Author: Thom Lawrence

The chess matches of Quique Setién

Football is very much not a game of chess. The pieces rarely go where you tell them to, players don't die when they're tackled (Neymar aside), and when your worst player reaches the opposition touchline, they're not promoted into Lionel Messi. Except, apparently, if you're Quique Setién, who this week finds himself outside of his preparation, as the manager of Barcelona.
And as every Five Things You Need To Know About New Barcelona Manager Setién profile has told you, the Spaniard is an avid chess player (and apparently he also coached the Russian beach football team, because nobody does beaches like Russia). He talks proudly of the time he tested Kasparov in a simultaneous exhibition (where a grandmaster, like some intellectual octopus, will play a dozen or more players at once), and by all accounts has kept up the hobby until this day.
Of course, there's a somewhat sad history of figures in the world of football boasting of their chess prowess. Who can forget Nigel Short's David Brent vs David Brent-esque report of his game with Sol Campbell? The recently retired defender had stated that chess helps him think strategically, but responded to Short's 1. e4 with the almost childlike 1... a5 before being crushed.
More recently in 2018, Liverpool's Trent Alexander-Arnold - having talked of his many games on the team bus against teammate Ben Woodburn - found himself facing Magnus Carlsen, newly arrived in the UK to defend his World Championship title. Alexander-Arnold tried to unsettle the dominant Norwegian with the rarely-seen Pirc defense, or perhaps was just picking at random, because by the fourth move his knight was forced into a humiliating retreat back to its opening square. By move seven he'd blundered a bishop. Then a rook. Then, with his king stepping confidently into the centre, presaging the surging runs for Liverpool with which we've become so familiar, he was mated by a combination of Magnus's minor pieces. If you work in public relations for a celebrity who can't shut up about chess, let me give you this simple advice: learn the first five moves of the Ruy Lopez opening, then blunder to your heart's content. It'll at least look like you put up a fight.
As it happens, history has preserved a couple of Setién's games, who assuredly does know the Ruy Lopez, also known as the Spanish Game. So today we're going to analyze his play in depth, hoping to understand more of the mind that will be making Messi's moves for foreseeable future. In 1993, Setién was in his second spell as a player at Racing Santander. That year he traveled to the Benasque Open in the Pyrenees, where his game against Joan Gensana Berzunces (a regular on the Spanish tournament circuit who peaked at about 2068 Elo, perhaps roughly Isthmian League level) is available on ChessBase. Setién with the black pieces (i.e. playing away from home) faced the Exchange Variation of the Ruy Lopez:

After 5. Bxc6, this is an offer of an active, open game from the white (i.e. home) player, who gives black the bishop pair (with their diagonal runs, think of them as chess's wide forwards), in exchange for white having superior pawn structure (much like a Sean Dyche team). After capturing the bishop, white castles (sets up a three man wall in front of his keeper, the king) and Setién follows up with 5... f6 (a bit like an overlapping centre-back, weakening defensive cover by stepping up-field), a move favoured by US prodigy Bobby Fischer. Setién however played conservatively, and by move 10 his position felt claustrophobic. His bishops are stuck in the centre (with no access to the halfspaces), his rooks (chess's marauding full-backs) are stuck at the back:

Despite having been quoted as saying "chess and football are very similar. If you're controlling the centre of the board or the middle of the field, you've a high chance of winning the game", it is white in control of the centre here, with both its rooks in the middle (like inverted full-backs). But as the game progresses, Gensana Berzunces doesn't exploit Setién's vulnerable centre. In fact, the game turns when white attacks down the left flank after the position below, with 20. b4, instead of the sensible defensive 20. h3 (man-marking the winger on g4), allowing Setién to switch flanks and launch a powerful counter-attack with Nh4:

Soon Setién has committed most of his pieces to this attack, and under pressure, white makes a mistake in defence with 20. Rf2:

After 20... Nxf3, Setién has created an attacking overload: white's queen is threatened, but worse, white needs to scramble to cover its open goal, risking Rg1# mate. Unable to defend all of Setién's attacking options, white soon concedes. Perhaps more revealing of Setién's weaknesses is one of Setién's games from 2002, shortly after securing promotion for Racing Santander, this time as their manager. In a simultaneous exhibition given by then World Champion Vladimir Kramnik in Barcelona, Setién was again black and played the Two Knights Defence:

The game was incredibly cautious and slow to build up, and it wasn't until here with 19. axb5 that the game's first ground duel occurred. Just look at all black's pieces tucked away in their own half:

This attack down Setién's queen-side started to look quite threatening, however, drawing many of his pieces over to help defend ("the objective is to move the opponent, not the ball." — Pep Guardiola):

At this point, Kramnik sprang the trap and switched play to the other flank, with Setién unable to defend in transition:

From there, with Setién's defensive organisation in tatters, he soon conceded:

From these two games, we can draw some clear analogies with Setién's play style in football:
Slow, patient buildup
In 2018/2019, Real Betis had the highest average possession duration with 28.7 seconds beating out even Barcelona's 28.5. They had third shortest goalkeeper pass length, and led the league for their proportion of backwards passes at 10.2%, only slightly more cowardly than Athletic Bilbao and Real Sociedad. Expect no wild attacking gambits here.
Poor defensive transitions
Last season, Real Betis conceded more shots generated by a high press than any other side bar Levante. The flip side of the slow patient buildup is that when team's bait you into a trap, bad things happen.
