versiones actuales:
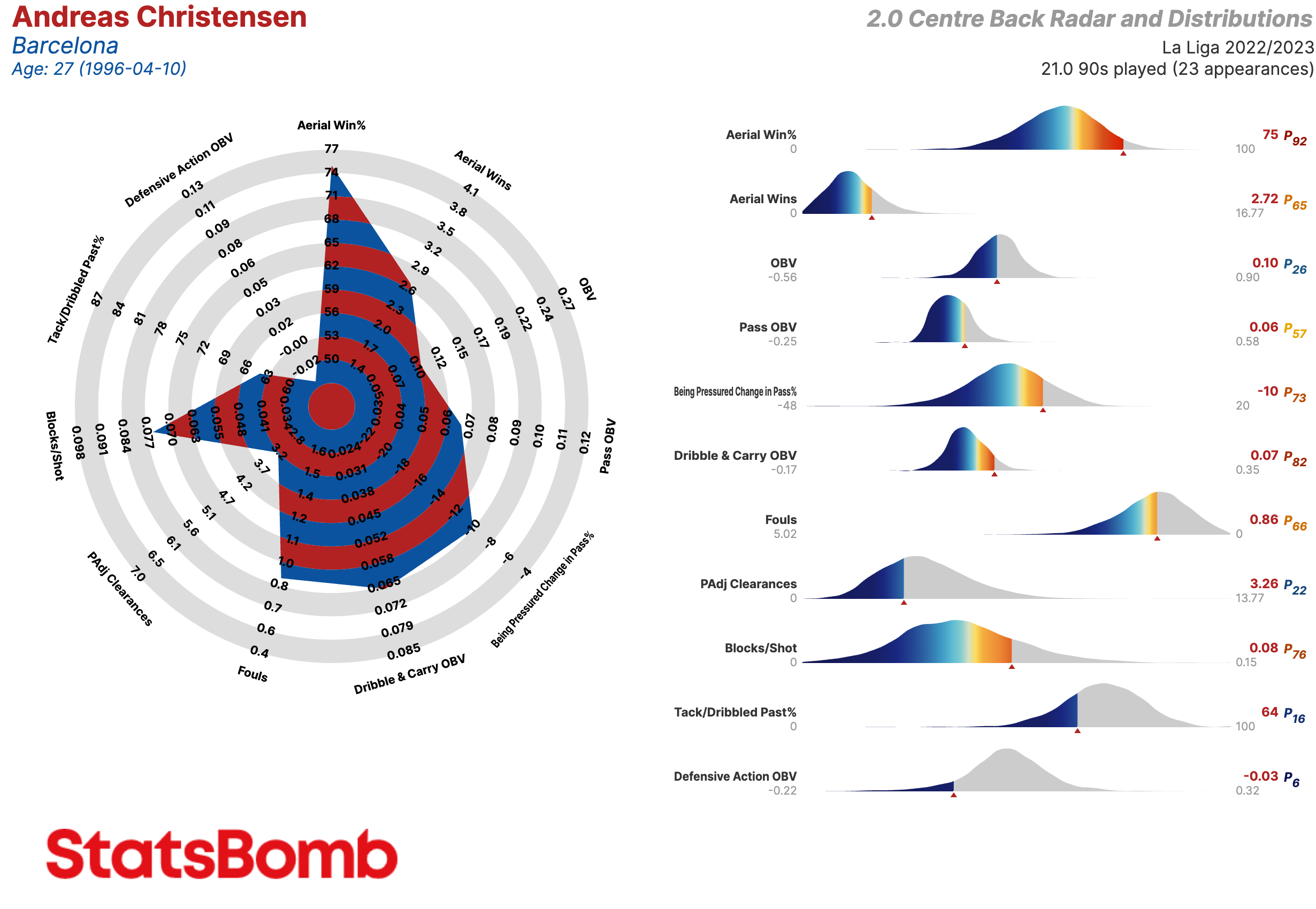
Centrales
Aerial Win%: Porcentaje de duelos aéreos ganados
Aerial Wins: Duelos aéreos ganados
OBV: Valor agregado en las acciones relacionadas con el balón
Pass OBV: Valor agregado mediante pases
Being Pressured Change in Pass %: El cambio en el porcentaje de acierto en el pase del jugador en los pases realizados bajo presión rival
Dribble & Carry OBV: Valor agregado mediante regates y conducciones
Fouls: Faltas
PAdj Clearances: Despejes ajustadas en función de la posesión
Blocks/Shot: Proporción de los tiros enfrentados que fueron bloqueados
Tack/Dribbled Past%: La proporción de entradas exitosas a ocasiones en que el oponente le/la regateó
PAdj Tackles: Entradas exitosas ajustadas en función de la posesión
Defensive Action OBV: Valor agregado mediante acciones defensivas
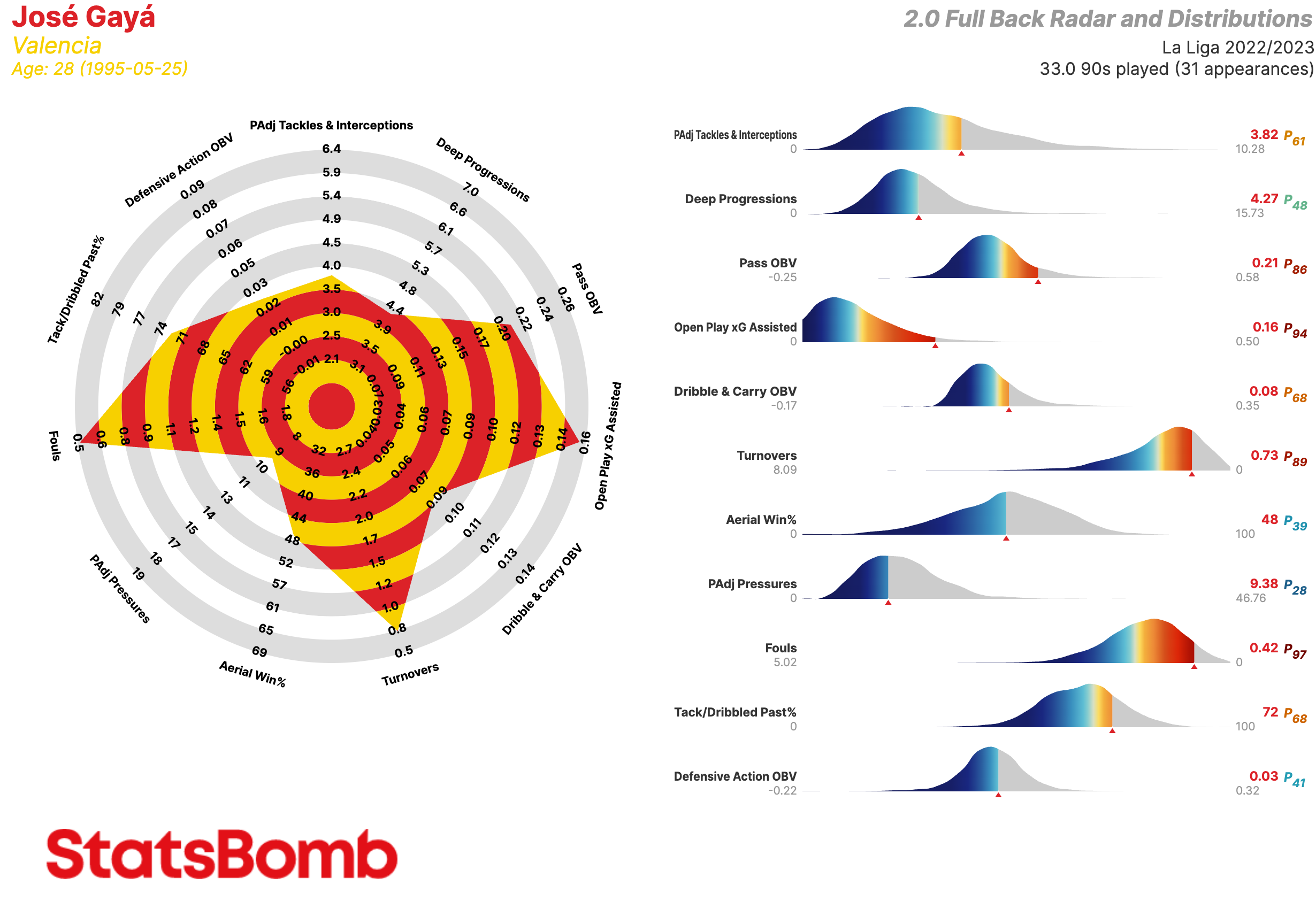
Laterales
PAdj Tackles & Interceptions: Entradas y interceptaciones ajustadas en función de la posesión
Deep Progressions: Incursiones en el último tercio a través de pases, regates o conducciones
Pass OBV: Valor agregado mediante pases
Open Play xG Assisted: Goles esperados asistidos en juego abierto (es decir, sin contar los que provienen de las acciones a balón parado)
Dribble & Carry OBV: Valor agregado mediante regates y conducciones
Turnovers: Perdidas de posesión a través de fallos en el control del balón o regates fallidos
Aerial Win%: Porcentaje de duelos aéreos ganados
PAdj Pressures: Presiones ajustadas en función de la posesión
Fouls: Faltas
Tack/Dribbled Past%: La proporción de entradas exitosas a ocasiones en que el oponente le/la regateó
Defensive Action OBV: Valor agregado mediante acciones defensivas
Centrocampistas / Mediocampistas
OBV: Valor agregado en las acciones relacionadas con el balón
Deep Progressions: Incursiones en el último tercio a través de pases, regates o conducciones
Pass OBV: Valor agregado mediante pases
Open Play xG Assisted: Goles esperados asistidos en juego abierto (es decir, sin contar los que provienen de las acciones a balón parado)
Dribble & Carry OBV: Valor agregado mediante regates y conducciones
Fouls Won: Faltas recibidas
Turnovers: Perdidas de posesión a través de fallos en el control del balón o regates fallidos
PAdj Pressures: Presiones ajustadas en función de la posesión
PAdj Tackles & Interceptions: Entradas y interceptaciones ajustadas en función de la posesión
Tack/Dribbled Past%: La proporción de entradas exitosas a ocasiones en que el oponente le/la regateó
Defensive Action OBV: Valor agregado mediante acciones defensivas
Extremos / Mediapuntas
xG: Goles esperados
Shots: Tiros
Shot OBV: Valor agregado en la ejecución de los tiros
PAdj Pressures: Presiones ajustadas en función de la posesión
Pass OBV: Valor agregado mediante pases
Open Play xG Assisted: Goles esperados asistidos en juego normal (es decir, sin contar los que provienen de las acciones a balón parado)
Dribble & Carry OBV: Valor agregado mediante regates y conducciones
Fouls Won: Faltas recibidas
Turnovers: Perdidas de posesión a través de fallos en el control del balón o regates fallidos
Touches in Box: Toques del balón dentro del área de penalti
xG/Shot: Goles esperados por tiro. Es decir, la calidad media de sus tiros
Delanteros Centros
xG: Goles esperados
Shots: Tiros
Shot OBV: Valor agregado en la ejecución de los tiros
Pass OBV: Valor agregado mediante pases
Open Play xG Assisted: Goles esperados asistidos en juego normal (es decir, sin contar los que provienen de las acciones a balón parado)
PAdj Pressures: Presiones ajustadas en función de la posesión
Aerial Wins: Duelos aéreos ganados
Turnovers: Perdidas de posesión a través de fallos en el control del balón o regates fallidos
Dribble & Carry OBV: Valor agregado mediante regates y conducciones
Touches in Box: Toques del balón dentro del área de penalti
xG/Shot: Goles esperados por tiro. Es decir, la calidad media de sus tiros
¿Quieres saber más sobre las métricas que se están generalizando en el fútbol? Nuestro curso online Introducción al Análisis de Datos en Fútbol Profesional ya está disponible. Los goles esperados (xG), táctica ofensiva y defensiva, acciones a balón parado, análisis de equipos y más... Apúntate >> https://cursos.statsbomb.com/
StatsBomb está orgullosa de anunciar su alianza con la mejor selección del mundo en el ranking FIFA masculino: La Real Federación Belga de Fútbol.
Con el acceso a StatsBomb Data, la selección absoluta de Bélgica y la Real Federación Belga de Fútbol se aseguran conocer al detalle y con la mayor precisión a cada jugador y equipo en más de 70 competiciones para preparar de la manera más eficaz la UEFA Eurocopa 2020 que se disputará en 2021.
Combinando los mejores datos de la industria con la plataforma de análisis profesional StatsBomb IQ no habrá ningún aspecto del juego sin ser analizado minuciosamente al preparar los análisis de rivales. En su camino la UEFA Euro 2020 la selección dirigida por Roberto Martínez demostró un dominio aplastante ganando los diez partidos en el grupo I. Consiguieron 40 goles a favor y sólo concedieron 3 en contra. Con estrellas de la talla de Kevin De Bruyne, Eden Hazrd o Romelu Lukaku la selección belga se presenta como una de las favoritas al torneo que se disputará en 2021.
Yannick Euvrard, Senior Performance and Data Analyst, RBFA
“Estamos muy contentos de trabajar con StatsBomb. Nos proporciona acceso a datos específicos que nos permiten comprender y analizar aspectos para nuestra selección nacional en la preparación para la UEFA Nations League, la fase clasificatoria del Mundial y la Eurocopa del próximo verano."
Ted Knutson, CEO, StatsBomb
"En StatsBomb estamos entusiasmados de trabajar con la selección número uno del mundo, proporcionando los mejores datos avanzados y herramientas de análisis de vanguardia. Esperamos verles pronto de vuelta en los estadios y deseamos la mejor de las suertes para el equipo en la Euro 2020."
StatsBomb proporciona datos avanzados y servicios a un gran número de organizaciones en diferentes mercados e industrias. Ofrecemos:
Productos diseñados para clubes, federaciones, agencias de representación, medios e inversores.
Los datos de evento líderes en la industria.
Compromiso de innovación y desarrollo continuo.
Excelencia en los servicios y un nivel de retención de clientes que lo atestigua.
Este artículo está escrito por el equipo de CV de StatsBomb. Vamos a abordar los detalles técnicos del algoritmo de calibración de cámara que hemos desarrollado para recoger la ubicación de jugadores directamente a partir de las imágenes de televisión.
Introducción
La calibración de la cámara es una de las etapas fundamentales en numerosas aplicaciones de visión por ordenador dentro del campo del análisis cuantitativo en el deporte. Mediante la determinación de la posición y orientación de la cámara (en adelante, pose de la cámara), es posible localizar de manera precisa la ubicación de jugadores y/o eventos en cualquier instante del partido. Además, aumentar la precisión de dicha calibración implica indirectamente un incremento adicional en la precisión a la hora de calcular métricas avanzadas a partir de los datos recogidos.
Una de las aplicaciones donde la calibración de la cámara juega un papel fundamental es el seguimiento espacio-temporal de los jugadores, también conocido como tracking. Para tratar de resolver este problema, diversas empresas han optado por la utilización de un sistema multi-cámara que permite grabar simultáneamente todas las zonas del campo desde distintas localizaciones. Gracias a la redundancia ofrecida por la disponibilidad de varias cámaras, este enfoque proporciona una gran precisión espacial, pero se ve afectado por varios inconvenientes inherentes al modelo. En primer lugar, el despliegue y mantenimiento de dicho sistema conlleva un coste muy elevado. En segundo lugar, y probablemente más importante, la aplicabilidad de esta solución se ve limitada a estadios donde dicho sistema haya sido instalado, requiriendo por tanto de acuerdos específicos con los clubes o ligas.
Una alternativa más escalable consiste en la recogida de datos directamente a partir de las imágenes de televisión, cuya accesibilidad es mucho mayor. No obstante, desde el punto de vista técnico, la complejidad se incrementa notablemente debido a varios factores. Los operadores de televisión disponen de múltiples cámaras distribuidas en diferentes posiciones, pero la realización sólo ofrece la señal proveniente de una de ellas, produciéndose cambios de cámara a criterio del realizador. Asimismo, las cámaras utilizadas no son cámaras estáticas, sino que varían su posición, orientación y zoom, lo que explica la necesidad de llevar a cabo una calibración para determinar qué parte del terreno de juego estamos observando.
A lo largo del presente documento explicaremos cómo StatsBomb está enfocando el problema de la calibración de la cámara a partir de las imágenes de televisión. Describiremos la metodología que hemos seguido e ilustraremos gráficamente los resultados que hemos obtenido con ella.
Preparación de los datos
Nuestro propósito es automatizar completamente el proceso de calibración de la cámara. Para tal fin, hemos desarrollado un sistema de adquisición de datos que nos permite recopilar imágenes tomadas con distintas poses de cámara acompañadas de la calibración correcta para cada una de ellas. El objetivo es adquirir un espectro de poses de cámara tan amplio como sea posible de manera que podamos entrenar nuestros modelos para automatizar el proceso de calibración. Este proceso se ha desarrollado en las etapas descritas a continuación:
(1). Mechanical Turk
De cara a adquirir los citados datos para entrenar nuestros modelos, hemos creado una plataforma (denominada Mechanical Turk) que permite a nuestro departamento de recogida delinear manualmente las líneas de cal. Habitualmente, la calibración de la cámara se basa en la disposición de puntos emparejados entre las imágenes. Por ejemplo, el punto de penalti o o las esquinas del área podrían ser puntos fácilmente reconocibles. Sin embargo, en función de la orientación de la cámara, es posible que no haya suficientes puntos presentes en la imagen para recuperar la pose de la cámara. Para superar esta limitación, hemos desarrollado un algoritmo que es capaz de calibrar la cámara utilizando todas las formas geométricas a nuestra disposición: puntos, líneas y círculos. De esta manera, nuestra plataforma permite etiquetar manualmente todas las líneas de cal presentes en la imagen.
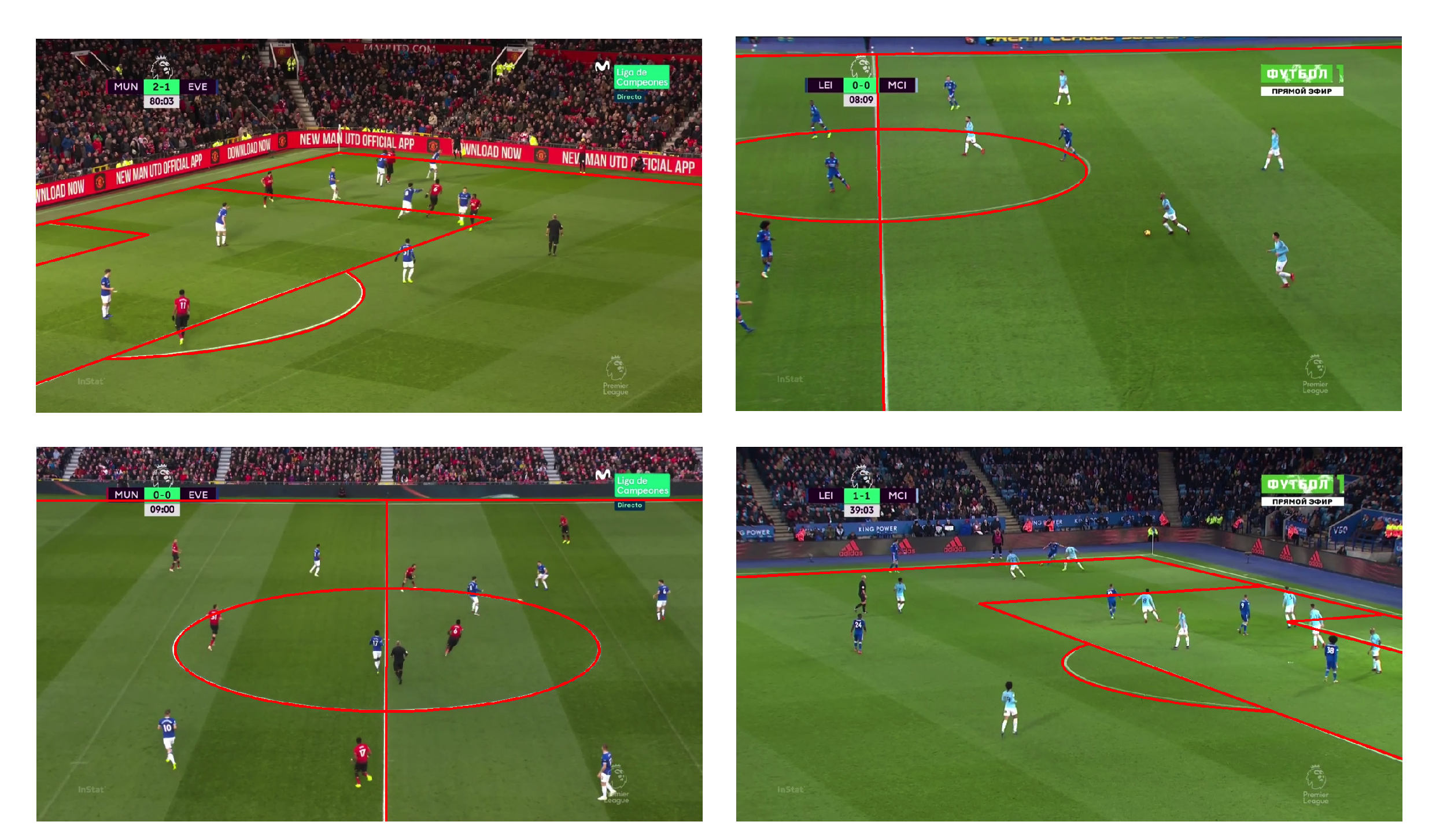
Figure 1. Ejemplo de cuatro tomas de televisión distintas cubriendo diferentes partes del terreno de juego. La información recogida por nuestro equipo de recogida (líneas, puntos y círculos) se muestra en color rojo. Pueden apreciarse mínimas imprecisiones que serán corregidas en la siguiente etapa de nuestro procesado, garantizando así la mayor precisión en nuestros datos.
(2). Estimación de la homografía a partir de datos manuales
En geometría proyectiva, se define una homografía como una transformación entre dos imágenes de la misma superficie [1]. Asumiendo que las cámaras utilizadas para la retransmisión por televisión se ajustan al modelo de cámara estenopeica, determinar la pose de la cámara es equivalente a obtener la homografía entre el terreno de juego observado en la toma y una plantilla del mismo con las dimensiones correctas. Matemáticamente, la homografía queda descrita por una matriz 3x3:
Afortunadamente, aunque esta matriz consta de 9 componentes, queda completamente caracterizada por 8 grados de libertad, que pueden reducirse incluso más bajo ciertas asunciones. Como ya hemos mencionado antes, se ha desarrollado un algoritmo para determinar la homografía a partir de los datos recogidos durante la etapa de adquisición, haciendo uso así de toda la información geométrica disponible: líneas, puntos y círculos.
Figure 2. Ejemplo de cuatro tomas de televisión distintas cubriendo diferentes partes del terreno de juego. La proyección de la plantilla del campo utilizando la homografía estimada se muestra en rojo. Conviene remarcar que aunque estas imágenes puedan parecer idénticas a las de la Figura 1, las aquí presentadas han sido obtenidas a partir de un postprocesado que es capaz de determinar la posición y orientación de la cámara con respecto al terreno de juego. En cambio, las observadas en la anterior figura muestran simplemente las líneas delineadas por nuestros recolectores. Asimismo, cabe resaltar que las imperfecciones antes mencionadas han sido eliminadas tras esta etapa.
Calibración de la Cámara
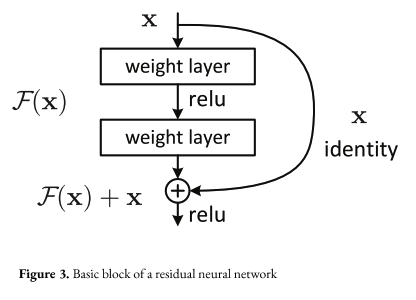
A partir de los datos adquiridos, hemos entrenado diversos modelos mediante aprendizaje supervisado. De esta forma se ha automatizado completamente el proceso de calibración de la cámara a partir de una determinada imagen. Nuestros modelos se cimentan sobre la arquitectura ResNet (2), una de las más empleadas en el estado del arte para el reconocimiento de objetos en imágenes. Una vez definida nuestra arquitectura de red, los parámetros que la caracterizan han sido estimados mediante la retropropagación de los gradientes a través del algoritmo de optimización Adam (3).
Figure 4. Ilustración del algoritmo de calibración de cámara desarrollado en StatsBomb. Se muestra en rojo la plantilla del campo proyectada utilizando la pose de cámara estimada a partir de la imagen.
Conclusiones
Hasta ahora nuestro modelo ha sido desplegado únicamente para disparos a puerta. Nos hemos centrado en estas acciones con el objetivo de incrementar la calidad de los datos utilizados en nuestro modelo de goles esperados (xG). Mediante una localización más precisa del rematador y el portero, así como de los defensores y atacantes, podemos afirmar que seguimos disponiendo de los mejores datos del sector. A comienzos de la próxima temporada habremos desarrollado un modelo para calibrar de manera completamente automática la pose de la cámara para cualquier tipo de evento. Cabe destacar que este avance permitiría disponer de datos espaciales para todo tipo de eventos, así como para tracking. Más importante aún, en StatsBomb estamos a disposición de las necesidades de nuestros clientes, ¡así que toda sugerencia o petición será bienvenida!
Referencias
(1) Hartley and Zisserman, “Multiple View Geometry in Computer Vision”, 2003, Cambridge.
¿Quieres aprender cómo organizar y utilizar datos de fútbol? Aquí está una introducción de cómo trabajar con los datos gratuitos de Hudl Statsbomb en R.
En Hudl Statsbomb tenemos el compromiso de liberar parte de nuestros datos para fomentar activamente la investigación y análisis original a todos los niveles. Para tal fin, hemos puesto a disposición del público nuestros datos de varias competiciones.
Esperamos que esta introducción os sirva para iniciaros en el uso de datos para analizar el fútbol.
Los datos accesibles de manera gratuita cuentan con las mismas especificaciones que hacen a nuestros datos ser los líderes de la industria e incluyen un nivel de detalle y precisión mayor que en cualquier otro proveedor de datos.
Nuestro feed de datos incluye, entre otros, los siguientes aspectos:
La posición de los jugadores atacantes y defensores en todas las situaciones de remate incluyendo la posición y las acciones del portero durante el desarrollo de la misma.
Información detallada sobre todos los jugadores que ejercen presión sobre el jugador con balón durante la fase defensiva – incluyendo la duración de la presión, la dirección y las acciones subsiguientes.
Pie con el que realiza los pases cada jugador, altura del pase, y muchas otras variables que otorgan mayor detalle a nuestros datos.
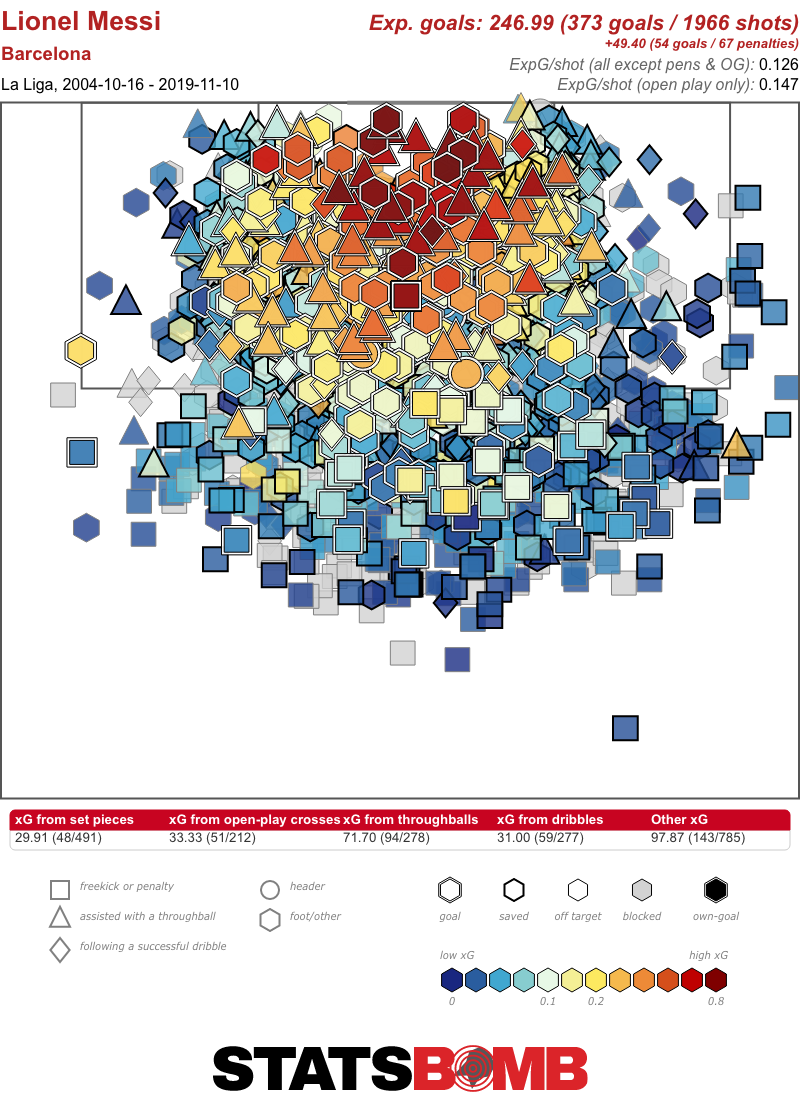
Hemos publicado una gran variedad de conjuntos de datos gratuitos, incluyendo la carrera de liga completa de Lionel Messi en el Barcelona, el PSG y el Inter de Miami, las últimas Copas Mundiales y Eurocopas tanto masculinas como femeninas o la temporada invicta del Bayer Leverkusen de Xabi Alonso.
R es un lenguaje de programación especialmente útil para el manejo de datasets estadistícas. En el ámbito que nos ocupa (estadística avanzada en fútbol) nos permite procesar datasets para diferentes fines tales como la creación de métricas así como visualizaciones de los mismos.
En Hudl Statsbomb trabajamos regularmente con R en nuestro día a día, particularmente en el departamento de análisis. Empezar a trabajar con hojas de cálculo puede ser una posibilidad válida al comienzo, pero a medida que las dataset son más grandes se vuelven más difíciles de manejar haciendo casi imposible realizar un análisis detallado de los mismos sin manejar un lenguaje de programación.
Una vez superada la curva de aprendizaje, R es ideal para trabajar y analizar los datos de manera eficiente y sencilla.
Antes de empezar, es recomendable tener instalado la versión más actualizada de R, al menos la versión 3.6.2.
RStudio
La versión básica de R no es lo más visual del mundo. Esto ha llevado a la creación de varios entornos de desarrollo integrados (IDEs). Estos wrappers son softwares desarrollados a partir de la versión inicial y tratan de hacer la mayoría de tareas dentro de R más sencillas y manejables para el usuario.
Es recomendable instalar RStudio u otro IDE similar para que el proceso de trabajo con los datos de Hudl Statsbomb más simple y limpio.
Abrir un Proyecto Nuevo en R
Esto es lo que verá el usuario al cargar por primera vez RStudio (sin las anotaciones).
En caso de no tener clara la función de cada opción o sección de RStudio es recomendable echar un vistazo a alguna de las hojas de consejos y tutoriales relativos en:
Es muy fácil encontrar una gran cantidad de recursos con explicaciones y respuestas detalladas a cualquier pregunta que pueda surgir respecto a R.
¿Qué es un Paquete de R?
Los paquetes son conjuntos de funciones que simplifican tareas. Se pueden descargar fácilmente. Para instalar un paquete en R simplemente hay que ejecutar install.packages("NombreDelPaquete").