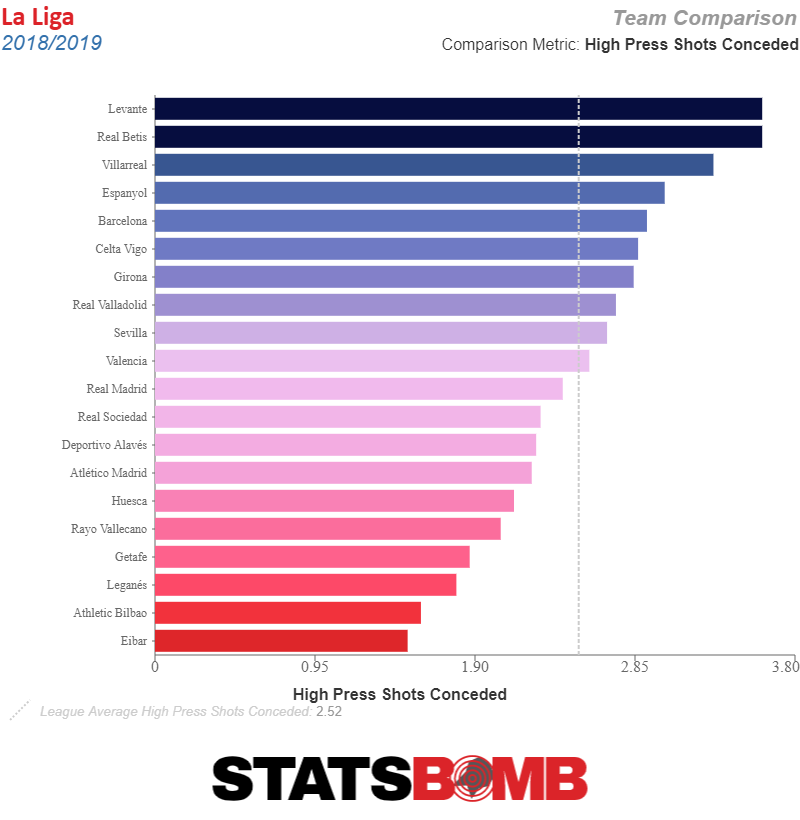
It remains to be seen how these aspects of Setién's game play out at one of the world's biggest clubs. His love of chess (like his talk of cows and his folksy surprise at the job in general) is unlikely to give him any extra credibility in a dressing room with some of the world's best football players. But there are many skills involved in the game of chess - some of them are pure, intuitive creativity, and perhaps that will help manage a genius like Messi. Others, however, are cold, hard calculation, and if there's one thing Barcelona need, with their aging stars and Champions League capitulations still fresh in mind, it's a dispassionate, unsentimental plan for the future.
Header image courtesy of the Press Association
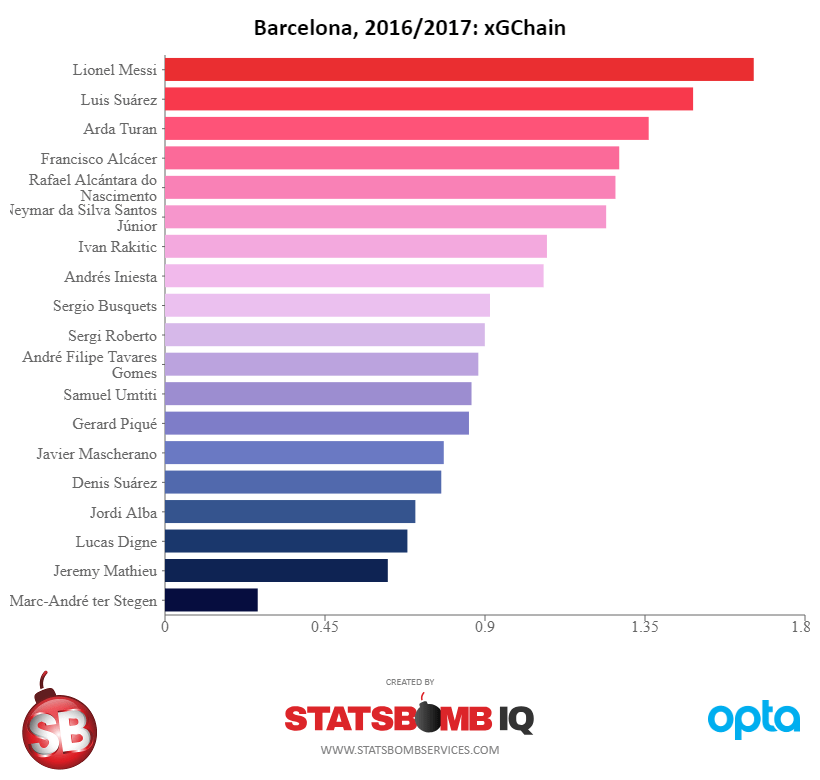
Introducing xGChain and xGBuildup
Everton 2017-18 Season Preview

Seventh
MISSION ACCOMPLISHED! The 2016/17 Best-of-The-Rest Cup has returned to its rightful home in the Goodison trophy cabinet. Tarnished somewhat by having been downgraded from 5th to 7th place, it's still a trophy, and we shouldn't begrudge Ronald Koeman providing an immediate return on his £7m-a-year salary. From around February we are better than evens to finish 7th, no higher, no lower, and never faced a real challenge to our septpremacy from Southampton under-performing in front of goal, nor from Bournemouth getting their first taste of England's top 10, nor even from West Brom, returning to the top half of the table for the first time since saying goodbye to one Romelu Lukaku (of whom more later, duh).
We also made progress on the stadium front, securing land at Bramley Moore Dock. I say 'land', obviously right now it's all underwater. In fact, I say 'securing', obviously we haven't raised the money to pay for any of it yet. But you wouldn't bet against our cadre of Russian money men, would you? Mayor Joe Anderson's inbox is probably already brimming with offers of dirt on his opponents for the 2020 elections.
We started the season with Lukaku still recuperating from that awkward holiday we've all had where your ex turns up to the same resort. Sources from within Belgium's Chateau du Haillan training camp claim that Lukaku and Robert Martinez could be heard attempting to stoke each other's jealousy well into the small hours of the morning, the former loudly praising Thierry Henry's tactical prowess, the latter bouncing on the bed complimenting Michi Batshuayi's finishing skill.