Los paquetes que utilizaremos y que será necesario tener instalados son los siguientes:
‘tidyverse’: tidyverse contiene dentro de sí un conjunto paquetes útiles para manipular datos (por ejemplo dplyr y magrittr). install.packages("tidyverse")
‘devtools’: La mayoría de paquetes se encuentran en CRAN. Sin embargo, también se pueden encontrar muchos paquete útiles en Github. Devtools permite descargar los paquetes directamente desde Github. install.packages("devtools")
‘ggplot2’: El paquete más popular para llevar a cabo la visualización de datos en R
‘StatsbombR’: El paquete propio de Hudl Statsbomb para analizar nuestros datos
Una vez que un paquete está instalado se puede cargar ejecutando library(NombreDelPaquete). Deben importarse antes del comienzo de una sesión.
¿Qué es ‘StatsbombR’?
StatsbombR es un paquete dedicado a hacer uso de los datos de Hudl Statsbomb de manera más sencilla e intuitiva. Se puede descargar en este enlace de Github donde se incluye además información sobre su uso: https://github.com/statsbomb/StatsbombR
Para instalar el paquete en R es necesario instalar primero un par de paquetes diferentes ejecutando las siguientes líneas:
install.packages("devtools")
install.packages("remotes")
remotes::install_version("SDMTools", "1.1-221")
Para instalar StatsbombR ejecuta a continuación:
devtools::install_github("statsbomb/StatsBombR")
Información Adicional Sobre los Paquetes
Para encontrar más información sobre las diferentes funciones dentro de un paquete sólo hay que hacer click en el nombre del paquete como se ve en la imagen.
Esto nos mostrará la información del paquete incluyendo los detalles de sus funciones.
Importar los datos de Hudl Statsbomb
Para manejar nuestros datos en R es necesario familiarizarse antes con varias funciones importantes dentro de StatsbombR.
FreeCompetitions() – Muestra todas las competiciones disponibles en los datos gratuitos. Almacenar el output de esta o cualquier otra función en lugar de tenerlo en la consola de R es posible hacerlo ejecutando lo siguiente:
Comp <- FreeCompetitions(). Así, al ejecutar Comp (o cualquier palabra utilizada para tal caso) dará el output de FreeCompetitions()
Matches <- FreeMatches(Comp) - Muestra todos los partidos disponibles dentro de las competiciones seleccionadas.
StatsBombData <- free_allevents(MatchesDF = Matches, Parallel = T) – Importar todos los datos de evento para los partidos seleccionados.
A continuación vamos a ver un ejemplo de cómo importar datos en R. Primero, abrimos un nuevo script para tener el código accesible de la siguiente manera File -> New File -> R Script. Se puede guardar en cualquier momento.
1: tidyverse importa varios paquetes diferentes. Los más importantes para esta tarea son dplyr y magrittr. StatsbombR importa StatsbombR.
2: Importa las competiciones disponibles para el usuario y se filtran utilizando la función ‘filter’ de dplyr para obtener la temporada 05/06 de La Liga en este caso.
3: Importa todos los partidos de la competición seleccionada.
4: En este punto se ha creado una ‘dataframe’ (esencialmente una tabla u hoja de datos) llamada StatsBombData (o el nombre elegido para tal caso) con todos los datos de evento gratuitos para la temporada 05/06 de la Liga.
5: Extrae toda la información relevante previamente descrita.
Trabajar con los datos
En nuestro Github (el mismo lugar donde se pueden encontrar los datos) se pueden encontrar documentos adicionales con las especificaciones de Hudl Statsbomb Data. Estos están disponibles para ver o descargar y contienen explicaciones a las dudas que puedan surgir sobre los distintos tipos de eventos o cuestiones similares.
Una vez que tenemos disponible el archivo StatsBombData vamos a ver varios modos en los que se puede utilizar al mismo tiempo que nos familiarizamos con R. Los ejemplos irán incrementando en grado de dificultad.
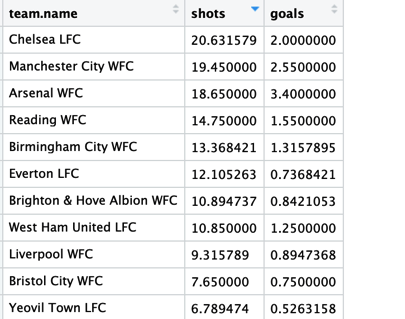
Ejemplo 1: Tiros y Goles
Un punto de partida simple pero fundamental. Veremos cómo extraer los números de tiros y goles de cada equipo, primero los totales y luego los de cada partido.
Primero, vamos a importar los datos para la temporada 2018-19 de la FA Women’s Super League. Utilizamos de nuevo el código citado arriba, pero esta vez la competition_id será 42 y la season_id será "2018/2019".
1: Este código agrupa los datos por equipo, de tal forma que cualquier operación que realicemos en ellos será ejecutada por cada equipo. I.e. extraerá los tiros y goles para cada equipo de manera individual.
2: Summarise toma cualquier operación ejecutada y genera una tabla nueva y separada con ello. La mayoría de usos de summarise suelen ser después de group_by.
shots = sum(type.name=="Shot", na.rm = TRUE) crea una nueva columna llamada ‘shots’ que suma todas las filas bajo la columna ‘type.name’ que contienen la palabra ‘Shot’.
na.rm = TRUE pide ignorar cualquier NA dentro de esa columna.
shot.outcome.name=="Goal", na.rm = TRUE) hace lo mismo con los goles.
En este punto deberíamos tener una tabla como esta.
Para realizar el mismo cálculo por partido en lugar de los totales solo tenemos que cambiarlo de la siguiente manera:
1: Aquí estamos diciendo a ggplot qué datos estamos utilizando y qué queremos en los ejes x/y del gráfico. ‘Reorder’ ordena los nombres de los equipos en función de los tiros.
2: Pide a ggplot formatearlo como un gráfico de barras.
3 : Cambia el nombre del eje de tiros.
4 : Elimina el título del eje.
5 : Aquí podemos reducir el espacio entre las barras y el límite del gráfico.
6 : Rota el gráfico completo colocando las barras en sentido horizontal.
Lo anterior debería generar un gráfico como este.
El diseño obtenido es básico y diáfano. Puede ser modificado de diferentes maneras para conseguir un visual más atractivo.
Cualquier elemento de un gráfico ggplot desde el texto a los datos en sí puede ser modificado de numerosas maneras abriendo la puerta a la creatividad del usuario.
Extraer los tiros para jugadores es relativamente sencillo una vez que sabemos hacerlo para equipos. ¿Pero cómo podemos ajustar los números por cada 90 minutos?
1: Similar al cálculo para los equipos. Incluimos aquí ‘player.id’ ya que será importante después.
2: Esta función obtiene los minutos de cada jugador en cada partido en la muestra.
3: Agrupamos lo anterior sumando los minutos en cada partido para obtener el total de minutos disputados por cada jugador.
4 : left_join combina las tablas de tiros y de minutos con el player.id actuando como punto de referencia.
5: mutate es una función dplyt que crea una nueva columna. En este caso estamos creando una columna que divide los minutos totales entre 90 dando como resultado el número de 90s del jugador en la temporada.
6 : Finalmente dividimos los tiros totales entre el número de 90s para obtener la columna de tiros cada 90 minutos (shots per 90).
En este punto tendremos los tiros cada 90 minutos para todas las jugadoras de la WSL.
A continuación, se puede filtrar la tabla eliminando a las jugadores con insuficiente muestra mediante la función ‘filter’ (dplyr).
El mismo proceso puede ser aplicado a todo tipo de eventos: diferentes tipos de pases, acciones defensivas, etc.
Ejemplo 4: Representar Pases Gráficamente
Filtar los datos extrayendo un subconjunto de datos y visualizarlos sobre un campo empleando para ello ggplot2.
Finalmente, vamos a trazar los pases de un jugador en el campo. Para esto necesitaremos en primer lugar una visualización de un campo de fútbol. Es posible crear uno propio una vez estemos familiarizados con ggplot que pueda ser utilizado además para diferentes propósitos. Más adelante veremos opciones para ello. De momento, hay opciones ya formateadas que podemos utilizar.
La que utilizaremos aquí es cortesía de FC rStats. Este usuario de Twitter ha creado varios paquetes públicos de R para analizar datos de fútbol. El paquete que nos ocupa se llama ‘SBPitch’ y sirve exactamente para eso. En ‘Paquetes Adicionales’ veremos otras alternativas para crear campos de juego.
Para instalar SBPitch ejecutamos:
devtools::install_github("FCrSTATS/SBpitch")
Vamos a representar los pases completados por Messi dentro del área en la Liga 05/06. Trazar todos los pases sería farragoso y poco útil por tanto elegimos un subconjunto. Es importante asegurarse de utilizar las funciones explicadas anteriormente para importar los datos.
1: Filtrar los pases de Messi. is.na(pass.outcome.name) filtrar solo los pases completados.
2: Filtrar los pases dentro del área. Las coordenadas del campo se pueden encontrar en nuestro event spec.
3: Obtenemos una flecha desde un punto de origen (location.x/y inicio del pase) a un punto final (pass.end_location.x/y, final del pase). Lineend, size y length son las opciones de customización disponibles aquí.
4: Crea un título y subtítulo para el gráfico. Entre otras opciones se puede añadir una leyenda usando caption =.
5: Ajusta el gráfico a la relación de aspecto elegida para que no quede estirado o poco estético. El resultado será un gráfico tal que así. De nuevo, esta es una versión básica a partir de la cual se pueden implementar todo tipo de mejoras visuales.
La opción theme() permite cambiar el tamaño, posición, fuente y otros aspectos de los títulos así como otros apartados estéticos del gráfico.
Es posible añadir colour= a geom_segment() para colorear los las flechas de cada pase del modo escogido.
En el siguiente enlace se pueden encontrar diferentes posibilidades disponibles para customizar los gráficos: https://www.rstudio.com/resources/cheatsheets/
Funciones útiles en StatsbombR
Existen docenas de funciones dentro de StatsbombR para realizar diferentes tareas. Se puede consultar la lista completa aquí. No todas las funciones están disponibles en los datos gratuitos. Algunas solo son accesibles para nuestros clientes (vía API). Una pequeña muestra de las más útiles:
get.playerfootedness() – Devuelve la pierna hábil (preferida) de un jugador a partir de nuestros datos de pases (incluyen la pierna con la que se realiza el pase).
get.opposingteam() – Devuelve una columna opuesta para cada equipo en cada partido.
get.gamestate() – Devuelve la información de cuánto tiempo acumula cada equipo en cada uno de los posibles Game States (ganando/empatando/perdiendo).
annotate_pitchSB() – Nuestra solución para trazar un campo de juego en ggplot.
Paquetes adicionales
La comunidad ha desarrollado múltiples paquetes para R. Es probable que cualquier cuestión o tarea que se quiera llevar a cabo en R tenga desarrollado un paquete específico para ella. Nombrar todos sería imposible pero aquí va una pequeña selección de algunos que son relevantes para trabajar con nuestros datos:
Ben Torvaney, ggsoccer - Alternativa para trazar campos de juego con los datos de Hudl Statsbomb.
Joe Gallagher, soccermatics – Otra alternativa para dibujar campos de juego incluyendo además atajos sencillos para crear mapas de calor entre otras funciones.
ggrepel – Solución para problemas de texto superpuesto en las gráficas.
gganimate – Opción sencilla para crear gráficos animados con ggplot en R.
Continuamos con la serie de artículos en los que tratamos de explicar las nociones básicas del análisis de datos en el fútbol. Históricamente la mayoría de la investigación en este área ha sido en inglés, pero queremos contribuir a cambiar eso. Esto pretende ser un manual básico para entender las métricas que se están generalizando en el fútbol y previsiblemente serán parte del vocabulario estándar en pocos años.
Sabemos que hay partes del juego y posiciones que son más difíciles de analizar desde un enfoque cuantitativo que otras. Históricamente, los aspectos defensivos han sido uno de los más complicados.
Este no es un problema exclusivo del fútbol, sino que ha sido recurrente en deportes con mayor nivel de desarrollo analítico como el baseball o el baloncesto.
Incluso en la famosa gesta de los Oakland A’s contada en Moneyball, Billy Bean y Paul De Podesta se centraron específicamente en la parte ofensiva. El desarrollo y análisis de la parte defensiva es algo que no se ha ido corrigiendo en general hasta mucho más recientemente.
¿Por qué la defensa es difícil?
Hay varias razones que explican por qué es tan difícil entender la defensa en fútbol.
Conceptualmente, hay una diferencia fundamental entre el ataque y la defensa: Mientras que en ataque, de un modo u otro, el rendimiento exitoso acaba traduciéndose en realizar una acción (rematar, completar un regate, meter gol etc.) y hacerlo más veces suele ser mejor, en defensa no siempre sucede lo mismo. No en vano, el objetivo es evitar que el equipo rival haga algo, y por tanto muchas veces lo que no se hace es tan importante o más que lo que sí se hace. Paradójicamente, en defensa menos puede ser mejor.
Por ejemplo, un posicionamiento adecuado o un pressing coordinado de manera eficaz limitan las opciones del rival y por tanto es menos probable que los jugadores más retrasados tengan que defender de manera activa frecuentemente.
Como ejemplo opuesto, si un portero tiene que intervenir muchas veces durante un partido para evitar que su equipo reciba gol, parece evidente que hay algún problema en la manera de defender de ese equipo más allá de las estadísticas individuales del meta.
Un defensa que realice más entradas o interceptaciones no es necesariamente mejor que uno que realice menos, estos datos miden en mayor medida la oportunidad que la habilidad. En las acciones que se realizan en defensa hay mucho más ruido que señal. ¿Cómo podemos empezar a disipar ese ruido?
La segunda razón, relacionada con lo anterior, tiene que ver con los datos que había disponibles hasta hace poco. Durante mucho tiempo los proveedores se limitaron a contar eventos (por ejemplo, interceptaciones) sin tener en cuenta si estos eran representativos de las tareas fundamentales en defensa. Por el camino, se dejaron algunas acciones que ahora sabemos no sólo dan una imagen más realista del espectro de tareas en defensa sino que además permiten analizar en detalle algunas posiciones concretas. Explicaremos más sobre esto al hablar de los eventos de presión.
Razones adicionales que van más allá del propósito de esta introducción son, entre otras, las interacciones entre jugadores, el contexto de las acciones defensivas, el tipo de datos empleados, o efectos de equipo difíciles de controlar.
En definitiva, ni todo lo que es relevante se puede contar, ni (hasta recientemente) se ha contado todo lo que es relevante.
Métricas Defensivas: Revisión de diferentes enfoques
Para comenzar a arrojar un poco de luz, vamos a hacer una pequeña revisión de los enfoques que se han empleado en los últimos años y a mostrar algunas de las soluciones que hemos desarrollado en StatsBomb para analizar la defensa con mayor rigor. Algunas de las preguntas relevantes son las siguientes:
¿Cómo de efectivos son los equipos tratando de evitar recibir goles?
¿Qué rasgos estilísticos diferencian equipos que tratan de presionar alto respecto a los que defienden en bloques medios o bajos?
¿Cómo podemos tener una visión más representativa de la influencia de determinados jugadores en defensa más allá de recuperar la posesión directamente?
Una de las premisas de las que partimos es que en defensa hay dos objetivos: Evitar recibir goles y recuperar la posesión. Ambos están latentes en las decisiones estratégicas que toman los equipos haciendo que haya rasgos estilísticos reconocibles que permiten situar los diferentes enfoques tácticos en categorías específicas.
Métricas de equipo: Defender nuestra portería
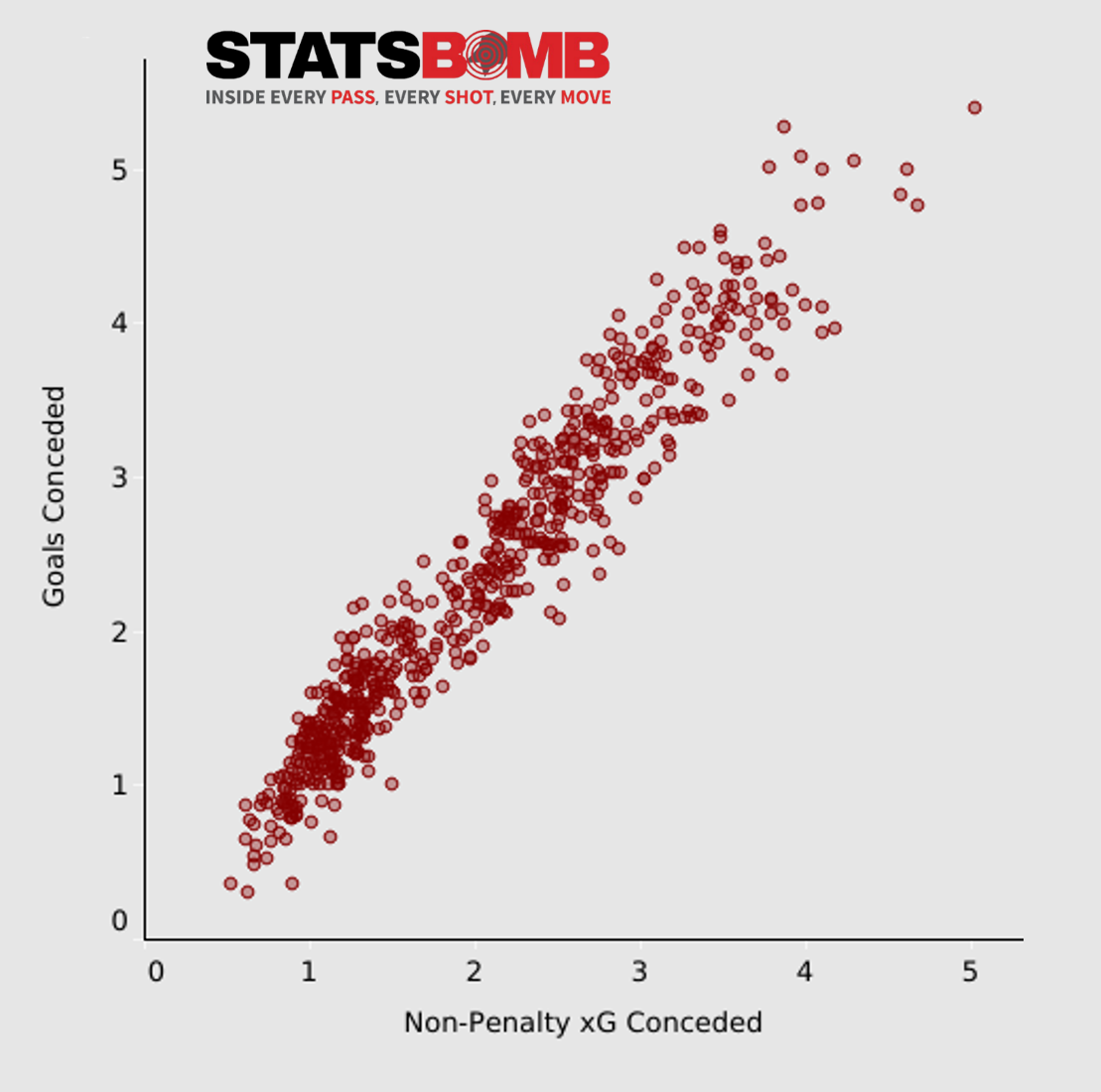
La primera tarea colectiva es evitar conceder goles restringiendo para ello la cantidad y calidad de ocasiones de las que dispone el rival. Si los Goles Esperados (xG) son una métrica útil para medir el rendimiento ofensivo, parece lógico pensar los Goles Esperados Concedidos (xGA) es una métrica que nos muestra la eficacia del equipo evitando que les generen ocasiones de valor elevado.
Un equipo al que regularmente le generan un número elevado de Goles Esperados es probable que - pese a variabilidad transitoria - acabe concediendo goles y por tanto teniendo complicado sumar puntos.
Además, podemos tratar de discernir la capacidad que tenga el equipo para conceder menos goles de los que el modelo espera (y la habilidad de los porteros evitando goles, pero este es un tema para otra ocasión). Hay equipos como el Atlético de Madrid que lo han logrado regularmente.
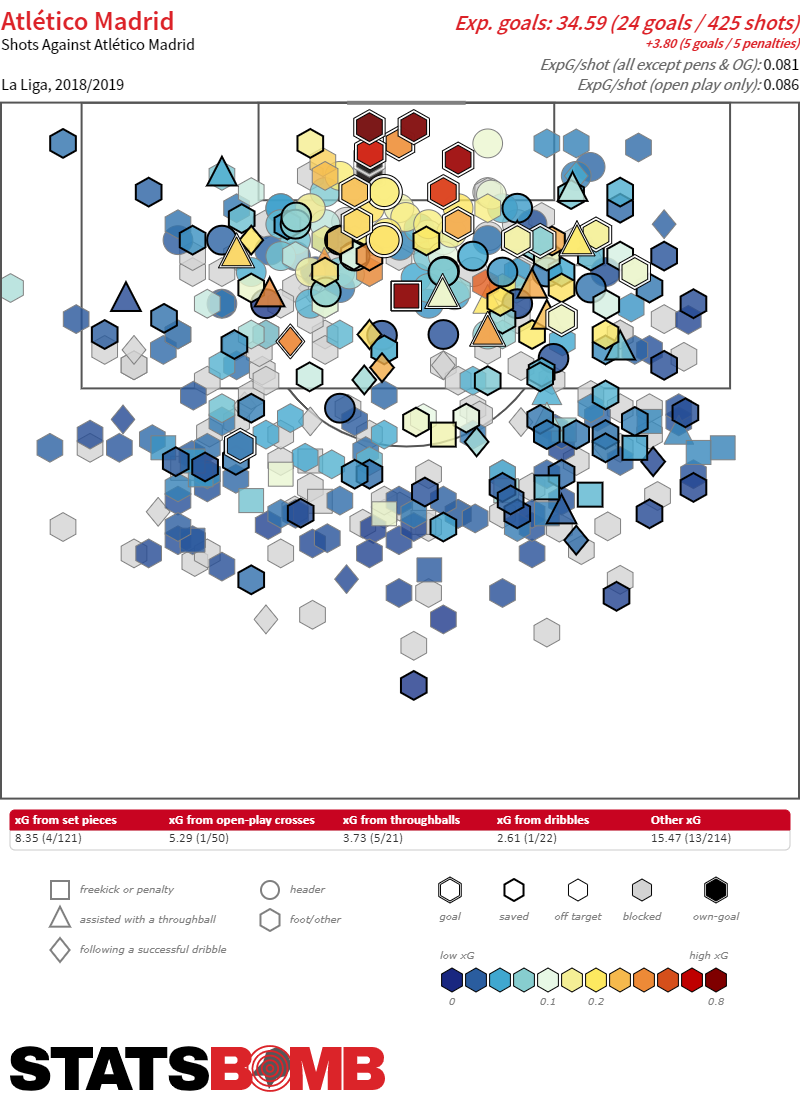
Sin embargo, no tenemos por qué detenernos en los números agregados de xG. Podemos analizar detalles sobre el volumen y aspectos concretos de los remates tales como distancia, situaciones de juego o defensores cercanos al rematador.
En este sentido, los datos de StatsBomb y por consiguiente los modelos construidos a partir de ellos proporcionan una visión más precisa del valor de las ocasiones que el equipo recibe. Podéis leer más en este artículo.
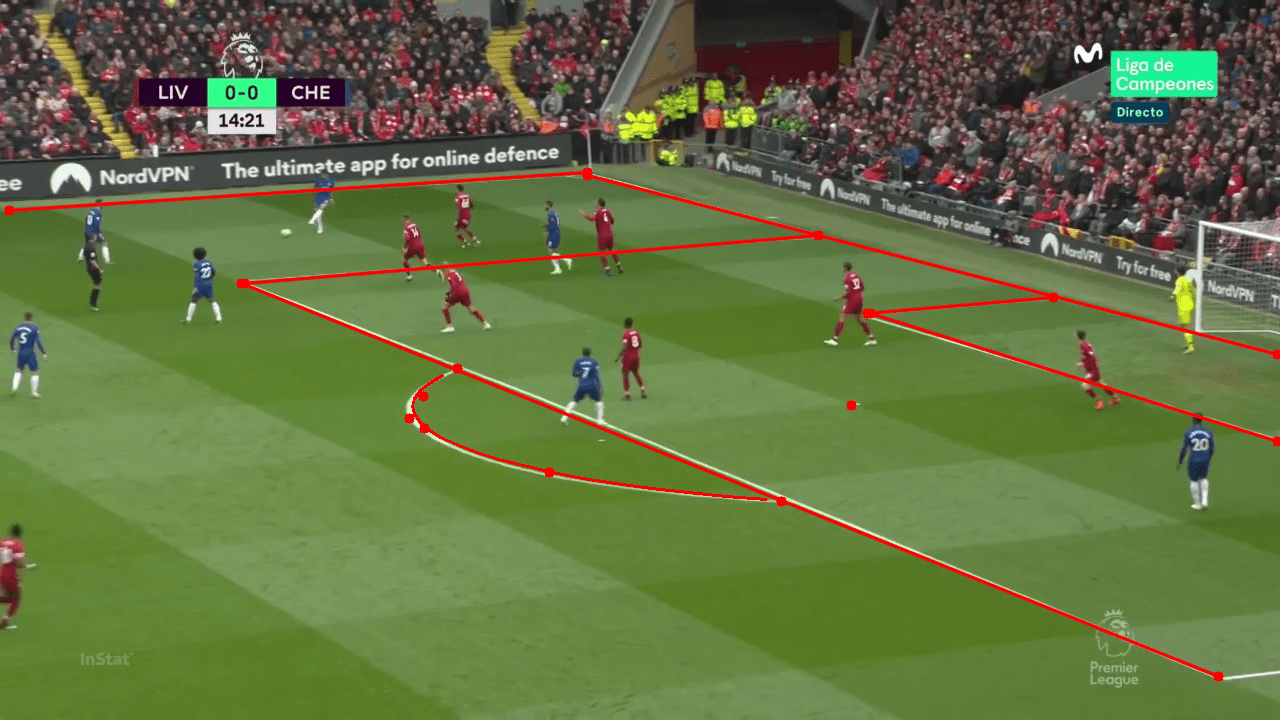
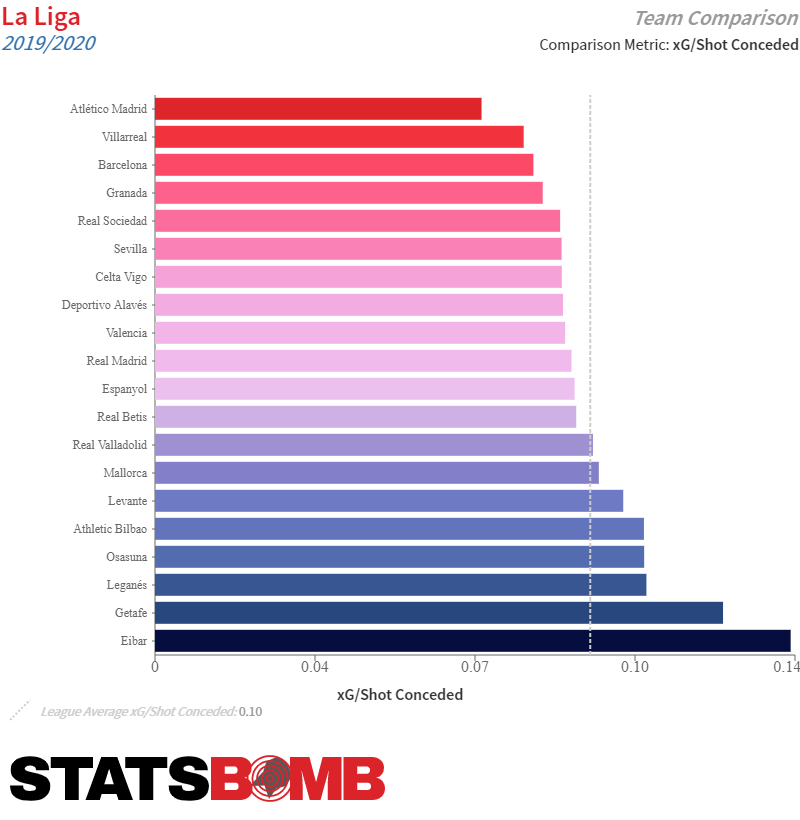
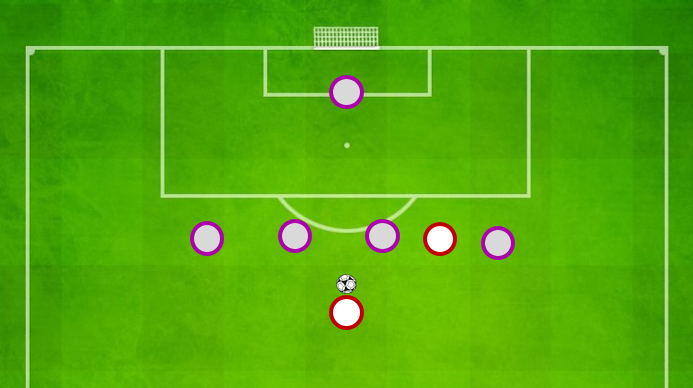
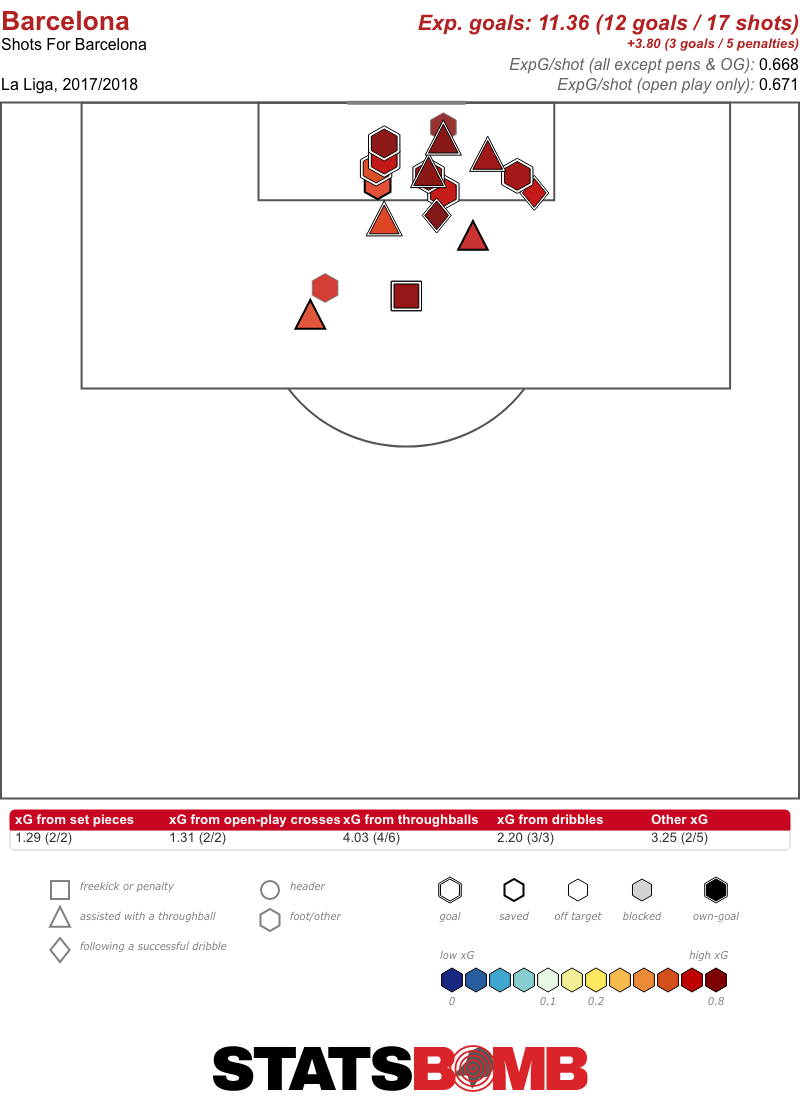
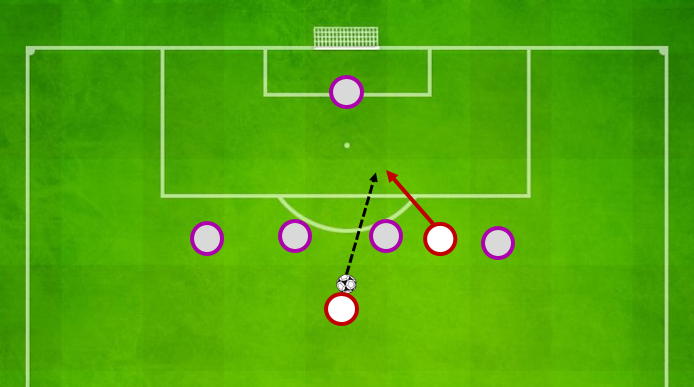
En el gráfico superior podemos ver los tiros claros concedidos (por partido) por los equipos de La Liga esta temporada. Los tiros claros (Clear Shots) son aquellos en los que no hay ningún defensor interponiéndose entre el rematador y el portero.