This meant that we started the season with a 3-4-3, the honed spearhead of Mirallas, Deulofeu and Barkley up top, James McCarthy on the right against Tottenham. In the first half, we took no shots after the 19th minute. In the second, we took none after the 79th. We won a point off a fluky Barkley free kick that found its way through to the far post. The 3-4-3 persisted against West Brom where we overturned an early set-piece goal to win 1-2. With Lukaku back in the team, and £25m man Yannick Bolasie a regular fixture, we mostly fielded a 4-2-3-1 with Barry and Gueye holding, Bolasie, Barkley and Mirallas ahead, or a 4-3-3 with Barry deepest and Gueye and Barkley in the headless chicken roles in the middle, Mirallas and Bolasie flanking Lukaku. The 3-4-3 returned against Chelsea in early November. Antonio Conte had laughed off suggestions he was facing the sack in late September, and by the time Everton made their visit to Stamford Bridge he was already 4 wins into the 13-game winning streak that would all but secure them the title. We took a single shot that day, and Conte would continue laughing for quite some time afterward.
At the half-way point of the season, the top 6 were already 9 points ahead of 7th, and while Everton had picked up a couple of creditable wins against Arsenal and away to Leicester, and grabbed a point off each Manchester side, it was only really a run of four wins against fairly easy opposition in August and September that was propping the season up. The football wasn't much to look at, we defended a bit better, showed a bit more energy when pressing, but it didn't feel as if we had any plan or systematic advantages in attack. We crossed a bit, and Lukaku found ways to score.
The fundamental issue we seem to have under Koeman is the disconnect between our build up and our attack. There's not a great deal of movement and interplay in the centre, so we're reliant on longer balls (especially out wide) to progress towards the goal. Gareth Barry (offered a new contract at 36, and apparently a target for Tony Pulis) has generally been the only midfielder who reliably can progress the ball in this way. The stat that stands out to me is this: Everton's passes into the final third were the 6th longest on average in the Premier League last season. Only Watford, Burnley, Palace, West Brom and Sunderland relied on longer passes to get the ball forward. I wouldn't mind this - gaining lots of ground quickly is great - but we're bottom half of the table for completing these passes. I haven't seen much in pre-season to show we've addressed these issues: I certainly like Ademola Lookman's movement more than most of our other attackers, and Klaassen has decent first touch, so perhaps we'll see this completion rate go up even if the plan doesn't change.
A minor tactical turning point in our season came in December when Bolasie suffered a long-term knee injury. Deulofeu was unable to replace him, and all that could be done for the poor lamb was to ship him off to Milan to assist more xG per 90 than any player 23-and-under in the big leagues, before forcing him to make a humiliating return to Barcelona. This meant the team, outside the reliable Baines and Coleman, had slightly less width to exploit. Morgan Schneiderlin arrived in January, by which time Tom Davies had broken into the team looking like a Viking chieftan's daughter disguised in a fake beard after her father forbade her from joining the raiding party, intent on proving her valour.
This is an entirely aesthetic metric, but you can see the change in our play by looking at the ratio of crosses to through balls. Before the New Year, we took around 27 crosses for every through ball we made, the 6th highest ratio (Arsenal take 4 crosses for every through ball, Swansea and Palace 60+, just for some context). After the New Year, though, we had the 6th lowest ratio: 14 crosses per through ball. In this period we still oscillated between the 4-3-3, 4-2-3-1 and 3-4-3 but I actually quite liked some of our play, harrying opponents' midfielders, occasionally producing nice combinations in the centre, and securing some memorable wins, not least the 4-0 against Man City. What we didn't manage to do was bring that final third entry pass length stat down. Tom Davies added a lot of energy and some penetrative passing to the team, Schneiderlin has some of Barry's long ball game, and finished the season with the highest xGBuildup per 90 of anyone in the team. But without Lukaku's 24 non-penalty goals from ~17xG on the end of all this, I'm unconvinced we systematically create enough danger to really compete at the top level of the EPL.
Let's talk Lukaku: he was better than we deserved when he arrived on loan, and he's been better than we deserved every season since. If he were on a great Everton team, he'd be rivaling Gary Lineker's numbers, but as it is we got to see an Everton player finish with 25 league goals in a season for the first time in more than 30 years. He stayed for promises of Champions League football, gave Koeman a chance, and leaves us with a profit of nearly £50m. His capture was possibly Roberto Martinez's singular achievement, both in convincing the player and the board to make it happen.
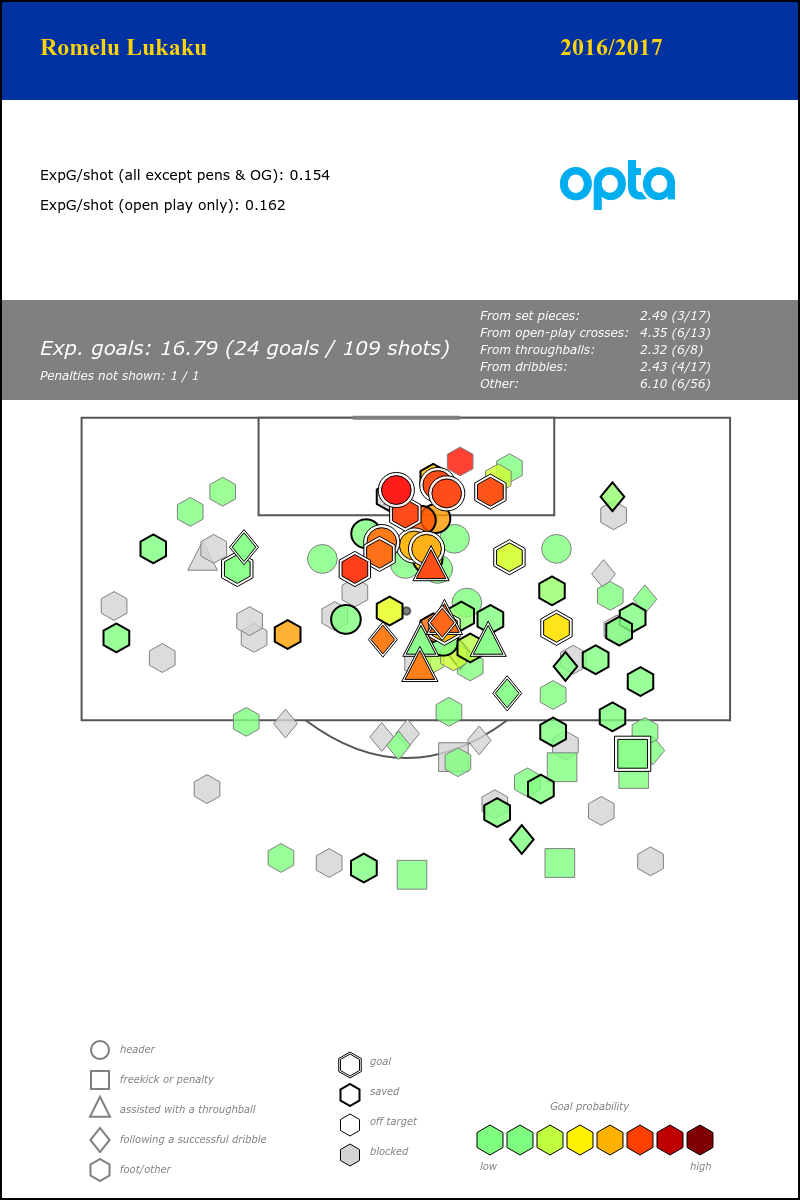
Strikers often struggle with perceptions. I always remember Lukaku's goal against Chelsea in the FA Cup, he points where he wants Barkley to put the ball, makes the run, looks up, looks up again, beats two players, shrugs off a foul, beats another two players with the tiniest of touches, and side-foots it past Courtois inside the far post. The commentators inevitably described him as "like a man-mountain there". It was a lovely goal, and it's true: his strength kept him on his feet despite one defender grabbing his shoulder and trying to haul him down. But I don't think Lukaku gets much credit for his vision and intelligence, and the amount of work he puts into his technical game off the field.
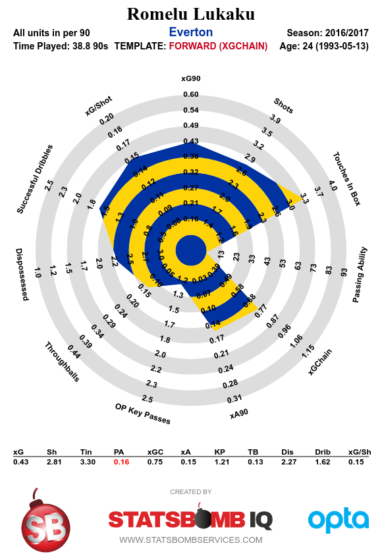
That all plays into the narrative that he's clumsy and has terrible first touch. We can investigate if this perception is actually fair with some simple stats: strikers receive passes in the final third, and we look at whether their next non-shot action is successful or not. So, they get the ball, and maybe pass, or dribble past a defender, whatever. Which strikers have a better or worse success rate with these actions? Looking at the last four seasons and limiting to players that have received a total of more than 500 passes in that time, Lukaku ranks 10th out of 26. He's above Diego Costa, Harry Kane, Alexis Sanchez, Luis Suarez, Olivier Giroud and plenty of others. He ranks worse for the eventual xGChain of those possessions, so perhaps he's not creating a ton of a danger in his hold-up play, but at the same time Everton rely so much on him to be on the end of moves that you'd expect less xG from possessions involving him in the buildup. Either way, I don't think he's as bad as people think, and besides, it's not our problem now. Go with love, Big Rom.
Seventher
Everything turns upon this simple equation:
Position2017 = 7th - Lukaku - European Campaign + The Genius of Steve Walsh
Are we a seventher team than last season? Are we more than seventh? Or without Lukaku's goals, and facing attrition from Europa League games, might we actually find ourselves south of Southampton this year? Our Summer business was ambitious in quantity, if not in quality. But even if we land Gylfi Sigurðsson for the price of 0.25 Neymars, I don't think we've made a single signing in the same league as the outgoing Lukaku (or the top 6's incoming Salah, Morata, Lacazette, Mendy etc etc). Maybe you'd stack our signings up against Tottenham's big pile of nothing, but over 24 months they seem like as good a team as any in the EPL and don't seem to expend any fucks on European competitions.
I haven't accounted for one additional factor in the complex scientific equation above: Charlie Reeves, a data analyst poached from Forest Green Rovers, indicating at the very least that Walshie wanted an up-to-date spreadsheet to start sorting. My only concern is that in this window, the flashing red light attached to his veto button has clearly malfunctioned. If there's budget for a replacement, future windows might make more sense to me.
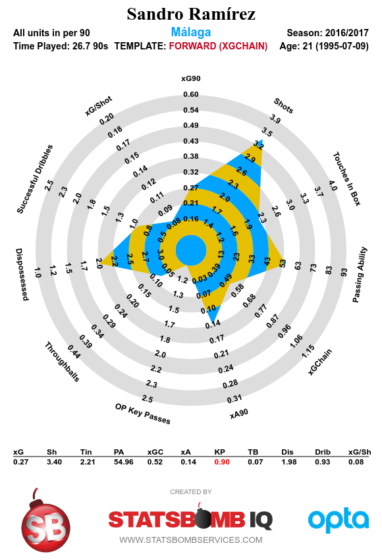
The biggest story of our Summer is of course the return of always a blue Wayne Rooney. He brings with him such a weight of narrative I don't know where to begin. When he left Everton, we immediately finished in the top 4. Now he's returned, does symmetry demand that we or Man Utd return to the top 4? The boy Rooney ended Arsenal's famous 49 match unbeaten run, could the man put us ahead of Arsenal, and end Wenger's tenure entirely? Storylines aside, Rooney is still a perfectly cromulent Premier League player, but he's more of a replacement for Ross Barkley than Romelu Lukaku. I don't believe that Rooney plus Sandro Ramirez (plus Sheffield lad Dominic Calvert-Lewin) equals anything approaching one Lukaku, but then again I don't really understand what Koeman's hoping for in attack.