En el Freeze Frame inferior se puede ver un ejemplo de un Clear Shot.
También podemos analizar aspectos como los tiros bloqueados, la distancia media desde la que se remata, o la altura del remate, así como tiros precedidos por una pérdida en campo propio o tiros en situaciones de contraataque.
Además, dado que tenemos la posición de los defensas en cada remate podemos analizar al detalle cómo influye la presión de un defensor en los distintos remates. Revisaremos este tema en profundidad más adelante, pero si tenéis interés podéis leer la investigación original al respecto de Derrick Yam aquí, aquí y aquí (en inglés).
Es indudable que analizar lo que sucede en las áreas y las ocasiones de cada equipo aporta información relevante. Sin embargo, la pregunta que sigue sin quedar resuelta es qué hacen los equipos para evitar eso en primer lugar y cómo influye en la cantidad y calidad de las ocasiones.
Por ejemplo, hay equipos que prefieren presionar con una línea defensiva alta para así mantener al rival lejos de su área y limitar el número de tiros de los que dispone, sin embargo, al mismo tiempo esto hace más probable que las ocasiones de las que dispone el rival tengan un xG medio más alto (porque habitualmente serán situaciones de juego al espacio y unos contra uno).
Otros equipos prefieren defender más cerca de su propio área acumulando más jugadores en las inmediaciones, lo que limitará la calidad de las ocasiones rivales, pero al mismo tiempo tenderá a cederle la iniciativa por lo que dispondrá de mayor número de remates.
Analizar sólo el tipo o cómo evitan las ocasiones es descuidar la interrelación entre los dos objetivos anteriormente mencionados. Puesto que la defensa trata tanto de evitar conceder goles como de recuperar la pelota (para posteriormente crear ocasiones) entender las diferentes opciones tácticas para asegurar un equilibrio entre ambos y los trade-offs de diferentes enfoques ha sido una preocupación para la comunidad de analistas.
Rasgos estilísticos, control del espacio e intensidad defensiva
Las cuestiones habituales al respecto han sido cómo, cuánto y dónde realizan las acciones defensivas los equipos.
Ha habido varios enfoques al respecto, pero podemos señalar como inicial el trabajo de Colin Trainor en 2014 que llevó al desarrollo de la métrica PPDA (pases por cada acción defensiva). Esta métrica responde a una pregunta sencilla: ¿cuántos pases realiza el rival por cada acción defensiva de mi equipo?
Pases del rival / Acciones defensivas (entradas, interceptaciones, faltas, duelos)
Por tanto, a menor PPDA, mayor intensidad defensiva ejercida.
Partiendo de que el número de acciones defensivas de un equipos (originalmente entradas e interceptaciones) tienen nula correlación con el rendimiento de los equipos Colin desarrolló gradualmente una medida que era más representativa de la intensidad defensiva.
Pese a que la idea inicial era discriminar los equipos que mostraban una presión más alta, la métrica se fue desarrollando y gradualmente adaptando a diferentes zonas hasta ser una de las métricas descriptivas más empleadas para mostrar los rasgos estilísticos que definen la defensa de los equipos. En StatsBomb la utilizamos regularmente en los análisis.
Hay equipos que presionan más alto y otros que prefieren defender en bloque bajo. Poder diferenciar estos rasgos estilísticos es un primer paso para saber qué estrategia defensiva es más interesante, la influencia en las posteriores transiciones ofensivas, contextualizar los datos de un jugador individual o saber si el rendimiento del equipo con determinada estrategia tiene puntos débiles.
Otras fórmulas para medir la intensidad defensiva incluyen la altura a la que los equipos realizan acciones defensivas, las recuperaciones post-presión, entre otras.
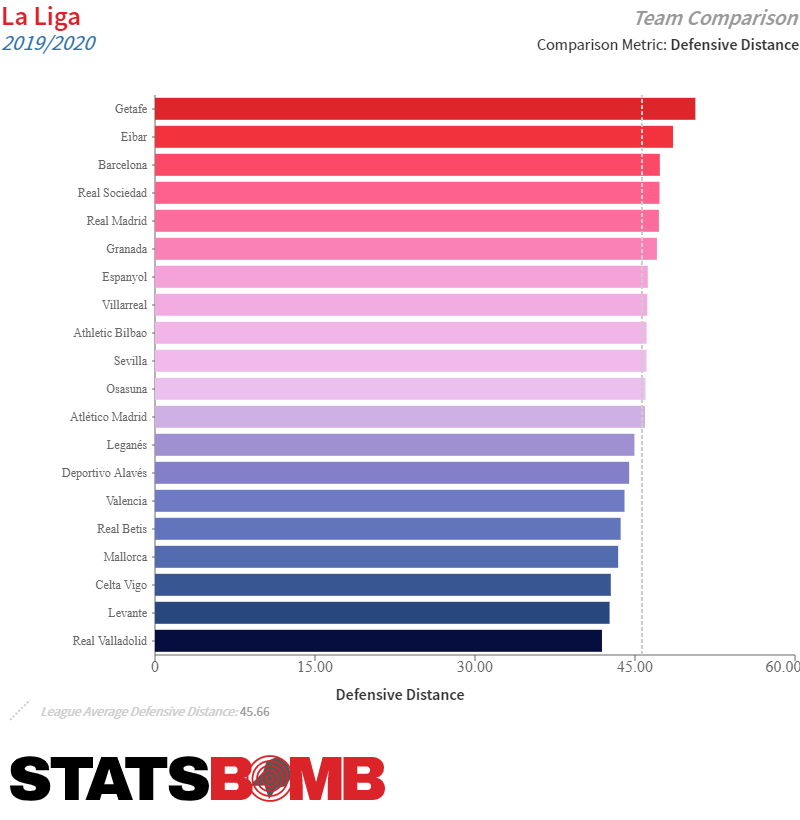
En el gráfico superior podemos ver la distancia defensiva media (respecto a su propia portería) a la que los equipos realizan las acciones defensivas en Liga. Como se puede comprobar a simple vista, y de manera poco sorprendente, el Getafe y el Eibar sobresalen en está métrica.
Sin embargo, todas estas fórmulas quedaban cojas por las razones expuestas anteriormente - principalmente porque sólo utilizan acciones defensivas realizadas sobreel balón. En StatsBomb creíamos que había mucho margen de mejora y una de las soluciones que creíamos más valiosas era recoger otros eventos relevantes.
Las presiones
Los eventos defensivos en los proveedores de datos tradiciones han sido las entradas o tackles, interceptaciones, duelos, despejes, etc. Mientras que estos datos son útiles hasta cierto punto, no llegan a dar una visión representativa del espectro completo de acciones que tienen impacto a nivel defensivo del equipo, limitando así la capacidad de extraer conclusiones relevantes.
Es aquí donde las cosas se ponen interesantes, y los datos de StatsBomb proporcionan un nuevo evento que cambia la manera de afrontar el análisis defensivo: las presiones.
¿Qué son las presiones?
Una presión es la acción de atacar al poseedor de balón o al receptor de un pase - en un radio de 5-8 metros en función de la zona del campo - sin llegar a realizar una entrada, falta o interceptar el pase (cualquiera de estas acciones puede ocurrir posteriormente, pero es un evento diferente).
Para cada evento de presión tenemos su localización, dirección, duración y resultado. En el vídeo de la presentación de los datos de StatsBomb se puede encontrar más detalle sobre la manera de recoger este evento.
La lógica subyacente es que muchas de las acciones defensivas que permiten que posteriormente un equipo recupere la posesión o lleve a cabo un pressing* eficaz no se limitan a las acciones que ocurren sobre balón, sino que hay toda una serie de acciones que llevan a ello tales como cerrar líneas de pase, acelerar la acción del jugador, dirigirle hacia determinadas zonas, forzar pases descontrolados, o hacer que el jugador en posesión se quite el balón de encima.
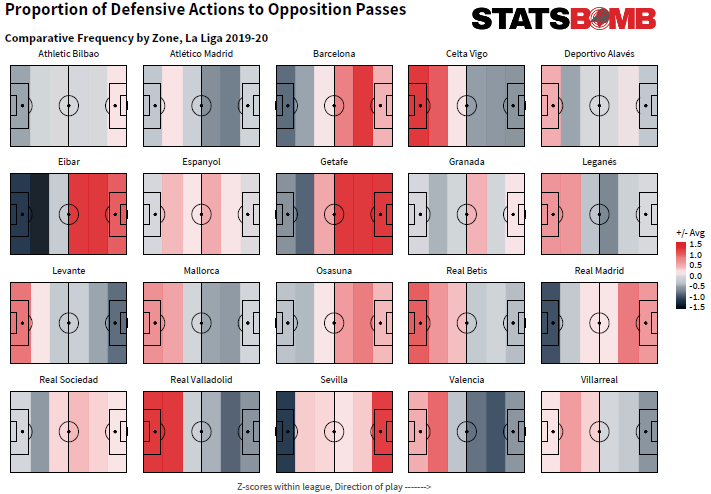
A nivel colectivo esto nos permite tener una visión más realista y completa de los mecanismos tácticos que los equipos usan en fase defensiva: En qué zonas comienzan a ejercer presión, hacia qué lado dirigen a los rivales, dónde son más fuertes, con qué frecuencia presionan en determinadas zonas del campo y qué jugadores son los más involucrados en ello.
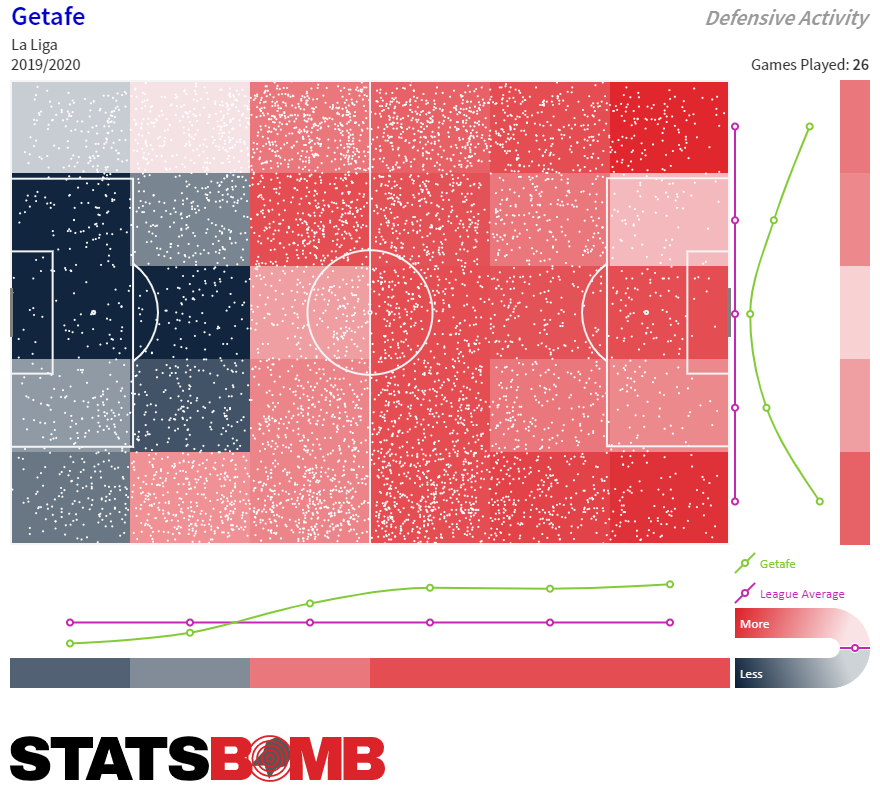
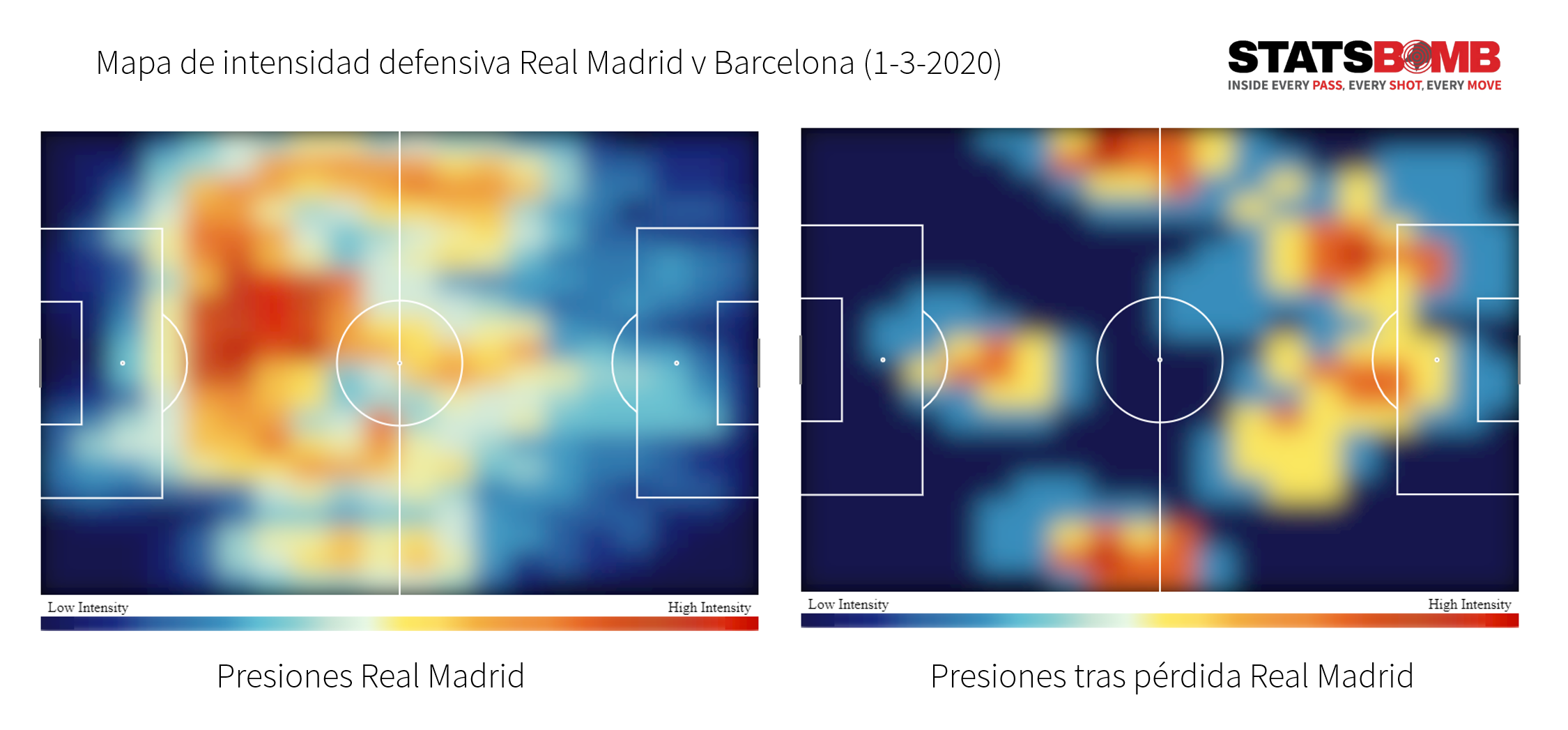
En el mapa defensivo inferior podemos ver la actividad defensiva (acciones defensivas incluyendo presiones) del Getafe respecto a la media de la Liga en cada zona. Los colores más rojos indican mayor actividad defensiva que la media, y los colores más oscuros menor. El perfil defensivo del Getafe es claro a simple vista.
Además, nos permite analizar al detalle aspectos como la presión tras pérdida, o los contraataques que se inician a partir de presiones en diferentes zonas.
En los gráficos superiores podemos ver el mapa de presiones del Real Madrid en el último Clásico. Las zonas en las que el Real Madrid realizó más presiones y las zonas en las que realizó más frecuentemente presiones tras pérdida (definido como presiones realizadas en los 5 segundos posteriores a la pérdida de balón).
A nivel individual, los datos de presión nos proporcionan una dimensión adicional para analizar el rendimiento defensivo. Este evento es especialmente relevante para los atacantes y los centrocampistas, pero por su granularidad y por la cantidad de eventos de este tipo que se dan por partido podemos emplear para analizar de manera más exhaustiva incluso los defensas.
El problema evidente que supone tratar de evaluar el rendimiento de los jugadores atacantes con las acciones como entradas o interceptaciones es que estas son por definición acciones en las que se trata de recuperar directamente la posesión. Sin embargo, como cualquiera con experiencia en fútbol puede corroborar, desde un punto de vista táctico las funciones defensivas habituales de los atacantes no son recuperar el balón.
Es decir, normalmente el delantero no presiona para recuperar la pelota por sí mismo, sino para tapar líneas de pase concretas, orientar la salida de balón del rival hacia zonas concretas (normalmente exteriores), forzar a los rivales a realizar acciones descontroladas, cometer errores, o a quitarse el balón de encima.
En definitiva, ayudar a que los compañeros tengan mayor probabilidad de recuperar la pelota posteriormente. Con los eventos de presión podemos otorgar valor a estas acciones y comenzar a analizar de manera más detallada el rendimiento de los jugadores sin balón.
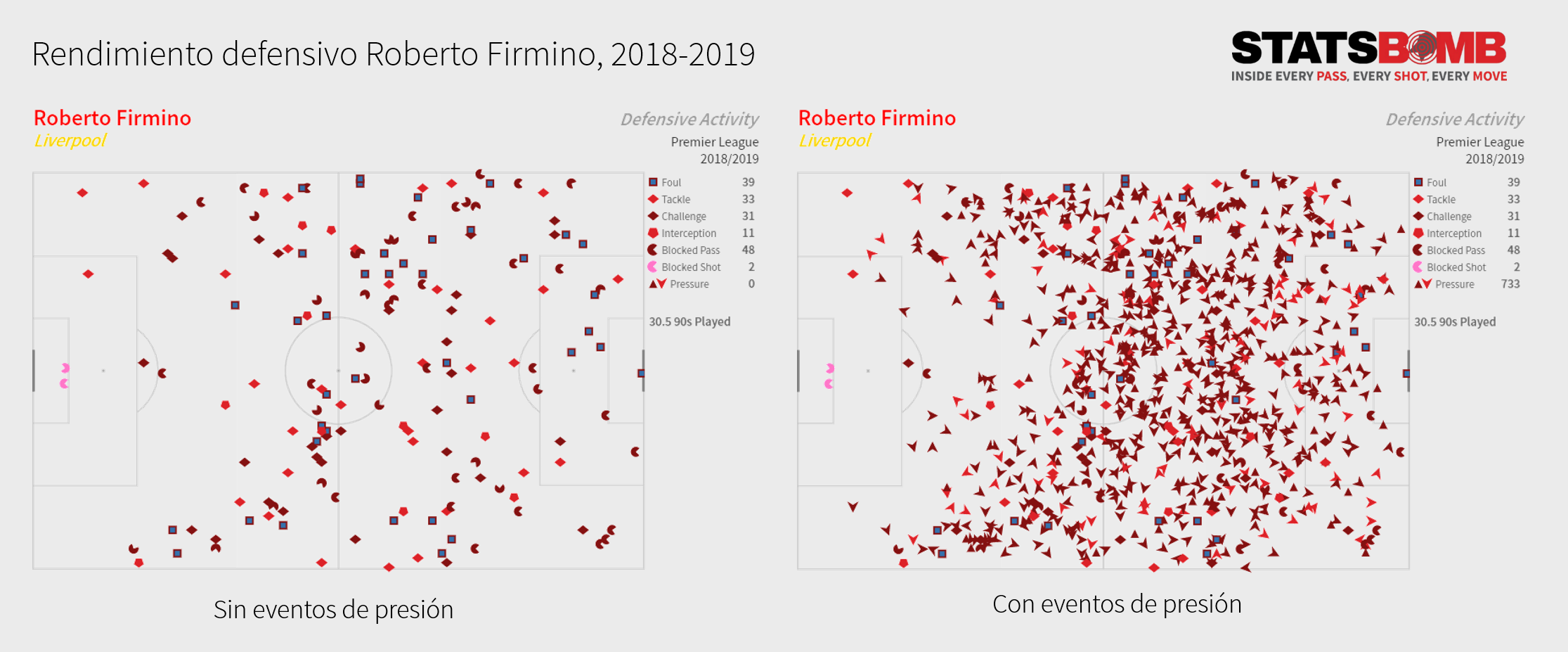
Una de las maneras es utilizando la métrica Pressure Regains o Recuperación post-presión. Si el equipo recupera la pelota en los cinco segundos posteriores a una acción de presión de un jugador, se le asignará una recuperación post-presión al jugador. Este es un proxy muy práctico de la influencia de los jugadores atacantes en las recuperaciones de su equipo.
Como todo, no está exento de limitaciones, y es que un delantero puede esforzarse muchísimo, ejercer presión con el timing apropiado pero si el resto del equipo no le acompaña o no lo hacen de manera coordinada, difícilmente será efectivo. Sin embargo, estas métricas dan una visión más representativa de la realidad que intentamos analizar.
En los gráficos inferiores podemos ver la comparativa del rendimiento defensivo de Roberto Firmino (2018-2019) excluyendo las acciones de presión (gráfico izquierdo) e incluyéndolas (gráfico derecho).
Ventajas y usos adicionales de los eventos de presión
No tenemos por qué deternos aquí, los eventos de presión abren un abánico nuevo de posibilidades y preguntas que podemos intentar responder (y que de hecho aún estamos haciendo). Entre otras cosas podemos evaluar las acciones de counterpressure (presiones en los cinco segundos posteriores a la pérdida), qué jugadores tienen mayor influencia en los momentos de transición defensiva o cómo la capacidad de presionar evoluciona a lo largo de los partidos, de las temporadas o cómo disminuye con la edad.
También podemos medir aspectos como la intensidad (o agresividad) defensiva, el número de recepciones en zonas de influencia presionadas, entre otras.
Además, los usos de estos datos no se circunscriben sólo al apartado defensivo, sino que gracias a tener los eventos de presión, al mismo tiempo, podemos saber si los jugadores en posesión del balón están siendo presionados mientras realizan una acción determinada (AUP o Actions Under Pressure). Es decir, podemos ver cómo cambian las decisiones y el grado de precisión en las acciónes de los jugadores en posesión cuando están presionados respecto a cuando no lo están. Esto no es sólo fascinante sino que tiene innumerables utilidades prácticas.
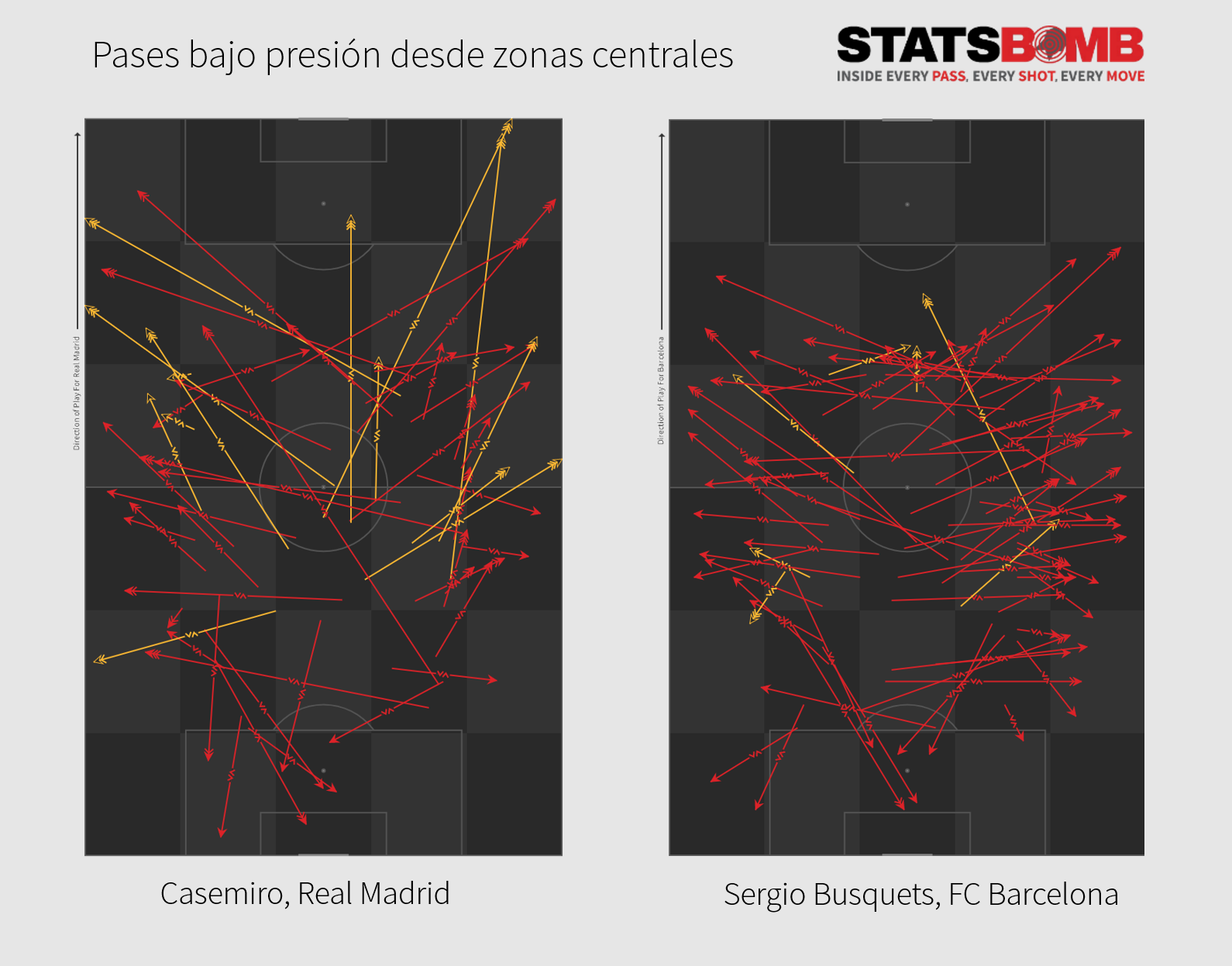
En la imagen superior podemos comparar visualmente los pases desde zonas centrales a zonas adyacentes de Casemiro y Busquets cuando están presionados. El jugador catalán tiene un volumen mayor como es esperado, así como un porcentaje de pases completados mayor (en rojo los completados) y su tendencia a distribuir en corto hacia las bandas incluso bajo presión es evidente. Por su parte el mediocentro brasileño prefiere los envíos largos y los cambios de orientación al lado opuesto.
Ajustar las métricas defensivas en función de la posesión
Para terminar, hay una pregunta recurrente que tenemos que abordar, ¿Cómo afecta el estilo de juego del equipo al output defensivo de los jugadores? ¿Qué podemos hacer para controlar esto?
Uno de los puntos más claros, es que los jugadores sólo pueden realizar acciones defensivas cuando su equipo no tiene la posesión, por tanto, en función del tiempo que el equipo esté en posesión tendrán más o menos oportunidades de sumar acciones defensivas. Esto hace que los equipos con volúmenes elevados de posesión tengan menor número de acciones defensivas y por tanto los números absolutos de tackles, interceptaciones (o presiones) tienen más ruido de lo deseable.
Por tanto, para una comparación más objetiva una de las soluciones prácticas y sencillas es ajustar en función de la posesión (esto es más difícil de lo que parece, si tenéis interés podéis leer el artículo de Ted Knutson con la metodología original aquí).
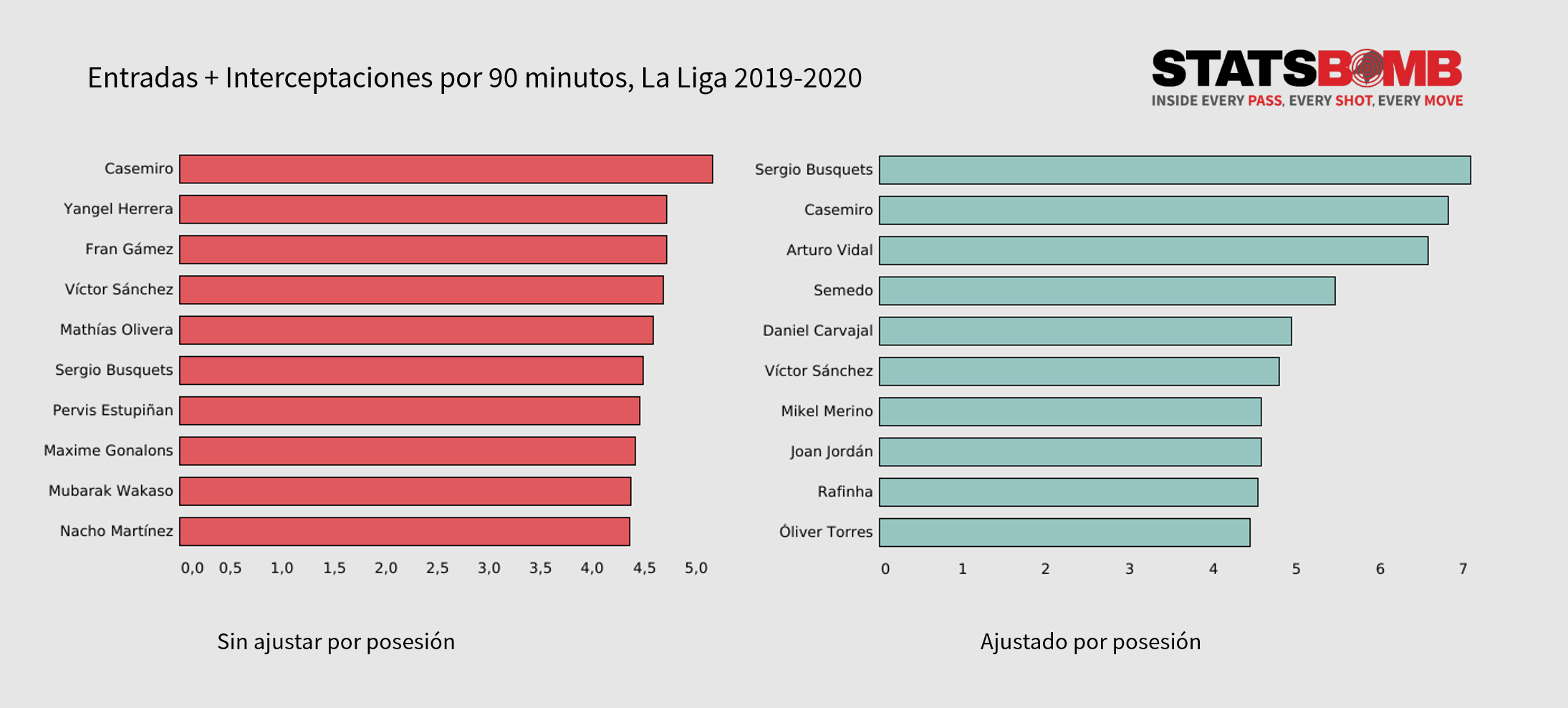
En el gráfico superior vemos los diez jugadores de La Liga esta temporada ordenados por la suma de interceptaciones y entradas (cada 90 minutos). Mientras que el gráfico izquierdo muestra los valores absolutos, el derecho muestra los valores una vez que aplicamos el ajuste en función de la posesión de sus equipos.