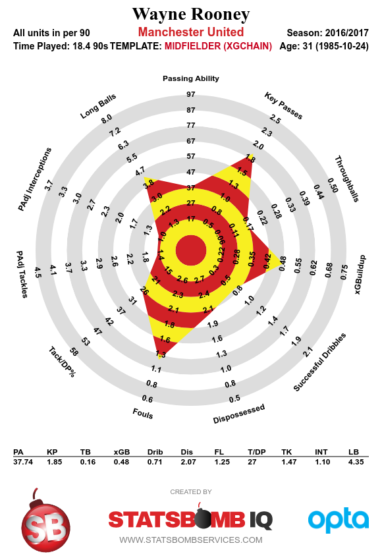
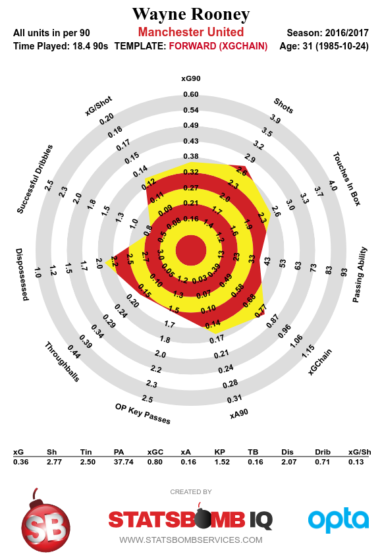
Elsewhere, Davy Klaassen joins our midfield, though I'm slightly suspicious of attackers coming from Eredivisie with anything but bonkers stats, which he does not possess. He certainly has tidy feet and quicker passing than we're used to, but I've seen little evidence of enough intelligent movement around him to really take advantage.
Since Neville Southall, it's never felt like Everton have had a truly generational keeper. Nigel Martyn's swan song and Tim Howard's often-unfairly maligned tenure brought some solidity, but could Jordan Pickford be Everton's number 1 in 5 or 10 years? I'll admit I didn't see him much last year, it was hard to watch Moyes's Sunderland, a bit like your dad going through a bad divorce and trying to get all his uni mates back together to for one last year-long binge. But his shot stopping numbers look fine from the small sample we have. As long as he doesn't fall out of his loft or get injured warming up he certainly seems like he has a better shot than most, if only because of the expectations of his price tag.
Michael Keane shaves some necessary years off our defence's average age. He's joining a very different back line to Burnley's, his numbers last year show very little pro-active play in terms of tackles and interceptions, but his aerials and blocks per shot were good. Our passing model quite likes him, and already in pre-season I've seen him sprint 40 yards through the middle of the pitch with the ball so it'll be a wild ride at the very least.
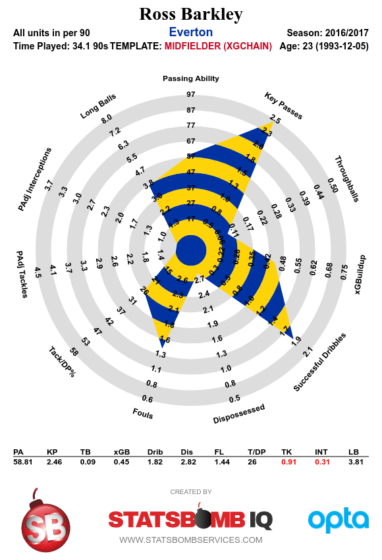
There's also the possibility that Ross Barkley leaves. I genuinely think he's progressed and taken up more responsibility, but there are always the suspicions that the gaps in his game are all things that can't be taught: decision making most of all. I'd always hoped that if we cashed him in, it'd be for John Stones money, but barring a bidding war those days are gone, as his contract winds down and his manager constantly criticises him in the press. If he moves, I hope he's turns out to be more Rooney than Rodwell - he always put in the effort, and came back from some horrible injuries early in his career. Who knows, maybe he'll make a dream return as our number 10 for the 2025/26 season.
Anyway, I've cranked all that through the supercomputer and it reckons... 7th.
Seventhest
So what's the long-term plan? We're behind the rest of the class and we're going to catch up to them by going slower than they are? Are we to sit poised in 7th, waiting for the Mad King Arsene Wenger to self-immolate? Hoping Mourinho and/or Chelsea have another 2015/16, that Pep truly is a fraud, that Pochettino's head is turned by a more generous sugar daddy and his Tottenham project is picked apart, that Raymond Verheijen will jump out with a police baton and assail the knees of the entire Liverpool squad?
We've spent, upped our wage bill, and signed solid players to accommodate Europe. I feel grumpy saying this, but it's all probably fine. It's entirely possible that Koeman's targets from the board do ultimately include the top 4, maybe he even thinks we have a shot this season. Our last mad dash for the Champions League was Martinez's series of loan gambles, and hell, we had a bunch of luck and very nearly got there, before it then immediately fell to pieces. But I see no hope of replicating that in the next couple of years. It wasn't so long ago that you'd interpret any sort of £50m bid as a sign of ambition, but in Premier League terms who knows what it now represents, especially taking into account our new and deeper pockets.
I'm not a huge fan of what's happening on the field, and I don't think we're getting value in the transfer market. But look at the next 5 years as a slow, iterative process: secure 7th, not a bad spot in such a competitive league. Try to become a fixture in the later stages of the Europa League. Between that and the stadium, slowly increase our reputation and make us more attractive to transfer targets and commercial partners. Build out the back office, chuck in a few analytics people. Keep developing and playing the youth, who are already a big part of their respective England setups.
There are worse ways to run a club, and let's face it, we've witnessed most of them in the last 30 years. Nil satis nisi septimum.
Everton 2016-17 Season Preview

The Past
Once Everton has touched you, nothing will be the same. Nothing, of course, except the reliable engine of hope and disappointment that has driven us backwards, forwards, sideways, and finally backwards again since the 80s. I should be more excited about this season: Roberto Martinez is gone! His style of football flew too close to the sun, and his wings (phenomenal, world-class wings) turned out to be held together by mere bullshit. We have our billionaire! No more mortgaging our future, selling our stars, lowering our ambitions...
I miss Moyes. I was brought up in the post-Kendall era of relegation battles and dodgy loans - I miss being the best of the rest. We're in a league now in which at least one of Guardiola, Conte, Mourinho, Wenger, Klopp or Pochettino have the fight of their lives to scrape anything better than 6th. When Moyes left on his three-year mission to flush his reputation far enough down the toilet that it could stick to Aston Villa or Sunderland, we had options. Ralf Rangnick was right there, in the room, being interviewed. No manager available to us at that time could have better embodied the school of soccer science, and given us a tactical head start in a post Tiki-Taka world. Instead we hired the guy that got relegated but twatted us in the cup. For a brief time memories of Moyes kept our defence from collapsing, before we faded into a bottom-half team, a patchy, wilting Christmas tree with some inexplicably shiny baubles.
How ambitious we were to reject £40m for Stones! Only twelve months before, we had missed the Champions League by a whisker! It's time to end the hubris. We never matched Moyes' on-pitch solidity with a reliable, long-term, financially secure plan off it. Now our billionaire has arrived, it seems too late to really differentiate ourselves, in a world with vast TV money and so many competitive teams. But I'm reassured by the fact that we haven't immediately had a Robinho moment - it implies we're willing to actually put in the proper work.
The Management
And so it is that we welcome Ronald Koeman to the helm. The Dutch Moyes is probably exactly what we need. At the very least, his appearances in post-friendly interviews have been hugely refreshing - a spade is once more a spade, and not a phenomenal, world-class ground-penetrating system. Two things mystify me, though: one that he was our first and only managerial target (if you take that claim at face value) and two that we have thrown enormous amounts of money at him between his contract and the compensation to Southampton. If we were willing to throw money around, why not a more ambitious choice? Why not offer someone like Roger Schmidt silly money?
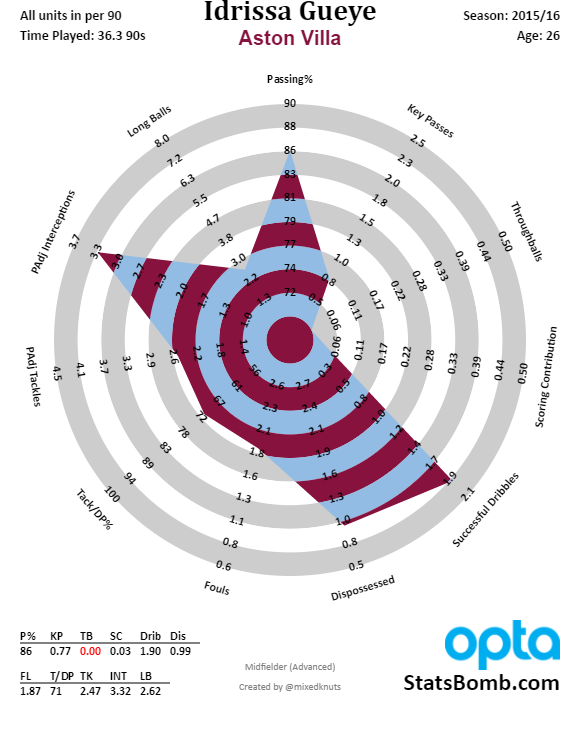
Elsewhere in the org chart, the arrival of Steve Walsh as Director of Football may signal a more long-term approach to recruitment. Whether or not he was the man who single-handedly sniffed out Riyad Mahrez, or who personally sorted the spreadsheet by tackles per game to find N'Golo Kanté, he's at least another grown-up in the room if a manager ever embarks on another passion project like Oumar Niasse. Previous Leicester target Idrissa Gueye has since arrived to patch the holes in our midfield, so that at least implies Walsh has smuggled out a USB drive with the "TOP SECRET ANALYTICS.xlsx" file that won Leicester the title last season.
When Martinez arrived, much was made of his attempts to remodel the club from top to bottom, to ensure the same style of play was being taught at every level (which presumably means nobody has practiced a set piece at the club for three years). You have to then wonder just how much disruption is caused by an outgoing manager with such a singular vision. Despite the fancy DoF title, Walsh's background is as a scout, it seems unlikely that he is directing our football or training ground operations to any great degree. Given that he's probably not giving the club much continuity above and beyond our current manager, why not just call him Head Scout?
The Money
Never before has it been so easy to call yourself a billionaire in the EPL. The TV money can basically pay for everything now, and if not, we're probably clearing £100m for Stones and Lukaku. If Farhad Moshiri, deep in his heart, never intends to give Everton any more money than his initial investment, it will be a very long time before anyone notices. So I would suggest we don't get ahead of ourselves and make any assumptions about our new status. Maybe the stadium talks will move forward, and maybe future windows will feature splashier forays into the market, but I'd much rather the club quietly upgrade our infrastructure (perhaps buying some of it back from the council would be a start) and plan for the future. Either way, in Moshiri we appear to have a sensible, unemotional driver at the wheel (or at least taking up 49.9% of the car and telling the driver where to go, you know how metaphors work), and billions or not, he seems to want his money spent sensibly. It's entirely possible that 21st Club's involvement during the takeover will result in better, more objective decision making throughout the club at some point in the future.