Pese a que algunos nombres se repiten, como es esperable, en el ranking ajustado vemos algunos sospechosos habituales que pese a ser defensores intensos y agresivos no aparecen en el izquierdo (o en menor medida) simplemente porque sus equipos dominan la posesión más tiempo.
Este ajuste es una solución práctica para estandarizar los valores de modo que se puedan comparar entre diferentes jugadores corrigiendo aspectos ajenos a su habilidad.
Sin embargo, es importante remarcar que una vez ajustada por posesión ya no existe una correspondencia verídica entre el valor de la métrica y las acciones reales que podamos ver en vídeo. Es por ello, que los números absolutos siguen teniendo utilidad a la hora de evaluar el rendimiento de los jugadores (por ejemplo, para definir los límites).
* Aclaración: Adaptando la terminología inglesa, al hablar de presión nos referimos a la acción individual. Por su parte, pressing se refiere a la tactica colectiva basada en acciones presión de manera coordinada por los miembros del equipo.
Lograr un fútbol igualitario es una prioridad para StatsBomb.
Como parte de nuestro proceso en pos de apoyar y acelerar el fútbol femenino a nivel global y como parte de nuestro compromiso de cara al Día Internacional de la Mujer, StatsBomb va a ofrecer acceso a nuestros datos de la Primera división de fútbol femenino en Francia de manera gratuita a todos los equipos de la liga.
En 2018, quisimos impulsar el estado del arte en el fútbol femenino y ofrecimos los datos líderes de la industria a una selección de ligas femeninas de forma gratuita. Además de ello, ofrecimos recursos de apoyo y asesoramiento para ayudar a impulsar la aplicación del análisis de datos en el fútbol femenino. Es emocionante ver a analistas, blogueros y aficionados crear análisis y visualizaciones de datos totalmente centrados en el fútbol femenino, especialmente cuando la especificación de datos detallada de StatsBomb proporciona una visión única en aspectos como el pie con el que se realizan los pases o la presión defensiva con un nivel de detalle que no está disponible para dominio público ni en el fútbol masculino.
Sin embargo, éramos conscientes de que podíamos hacer todavía más para derribar las barreras que todavía persisten y ayudar a los clubes a utilizar datos para mejorar su rendimiento.
Nuestros datos de calidad y nuestro conocimiento experto ayuda a ello evidentemente, sin embargo es preciso afrontar las limitaciones respecto a costes y experiencia con la que los clubes conviven. Así, en 2019, todos los clubes de la FAWSL que lo solicitaron obtuvieron acceso a nuestra plataforma de análisis profesional StatsBomb IQ. La gran mayoría de equipos aceptaron nuestra propuesta y han integrado el análisis de datos en sus procesos diarios tanto en análisis de rivales como en evaluación de sus propias jugadoras. Asimismo, hemos trabajado de manera muy estrecha con los clubes punteros en Inglaterra ofreciéndoles conocimiento experto en entrenamiento y análisis de datos.
Este año, nuestras ambiciones aumentan con la inclusión en otras ligas europeas, por lo que nos complace anunciar que ofreceremos datos GRATUITOS durante las temporadas 2019-20 y 2020-21 a todos los equipos de France Féminine. Esto incluye acceso completo a nuestra plataforma de análisis líder en la industria, StatsBomb IQ así como formación en el uso de la plataforma. La plataforma está diseñada para ser intuitiva, fácil de navegar y permite una visión práctica real. Tanto si se trata de comparar el rendimiento general del equipo en métricas clave, evaluar a jugadoras o revisar los partidos, StatsBomb IQ es una solución completa y única para su uso desde el terreno de juego hasta la dirección deportiva.
Con esta iniciativa durante las temporadas 2019-20 y 2020-21 y mediante la formación por parte de nuestros analistas expertos esperamos que los equipos de France Féminine puedan mejorar sus procesos pre y post partido. Continuando así con nuestras ambiciones de asegurar que el fútbol femenino no se quede atrás en la revolución de datos que se está produciendo en el fútbol masculino.
Nos complace anunciar un nuevo acuerdo de colaboración con la ACF Fiorentina centrado en el uso de datos en el scouting y análisi de juego.
Como parte del acuerdo, StatsBomb y la ACF Fiorentina organizan de manera conjunta la conferencia Big Data Innovations in Football que se llevará a a cabo en el Estadio Artemio Franchi de Florencia el jueves 26 de marzo.La conferencia contará con la presencia e intervenciones de analistas de StatsBomb y de la ACF Fiorentina, así como de otros clubes de fútbol de la Serie A y las principales ligas internacionales.
También contará con la participación de figuras relevantes en el sector de datos en el deporte y de medios de comunicación. El propósito del evento es compartir cómo los clubes están utilizando el análisis de datos en sus actividades de análisis y scouting.La conferencia se llevará a cabo de 9:00 a 17:00 CET, con un intermedio donde se ofrecerá un almuerzo.
El evento es gratuito y está dirigido principalmente a directores deportivos, analistas y scouts de clubes de la Serie A y B, así como a profesionales de la industria y medios de comunicación.El acceso al evento es exclusivamente bajo invitación.
Para más información y detalles sobre la inscripción a la conferencia* y el proceso de solicitud de invitación, por favor escriba a sales@statsbomb.com, especificando la naturaleza de su consulta. En el siguiente enlace puede ver un vídeo de una conferencia similar celebrada recientemente en Stamford Bridge (Londres): “StatsBomb 2019 UK innovation in Football Conference”
* StatsBomb se reserva el derecho de verificar cada registro.
Bienvenidos al comienzo de una serie de artículos en los que trataremos de explicar las nociones básicas del análisis de datos en el fútbol. Históricamente la mayoría de la investigación en este área ha sido en inglés, pero queremos contribuir a cambiar eso. Esto pretende ser un manual básico para entender las métricas que se están generalizando en el fútbol y previsiblemente serán parte del vocabulario estándar en pocos años.
Vamos a comenzar con el marco general empleado en la mayoría de análisis actuales: los Goles Esperados (xG).
Definición de los Goles Esperados (xG)
La probabilidad de que un tiro dado termine en gol.
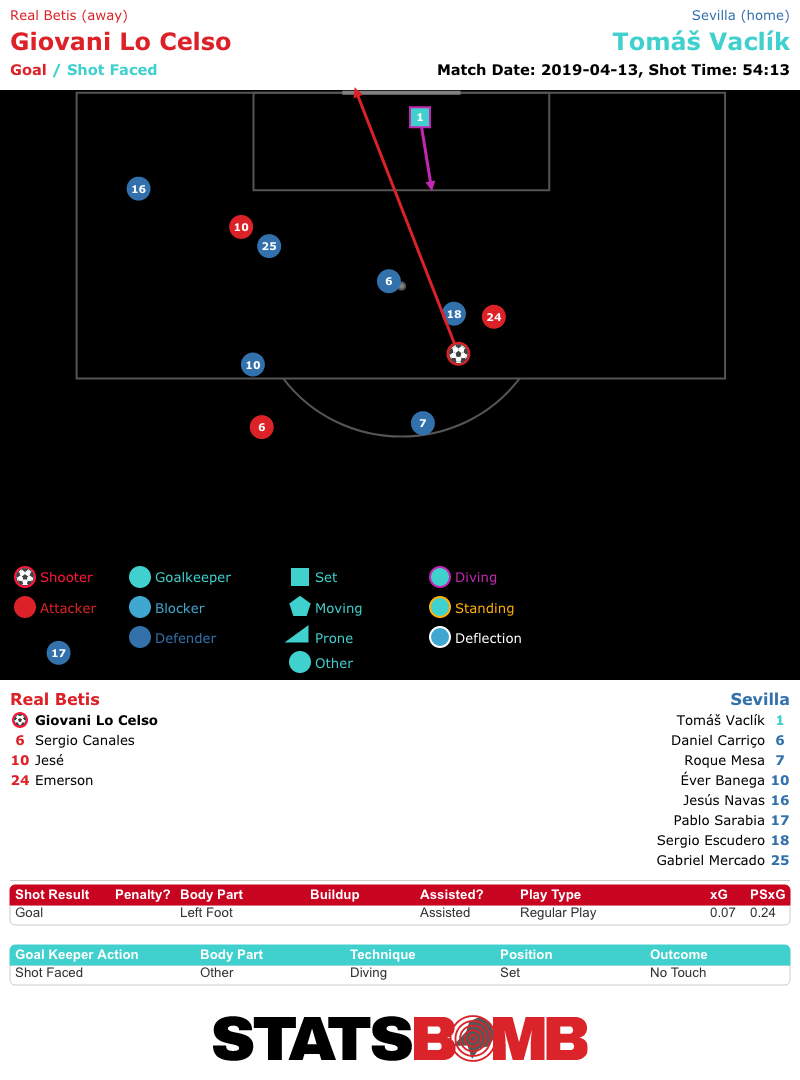
Vamos a tomar como ejemplo a un jugador que remata desde un lugar en el campo, queremos saber cuántas veces han sido gol los tiros desde esa posición y con características similares. O, un equipo ha generado una gran cantidad de ocasiones a lo largo de una serie de partidos pero ha marcado pocos goles, ¿el problema ha sido el acierto a puerta? ¿O simplemente las ocasiones no han sido de calidad?
Los modelos de Goles Esperados ofrecen un marco formal para dar respuesta a estas preguntas.
¿Por qué nos interesan los tiros?
Los goles son los sucesos más importantes en un partido puesto que determinan los ganadores y perdedores. Sin embargo, los goles son también uno de los eventos más infrecuentes en el fútbol. En las grandes ligas, el promedio se sitúa entre 2.5-3 goles por partido. Todo ello hace del fútbol el deporte más imprevisible y emocionante del mundo pero al mismo tiempo complica la tarea de analizarlo estadísticamente dado que el mejor equipo gana menos veces que en otros deportes.
Por poner un ejemplo opuesto, en la NBA es normal que ambos equipos anoten más de 90 puntos por partido generando muestra suficiente para analizar el rendimiento a través de los puntos. Sin embargo, no podemos hacer lo mismo en el fútbol cuando sólo tenemos dos o tres goles por partido puesto que la varianza es mayor. Esto hace del fútbol un deporte en el que la suerte tiene un papel significativo.
Sabemos que los goles vienen precedidos por tiros, puesto que para hacer gol es necesario rematar. Por tanto, podemos dar un paso atrás y fijarnos en los tiros. De repente, en vez de entre 2.5-3 eventos por partido, tenemos entre 25 y 30 - diez veces más.
Analizar los remates fue la base de algunos de los primeros análisis estadísticos en fútbol: Si el 10-11% de los tiros terminan en gol, la lógica nos dice que los equipos que disparan más que sus rivales deberían ganar un porcentaje mayor de partidos. Gente como Gabriel Desjardins, James Grayson, y Benjamin implementaron estas ideas desde el análisis del hockey y crearon la métrica Total Shots Ratio.
La métrica Total Shots Ratio es el ratio entre los tiros de un equipo y el total de tiros en un partido o una serie de partidos.
Total Shots Ratio (Equipo A) = Tiros a favor / (Tiros a favor + Tiros recibidos)
Vamos a ver un ejemplo concreto: En el partido Athletic Club-Real Sociedad de La Liga 2019-20, el equipo local remató 15 veces y el visitante 2 veces. Por tanto, el TSR del Athletic se calcularía de la siguiente manera: 15 / (15+2) = 0.88
Al tratarse de un ratio, la medida está acotada entre 0 y 1. En consecuencia, el TSR de la Real Sociedad se puede calcular del siguiente modo: 1 - TSR(Athletic) = 0.12
A lo largo de una serie de partidos, el Total Shots Ratio se demostró como un mejor predictor del ratio de goles de un equipo que el propio ratio de goles de ese mismo equipo. En su momento, esta medida fue útil y un paso en la dirección correcta. Sin embargo, tiene varios problemas intrínsecos en su planteamiento que podemos reducir a: no todos los tiros son iguales. Para superar estos problemas surgieron los modelos de Goles Esperados (o xG como acrónimo del término original Expected Goals).
Goles esperados: un paso adelante
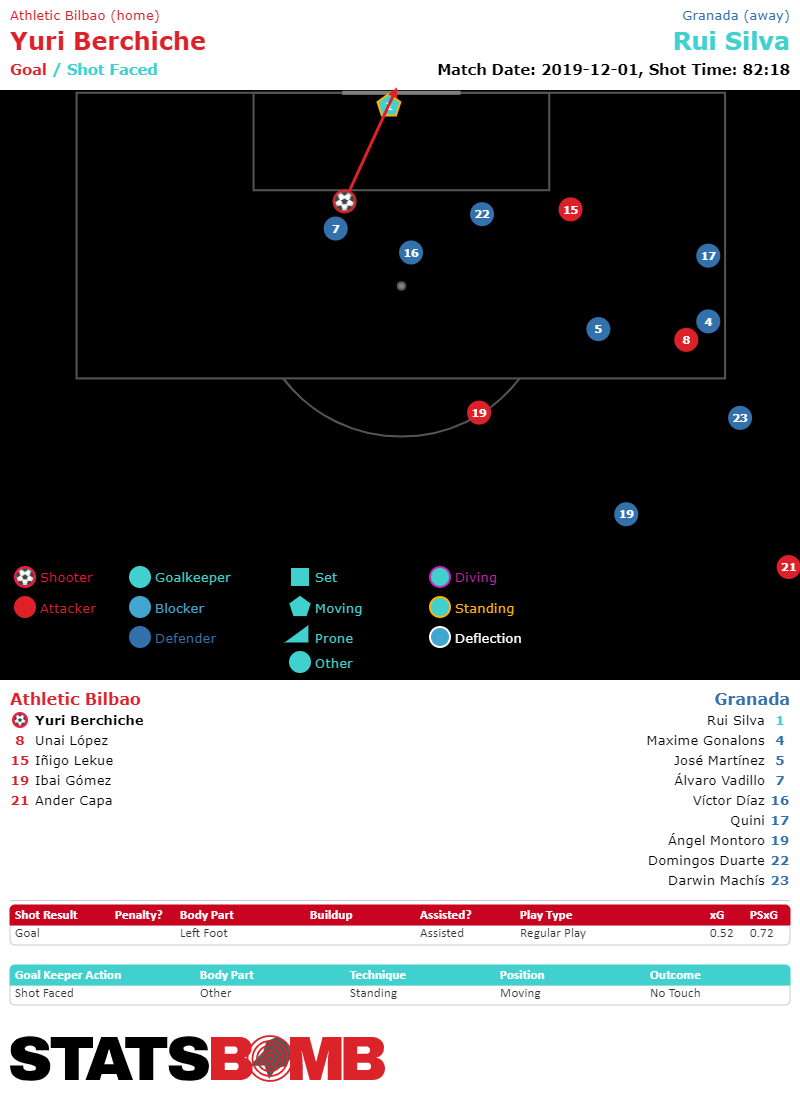
Como espectadores sabemos que un tiro desde dentro del área pequeña tiene mayor probabilidad de ser gol que uno desde 30 metros de distancia. ¿Pero cuánto más? Los modelos de Goles Esperados (xG) tratan de asignar un valor a esta diferencia.
¿Cómo se calcula el xG?
Los modelos de Goles Esperados emplean datos históricos para calcular la probabilidad de que un tiro dado sea gol en función de diferentes factores (distancia, ángulo, etc).