The Squad
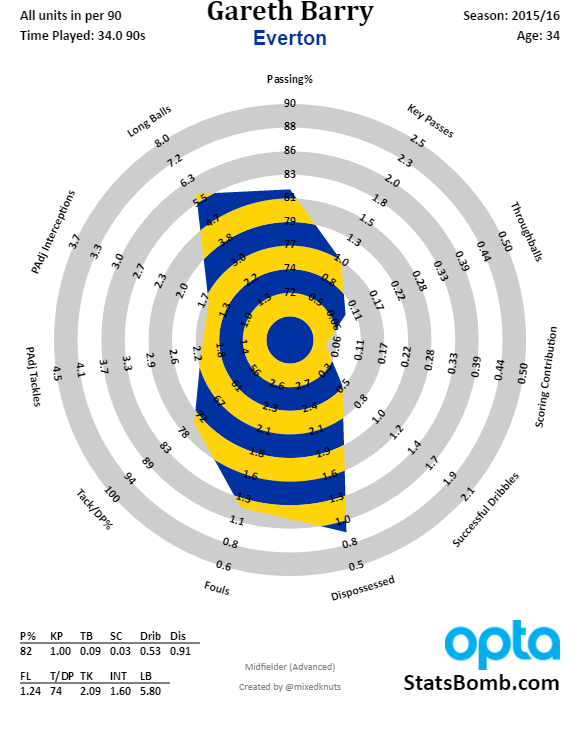
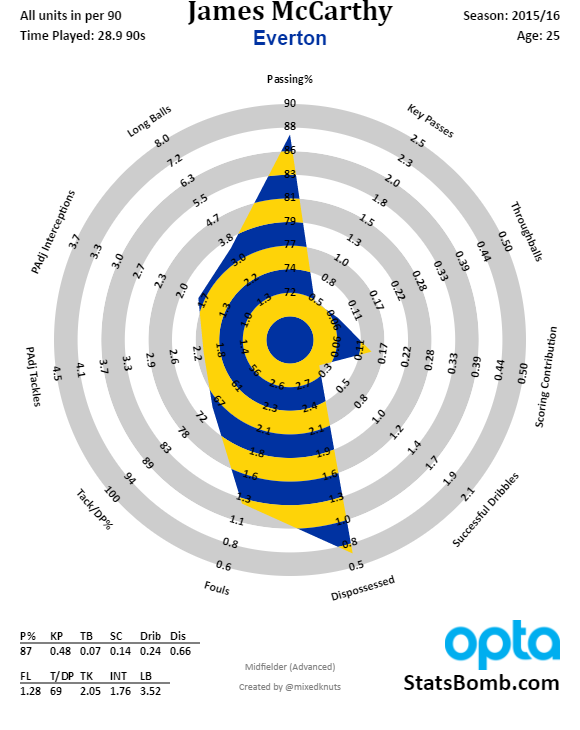
Everton have huge problems in the middle. Our defence has been bad, and has had no protection from central midfield. Gareth Barry moved the ball forwards nicely enough, but the weight of his enormous contract on those aging legs made him a liability going the other way. James McCarthy doesn't have much more defensive output than Barry, and very little of his passing. Idrissa Gueye comes into the team having made as many interceptions per 90 (possession adjusted) as McCarthy and Barry combined (3.32 versus 1.76 + 1.60), but will he single-handedly stop the succession of high-quality shots making it through to our goal?
With Stones likely to leave close to the opening day of the season (with the possibility of the error-prone Ashley Williams replacing him), and no rumours of a true goalkeeping upgrade, the entire pipeline from our midfield to our goal seems shaky, and even if you lay all of the blame with Martinez's system (which you should not), there hasn't been a huge amount of time to drill the team. Pre-season games haven't played out so differently from the Martinez-era - exciting attacking football, but too easy to penetrate at the other end, and still utter chaos when the ball is in the air.
In the game of 'Whose Knees Give Way First?' it appears that Mo Besic has been outlasted by Darron Gibson. It's shame that it looks like we'll never get a full season out of the Bosnian try-hard, he adds a slightly different, more direct dimension to our passing which certainly felt missing in monotonic system of the past couple of seasons. The same is true of Gibson's style, somehow earning him a two-year contract extension despite spending part of last year shoeless, on the sauce, and mowing down cyclists in his Nissan Skyline. It certainly seems that we have no long-term succession plan for Gareth Barry. Look at the average gain towards to opposition goal that our players made last year:
| Player | Average Gain |
|---|---|
| Joel Robles | 22.15 |
| Tim Howard | 20.28 |
| Jonjoe Kenny | 8.92 |
| Callum Connolly | 6.0 |
| John Stones | 5.76 |
| Phil Jagielka | 4.97 |
| Matthew Pennington | 4.8 |
| Ramiro Funes Mori | 4.65 |
| Seamus Coleman | 3.86 |
| Gerard Deulofeu | 3.65 |
| Leighton Baines | 3.18 |
| Bryan Oviedo | 2.97 |
| Gareth Barry | 2.85 |
| Kieran Dowell | 2.16 |
| Darron Gibson | 1.75 |
| Tyias Browning | 1.63 |
| Steven Pienaar | 0.75 |
| Aaron Lennon | 0.58 |
| Brendan Galloway | 0.43 |
| Muhamed Besic | 0.37 |
| Tony Hibbert | -0.04 |
| James McCarthy | -0.55 |
| Tom Cleverley | -0.65 |
| Tom Davies | -1.0 |
| Ross Barkley | -1.06 |
| Kevin Mirallas | -1.79 |
| Oumar Niasse | -1.88 |
| Arouna Koné | -2.12 |
| Steven Naismith | -2.66 |
| Romelu Lukaku | -3.22 |
| Leon Osman | -3.33 |
Compare Barry to McCarthy and Barkley to Deulofeu - outside of build up from the back, we don't have too many adventurous players, and Besic and Gibson only just manage to average a positive score. It's not all bad news going forward though. While we awaited Romelu Lukaku's return from the Euros, Koeman opted for Deulofeu through the middle in pre-season, and he looked bright and dangerous. Here's how he looked last year:
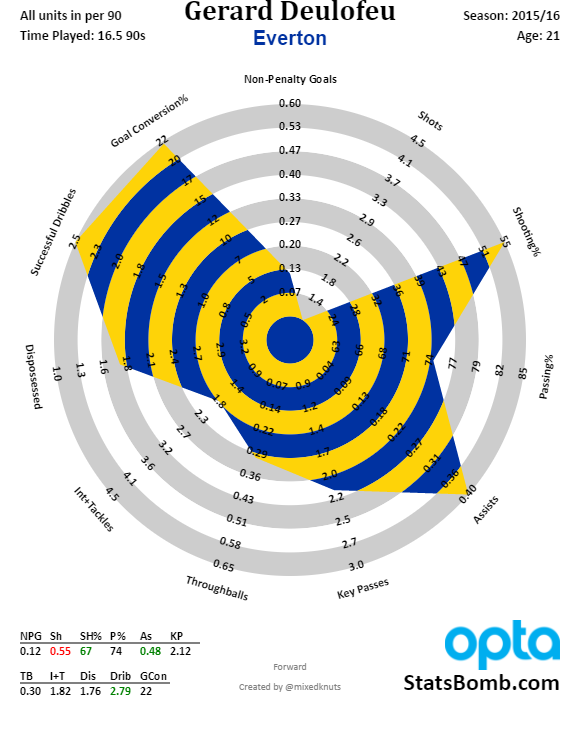
I do not know what physical or psychological flaws the boy has that cause him to be benched by Christmas each year, but I genuinely believe he's the only truly magical player that we have. As much as Aaron Lennon proved productive last year, his main achievement was to steal minutes from the player who perhaps needed them most. While his shot numbers as a winger last year weren't great (basically a shot every other game), his assists per 90 were second only to Özil: 0.42 to the German platter-server's 0.45, albeit from radically different xA numbers. Deulofeu struck gold from his 0.33 xA per 90, Arsenal's conversion rate almost halved Özil's expected assist total of 0.7 per 90. That's worth keeping an eye on, but either way his overall scoring therefore adds up to basically the same as Lukaku's (0.55 to 0.58). Obviously that's a testament to the partnership as much as anything, but Deulofeu has combined well with Mirallas up front in pre-season. I hope we see much more of him this season, wherever on the pitch he ends up. It would be a tragedy if he suffered the same fate as Dusan Tadic at Southampton, who Koeman often seemed reluctant to field despite his talent.
If Lukaku's rumoured return to Chelsea goes ahead, we'll be losing the most reliable goal-scorer Everton have seen for decades. I don't truly know what style of football would suit the still-young Belgian, but it never felt we were particularly built around him, if only because it might have occurred to another team to stop making him look so clumsy with his back to goal. If he leaves we'll certainly miss his raw output, but I don't believe he's tactically irreplaceable, especially in an attack built around Deulofeu, if such a thing is possible.
And finally we have Ross Barkley. Did he make The Leap, or did he stumble again? Certainly, the same old habits held firm: the runs that went nowhere; the complete lack of recovery running; the terrible decisions. But he began to show some sings of actual output last season, ending with 0.33 NPGA90. I would accept anything approaching Stones-level money for him in a heartbeat, but it's entirely possible that slowly but surely he could one day, with the right training, stop being the most infuriating player on the team.
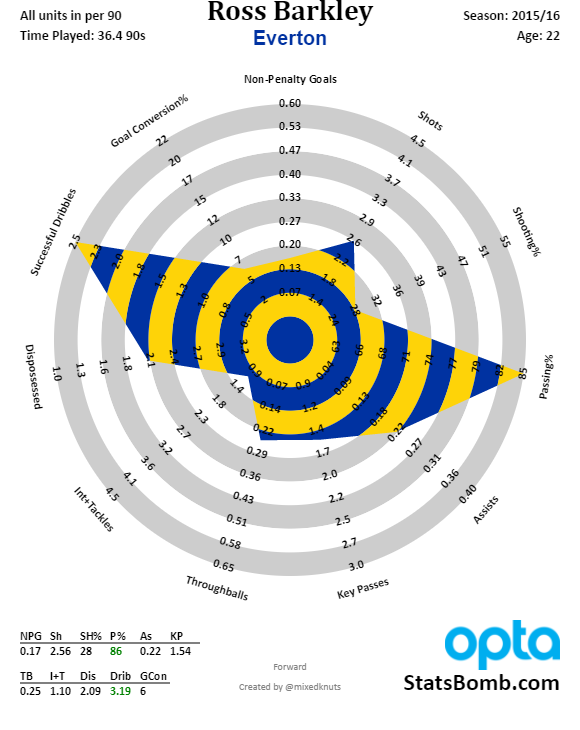
The Future
As grumpy as all this undoubtedly sounds, Everton are today in the best shape they've been since my family moved to Winsford in 1987 and I looked at the nearest clubs in the league table, pointed, and said 'that one'. Koeman isn't the most exciting possible appointment, but he's fine. We haven't gone out and made a statement in the transfer market, but too often that statement just ends up being "we're idiots with no sense and lots of money" anyway. It is hard to accept that there is no short term plan to transform this squad into a Top 4 one, but right now we just need to prove that it's a top half one, and build a future from there.
Of course if by the first day of the season we've spent £200m and all this is rubbish, then I'm well up for that too. ___________________
Enjoy this? find out other season previews here