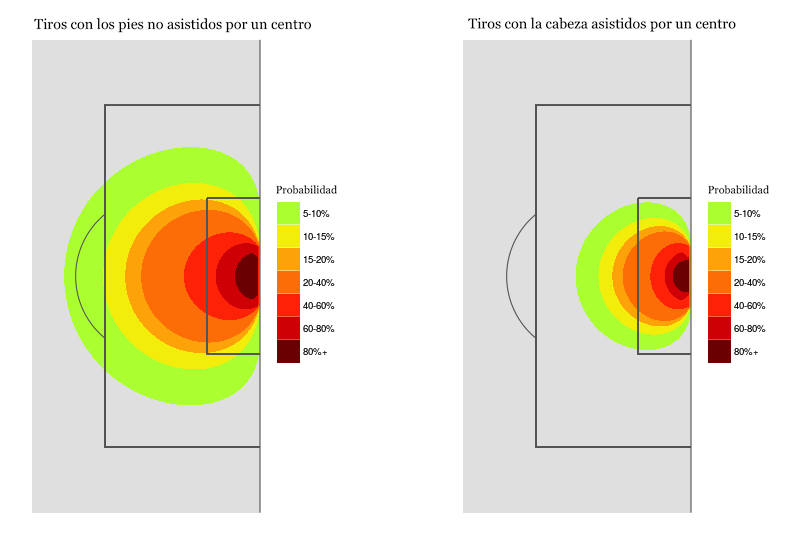
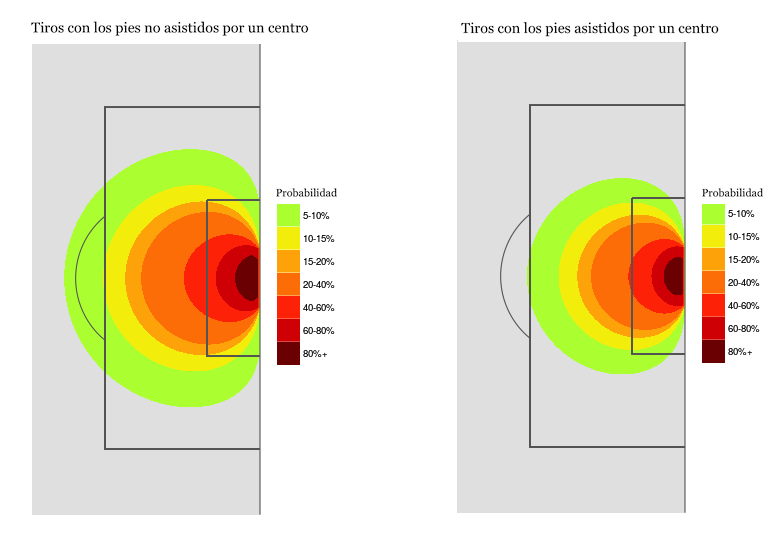
Aunque cada modelo tiene sus particularidades, históricamente estos son los factores más importantes para evaluar la calidad de un tiro:
Distancia a portería
Ángulo respecto a portería
Parte del cuerpo con la que se realiza el remate/tiro
Tipo de asistencia o acción previa (pase en profundidad, centro, balón parado, regate...)
Con esta información sobre un histórico suficientemente grande, el modelo atribuye a cada tiro un valor entre 0 y 1 que expresa la probabilidad de que termine en gol. Por ejemplo, observemos la siguiente imagen:
Un tiro desde este punto y con unas propiedades similares tiene un valor aproximado de 0.03 Goles Esperados (en adelante simplemente 0.03 xG). Esto significa que razonablemente podemos esperar que, de media, uno de cada 33 tiros sea gol en base a lo que ha sucedido con tiros similares anteriormente.
De estos modelos podemos aprender que:
Cuanto más cerca de la portería sea el tiro mayor es la probabilidad de marcar
Las zonas centrales son mejores que las zonas laterales del área (principalmente porque el ángulo es menor desde las zonas laterales)
Desde la misma distancia, los remates con los pies tienen mayor probabilidad de terminar en gol que los remates de cabeza
En general, los centros son más difíciles de convertir que los pases rasos, pases en profundidad, y los tiros tras regate
Para visualizar esto último:
Sin embargo, lo más importante no es tanto lo anterior, que hasta cierto punto es intuitivo, sino la capacidad de tener una manera sistemática de evaluar el valor de cada ocasión.
Por otro lado, de las investigaciones con modelos de xG aprendimos también que la posición y propiedades de un tiro son mucho más importantes que el jugador que lo realiza. Es cierto que con suficiente tamaño de muestra (años) o con modelos bayesianos podemos identificar algunos jugadores que destacan por su habilidad rematadora (Leo Messi) o por su falta de ella (Jesús Navas). Sin embargo, la inmensa mayoría de jugadores están alrededor del promedio. Así, en términos generales, lo que diferencia a los buenos delanteros no es la capacidad de convertir un mayor porcentaje de sus ocasiones sino la capacidad de generar más tiros desde zonas y situaciones valiosas.
A nivel colectivo, la correlación entre los Goles Esperados respecto al rendimiento futuro es mayor que el TSR o el propio rendimiento actual. Son útiles para evaluar el estilo y rendimiento tanto de equipos como de jugadores.
La variabilidad aleatoria en la conversión de ocasiones puede hacer que un equipo con un rendimiento subyacente notable parezca estar sufriendo una crisis (en palabras simples, mala suerte). Por contra, un equipo con una racha favorable de cara a gol puede situarse por encima de lo que su xG indica.
Este rendimiento subyacente, medido con un modelo de xG, unido a un concepto estadístico básico llamado regresión a la media nos permite hacer juicios y predicciones robustas sobre el rendimiento y potencial real de un equipo.
Un aspecto reseñable es que los diferentes modelos consideran una variedad de factores, sin embargo, no todos tienen en cuenta toda la información relevante para evaluar la calidad de los tiros. Es en este punto donde los datos y modelos de StatsBomb marcan una diferencia clave.
El xG de StatsBomb
En 2017, en StatsBomb decidimos que queríamos tener mejores datos para potenciar nuestros análisis y ayudar a los clubes a avanzar en el análisis. Estábamos seguros de que con más y mejor información podríamos mejorar los modelos existentes. Por ello, empezamos a recolectar nuestros propios datos.
Nuestros datos incluyen, entre otras cosas, los siguientes aspectos de manera explícita:
Posición del portero en cada remate
Colocación del portero: tumbado, movimiento, fijo
Posición de los defensores y de los atacantes en cada remate
Para cada tiro y remate, tenemos una imagen así:
Esta nueva perspectiva incorporando información adicional relativa a la situación del disparo, llamada Freeze Frame, ha mejorado mucho los resultados de nuestros modelos de Goles Esperados.
Pese a todo, somos conscientes de que no existe el modelo perfecto. No obstante, tenemos la certeza de que nuestros modelos son los más precisos y útiles que existen. La mejora constante es parte de nuestro ethos, por ello, hemos añadido la altura del balón en el momento del golpeo como factor adicional. Hemos visto que la adición de la coordenada z podría ha mejorado aún más la capacidad predictiva del modelo.
Ejemplo del xG: FC Barcelona 2017-18
¿Crees que puedes identificar un tiro convertido uno de cada dos veces? ¿Y uno convertido una de cada diez? Utilizando como ejemplo las ocasiones del Barcelona en la 17-18 vamos a intentar ilustrar diferentes conjuntos de tiros en función de su xG. Por simplicidad, excluimos los remates de cabeza.
Empezamos con el conjunto de tiros que terminan en gol menos de una vez de cada 20.
En segundo lugar, el conjunto de los tiros convertidos desde una vez de cada 20 hasta una de cada 10.
No hay muchas sorpresas hasta ahora. Los tiros de larga distancia no suelen ser gol. Sin embargo, podemos ver que los tiros desde ángulos ajustados también son habitualmente ineficientes. Los jugadores tienden a sobreestimar la facilidad de marcar desde estas zonas cuando en realidad existen pocos especialistas en marcar desde estas posiciones. Sergio Agüero es el ejemplo más llamativo.
En la siguiente imagen, vemos los tiros que terminan en gol entre una de cada diez veces y una de cada cinco. Como es esperable, estos tiros están cada vez más cerca de la portería y desde zonas centrales del área.
Cuando llegamos a los tiros que terminan en gol una de cada cuatro y una vez cada tres veces, las localizaciones se han centrado mucho y la mayoría están en el ancho del área pequeña.
Finalmente, los tiros que son gol al menos una de cada dos veces. No es fácil crear ocasiones de este tipo. Incluso el Barcelona, el equipo con mayor producción ofensiva esa temporada (99 goles), sólo creó 17 ocasiones con un xG tan alto. Esto nos ayuda a poner en perspectiva la dificultad de crear ocasiones tan claras y a generar unas expectativas realistas del rendimiento ofensivo de los equipos.
Aplicaciones prácticas de los Goles Esperados
La siguiente pregunta habitual es ¿qué podemos hacer con un modelo de Goles Esperados?
Dentro de un club, los datos pueden aportar un valor añadido tanto en el campo (por ejemplo, entrenamiento, táctica, acciones a balón parado) como fuera del mismo (por ejemplo, mercado de traspasos, negociación de contratos). Sin embargo, por la naturaleza y el estado actual del fútbol, los mayores margenes están todavía en las direcciones deportivas.
En lo relativo al mercado de traspasos, los modelos de xG tienen múltiples usos, desde hacer más eficientes los procesos de filtrado previo hasta permitir una valoración más precisa del rendimiento de los atacantes y predecir su rendimiento futuro.
Como ejemplo vamos a ver uno de los usos más prosaicos y al mismo tiempo más valiosos dentro de un departamento de scouting: Evitar decisiones erróneas identificando el rendimiento subyacente de los jugadores, más allá de producciones insostenibles o infladas por fluctuaciones aleatorias en la conversión.
La imagen inferior muestra el mapa de tiros de Enis Bardhi (Levante) en la temporada 2017-2018.
Bardhi marcó nueve goles esa temporada, pero nuestro modelo de Goles Esperados (2.78 xG) sugería que esa conversión era insostenible y que se debió probablemente a fluctuaciones aleatorias en su rendimiento. Metió 5 de las 16 faltas directas que tuvo esa temporada.
En la siguiente temporada, la 2018-2019, Bardhi generó incluso un número mayor de xG, pero sólo marcó tres goles, dentro de lo esperado por el modelo. Como curiosidad, esta temporada marcó sólo una de las 19 faltas directas que tuvo.
Si algún equipo hubiera fichado a Bardhi en el verano de 2018 esperando que fuera un jugador de 9-10 goles por temporada, las expectativas del rendimiento hubieran sido irreales y probablemente hubieran lamentado el fichaje.
Esto no implica que nunca vayamos a querer fichar a ese jugador, pero con un modelo de xG podemos hacernos expectativas más realistas del rendimiento que podemos esperar de Bardhi en el futuro y por tanto juzgar de manera más objetiva la idoneidad de su fichaje.
Para ver un ejemplo totalmente opuesto, en la imagen inferior podemos observar el mapa de tiros de Karim Benzema en la temporada 2017-2018. Durante esa temporada la opinión pública fue unánimemente crítica respecto al rendimiento del francés y no faltaron quienes sugirieron que su tiempo en el Real Madrid debía tocar a su fin.
Mientras que está fuera de toda duda que su rendimiento goleador fue decepcionante, la pregunta que nos debemos hacer es cuánto de esa producción se debió a fluctuaciones aleatorias en la conversión - o en otras palabras, mala suerte - y cuánto a un posible declive en sus habilidades futbolísticas.
Nuestro modelo de Goles Esperados nos da una pista al respecto, Benzema generó 9 xG pero sin embargo sólo logro convertir 3 goles (excluyendo penalties). Por tanto, el modelo nos sugería que Benzema tuvo mala suerte de cara a puerta. El siguiente mapa de tiros de Benzema es de la temporada inmediatemente siguiente (Liga 2018-2019).
Como se aprecia a simple vista, el rendimiento de Benzema esta temporada no sólo fue remarcable en la producción de ocasiones valiosas (12 xG) sino que además fue excelente en cuanto a conversión, metiendo 18 goles (más 3 penaltis).
Además, hay un aspecto reseñable que quiero mencionar: En los mapas de tiros se muestra el número total de ocasiones y goles a lo largo de una temporada, pero sabemos que no es lo mismo jugar 1500 minutos que hacerlo 3000. Por tanto, para una comparativa más precisa debemos controlar el tiempo de juego. ¿Qué ocurre cuándo ajustamos los números de Benzema por cada 90 minutos?
La temporada 17-18 Karim Benzema disputó 2251 minutos en liga y generó 9.22 xG. Con un calculo sencillo obtenemos que sus Goles Esperados cada 90 minutos esa temporada fueron 0.37 xG90.
La siguiente temporada, Benzema disputó 3086 minutos, generando 12 xG. Con el cálculo anterior obtenemos que sus Goles Esperados cada 90 minutos fueron 0.35 xG90.
Por tanto, Benzema no sólo no estaba en declive la temporada anterior sino que su rendimiento subyacente (en lo que respecta a generar ocasiones) fue prácticamente el mismo y simplemente la conversión y el tiempo de juego hicieron que su producción final fuera diferente de un año a otro.
El xG en la evaluación del rendimiento de los equipos
Los Goles Esperados también son válidos para en evaluar de manera adecuada la calidad subyacente de los equipos de una liga tanto a nivel de toma de decisiones como por razones financieras.
Vamos a examinar el caso del Alavés en la 2018-19. La gráfica inferior compara la Diferencia de Goles (verde) y la Diferencia de Goles Esperados (morado) del equipo vasco durante esa temporada, empleando la media móvil de diez partidos. El área verde representa sobrerendimiento de Goles respecto a Goles Esperados.
El Alavés estuvo clasificado entre los cincos primeros durante casi media temporada pero sus números de xG nunca fueron tan buenos como para estar en esas posiciones. Cuando los resultados empezaron a reflejar su rendimiento subyacente, el equipo cayó hasta el puesto 11º en el que finalizó la temporada.
¿Usar los xG en el entrenamiento?
En la dimensión del entrenamiento y el análisis táctico se puede utilizar el modelo para analizar decisiones tanto en ataque como en defensa. Por ejemplo, un entrenador podría visualizar la diferencia entre dos tiros y con esa información, ayudar a los jugadores a evaluar mejor las opciones disponibles. De nuevo, podemos ver la imagen que representa una ocasión con un valor de 0.03 xG:
Un tiro desde este lugar termina en gol una de cada 33 veces. En lugar de tirar, quizás puede ser mejor tratar de pasar en profundidad al desmarque del atacante:
Un pase exitoso similar en esta situación podría generar una oportunidad de remate con valor aproximado de 0.40 xG o más. Es decir, una ocasión 13 veces más valiosa que el tiro desde larga distancia. Incluso si el pase se completara sólo 1 de cada 10 veces, seguiría siendo una mejor opción.
P(pase) * P(gol) = 0.10 * 0.40 = 0.04 xG
Obviamente, existen factores relevantes que influyen en ello como la habilidad, el entrenamiento (el modelo no da respuesta a la pregunta de cómo entrenarlo), o estratégicos - relativos a teoría de juegos.
Finalmente, los Goles Esperados tienen utilidad también para los amantes del Fantasy Football para identificar jugadores que están generando tiros valiosos pero que no están marcando muchos goles. Esto le puede pasar a cualquier jugador y no significa que exista un problema grave. Como hemos dicho antes, lo más importante es generar suficiente cantidad de tiros valiosos.
En lo que respecta a los medios, los Goles Esperados son una herramienta interesante para los espectadores que consumen análisis más profundos que simplemente con goles y resultados.
Conclusión
Los modelos de Goles Esperados no son perfectos y por definición no pretenden explicar ni todo el rendimiento ni en todo momento. Existen equipos que rinden por encima de los Goles Esperados durante periodos largos. A veces existe un jugador como Messi:
Sin embargo, es la métrica más predictiva y robusta del rendimiento de equipos y jugadores que tenemos hoy en día. Los modelos de Goles Esperados dan una imagen más precisa del proceso que los propios resultados y como tal son una herramienta útil para analizar el rendimiento de equipos, jugadores y entrenadores y tomar decisiones de manera más acertada.